Audio-Driven Video Generation | Wan2.2-S2V

詳細
ファイルをダウンロード
モデル説明
まず試してみて、満足できなければインストールしないでください。
https://www.runninghub.ai/post/1961049452163305473?inviteCode=rh-v1213
私の招待コード(rh-v1213)を使用すると、1000ポイントがもらえます。
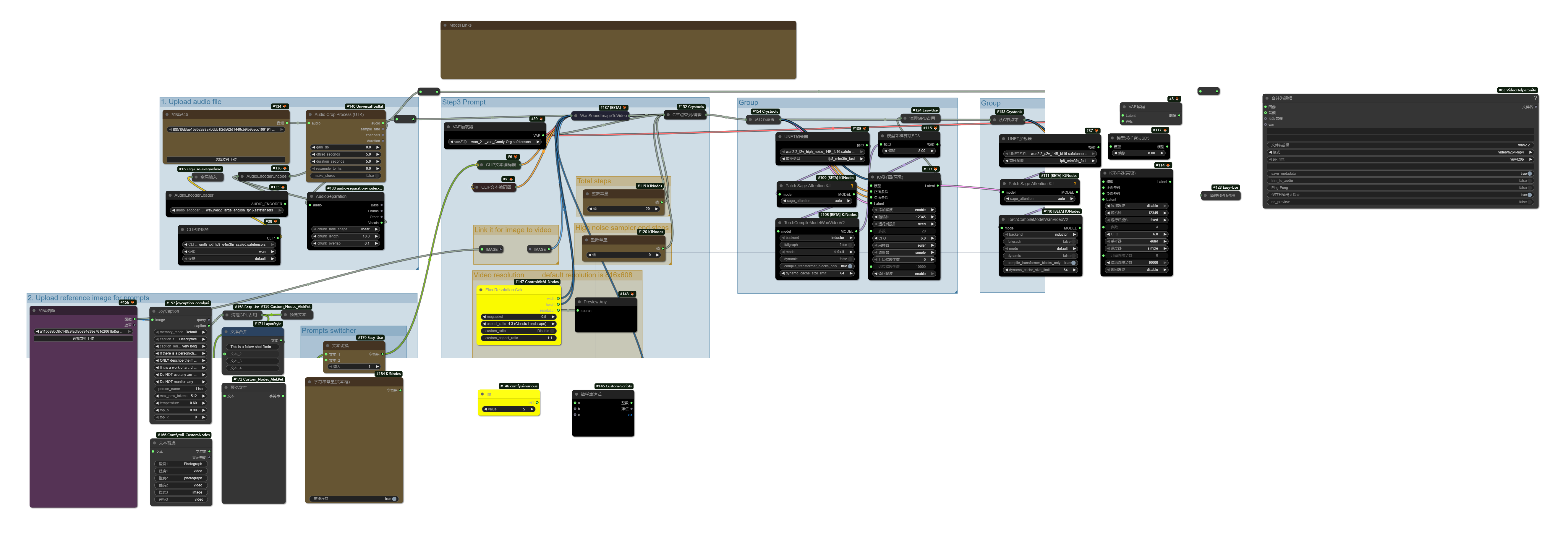
音声ファイルをアップロードし、長さを設定してください。
プロンプトを入力してください。
関連するモデルは Civitai.com で見つけることができます。
[wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors]
[wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors]
[wan_2.1_vae.safetensors]
Wan2.2-S2Vは、静止画像と音声入力を動画コンテンツに変換できるAI動画生成モデルです。このモデルは、単一の生成で最大1分間の動画を生成でき、デジタル人間のライブ配信、映画制作、教育業界における動画作成に新たな解決策を提供します。
このモデルは映像・テレビ用途で優れた性能を発揮し、顔の表情、体の動き、カメラの言語を生成できます。全身と半身のキャラクター生成をサポートし、会話、歌唱、パフォーマンスなどさまざまなコンテンツ作成ニーズに対応します。
このモデルで生成された画像
画像が見つかりません。