WAN2.2 img2vid NSFW basic workflow


詳細
ファイルをダウンロード (1)
モデル説明
I have been getting lots of messages asking what I use for my animations, so I am posting it here. If you are already using WAN2.2 locally, this likely won't add anything for you.
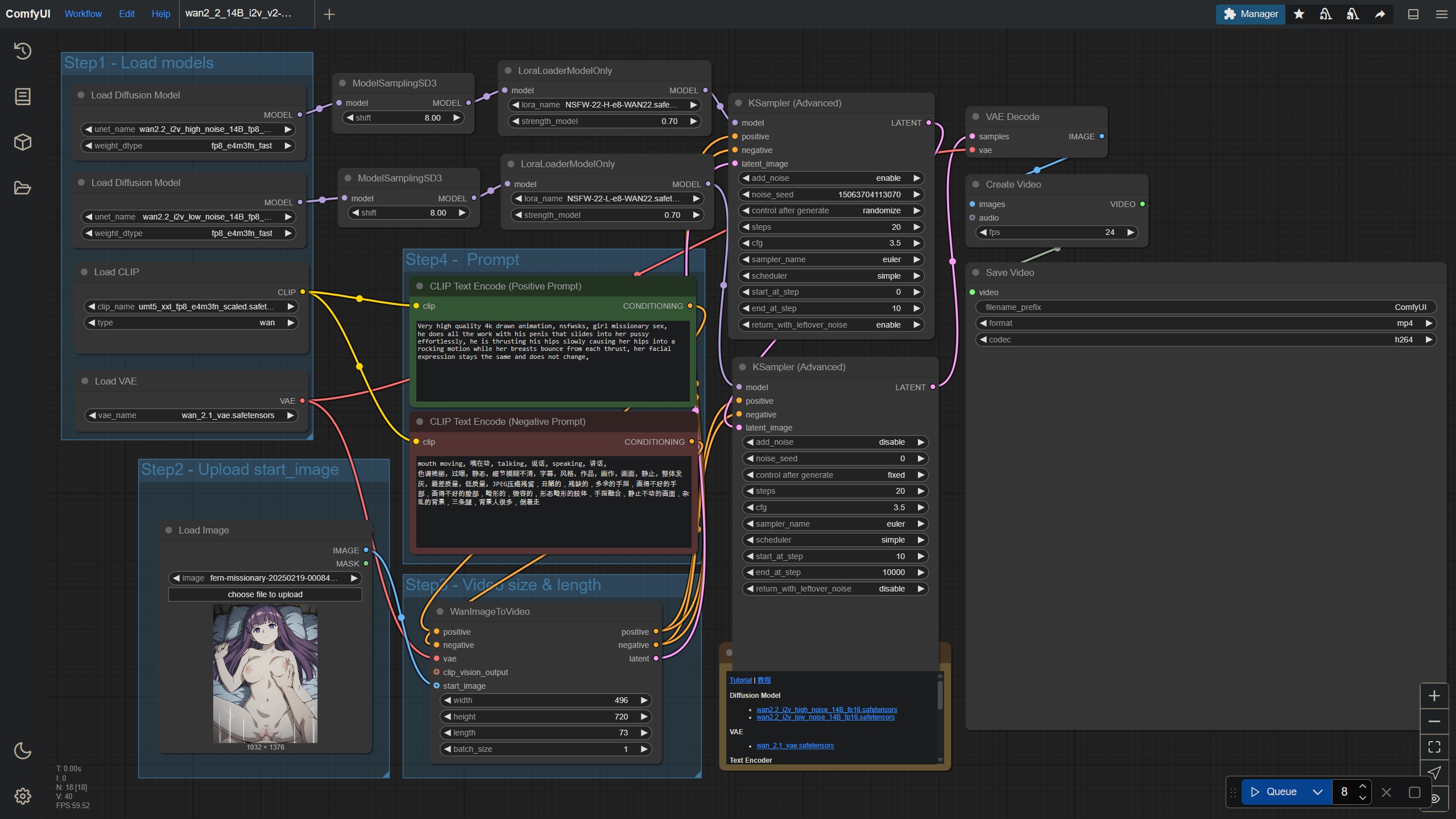
This is an extremely basic workflow that literally just uses the exact workflow from https://stable-diffusion-art.com/wan-2-2-image-to-video/ and adds the high+low loras from https://civitai.com/models/1307155/wan-22-experimental-wan-general-nsfw-model. A few minor things were tweaked for my preferences like steps and dimensions, but nothing else was changed for nodes and stuff - you'll get similar results just by following the guide and adding the lora yourself. The prompts are based on the recommendations on that lora page - check it out to see how to prompt for other positions. I think you need a relatively new version of ComfyUI from August 2025 or later since I had to update mine when setting up WAN2.2.
I generate static images using https://civitai.com/models/827184/wai-nsfw-illustrious-sdxl?modelVersionId=1761560 and then feed them into WAN2.2 to animate them. After loading the workflow, I just select the image and maybe tweak the prompt and video dimensions a little, and just generate batches of 8 videos for each image and pick the good generations out of each batch. To loop the videos, I use my WSL2 Ubuntu installation to run a Linux bash script that Chat GPT wrote.
I use a RTX 4090, so this workflow may not work for you if you have a GPU with lower VRAM. Generating one video takes me a little over 7 minutes with the dimensions I set.
I am no AI expert and don't know how to use ComfyUI outside of how to load a workflow and add loras, so I can't help you with any problems. I just like generating AI anime porn and learned the bare minimum to get things working.