Qwen-image-edit nf4 workflow (4-8steps, 16GB VRAM compatible)

詳細
ファイルをダウンロード
モデル説明
このワークフローは、最新の bnb 4-bit モデル読み込みプラグインを使用して、bnb nf4 形式で量子化された Qwen-Image モデルを読み込みます。
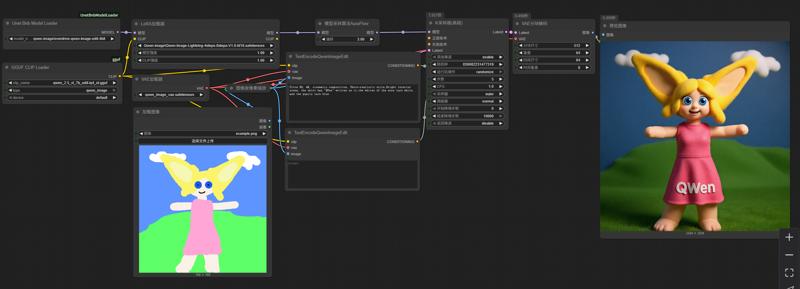
不足しているプラグインは、ComfyUI Manager のプラグイン管理システムから直接インストールするか、「Unet Bnb Model Loader」と検索してインストールできます。もちろん、手動でインストールすることも可能です。
使用モデル: https://huggingface.co/ovedrive/qwen-image-edit-4bit
このモデルはシャーデッドモデルですが、シャードを手動で統合する必要はありません。単に qwen-image-edit-4bit のようなディレクトリにすべてのシャードを配置し、そのディレクトリを UNet ディレクトリに置くだけで済みます。プラグインがシャーデッドモデルを認識して読み込みます。ドロップダウンメニューでは、シャーデッドモデルは配置されているディレクトリ名に基づいて表示されます。
以下の LoRa 加速生成を使用してください: PJMixers-Images/lightx2v_Qwen-Image-Lightning-4step-8step-Merge · Hugging Face
以下の text_encoder を使用してください(GGUF プラグインが必要です): https://huggingface.co/calcuis/pig-encoder/resolve/main/qwen_2.5_vl_7b_edit-iq4_nl.gguf?download=true
Qwen-Image-Edit の text_encoder として、Pig が提供する qwen_2.5_vl_7b_edit シリーズの GGUF ファイルの使用を強く推奨します。これにより、mmproj モデルが text encoder に正しく組み込まれ、一般的な GGUF CLIP ローダーがテンソル不一致の問題なく正常に読み込むことができます。それ以外の場合は、より大きな fp8 モデルを使用する必要があります。
このワークフローでの画像生成速度は、GGUF モデルを使用する場合の約2倍で、結果は GGUF Q4 と同程度です。ピークメモリ使用量は約14GBですが、画像を繰り返し生成する際は約14GBに維持できます。
画像生成速度は約1 it/s で、推奨ステップ数は5〜6です。このワークフローは BitsAndBytes ライブラリに依存しているため、NVIDIA グラフィックカード以外ではサポートされません。