Max quality QWEN Edit 2509 outputs, minimal workflow, and lots of info



詳細
ファイルをダウンロード
このバージョンについて
モデル説明
重要:
ここに初めて来た場合は、qwedit_simpleワークフローから始めてください。 単一画像のワークフローの使い方が分かってから、複数画像のものを使用してください。
更新情報
このセクションではバージョン更新を追跡します。メイン投稿はこの更新セクションの直下にあります。まだメイン投稿は更新していません—新しい情報は現時点でこの更新セクションにあります。
更新 2025-10-14: 複数画像ワークフロー
元の投稿はこの下にあります。2画像用と3画像用の新しいワークフローを追加しました。最適な実装方法を考案するのに時間がかかり、また先週は現実世界で非常に忙しかったため、完成までに時間がかかりました。しかし、ここにあります。お楽しみください!
この更新セクションには、新しいLightning LoRAについての追加情報も含まれています。スポイラー:彼らはダメです :(
-- 使用上の注意 --
スパゲッティ: ワークフローの接続は、各参照画像が複数のノードと他のノード間のクロス接続を追加するため、スパゲッティのように見えます。それでもシンプルですが、見た目はもう美しくありません。
順序: 画像を入力する際、画像1は右側にあります。したがって、右から左へと追加してください。ラベルも付いています。
正しいワークフローを使用してください: 追加のノードのせいで、3番目または2番目の画像を正しくバイパスするのは面倒です。1つのワークフローで3つすべてを柔軟に処理しようとせず、それぞれのワークフローを個別に使用することをお勧めします。
複数画像生成は非常に遅い: 品質は最大ですが、2画像版は1画像版の3倍、3画像版は5倍の時間がかかります。
これは、QWEN編集で使用される各画像が処理時間に1倍の乗数を追加するためであり、このワークフローでは(参照潜在変数のせいで)毎回2つの新しい画像を追加しています。
参照潜在変数ノードを使わずにQWEN編集を使用すると、複数画像生成は2倍・3倍の時間がかかります(画像が一度だけ追加されるため)が、品質はぼやけてしまいます。これがデメリットです。
この問題は複数画像ワークフローにのみ関係し、1画像用のqwedit_simpleワークフローは通常のQwen編集と同等の速度です。
スケーリング: 参照画像のスケーリングは厳密ではありません。大きくしたり小さくしたりできます。大きいほど生成に時間がかかり、小さいほど早く処理されます。
- メイン画像は通常のサイズにスケーリングしてください。ただし、上級ユーザーは最初の画像を好きなサイズにスケーリングし、その出力潜在変数をKサンプラーに手動で入力できます(「高度な品質」の下でさらに説明します)。
追加オプションの「Consistence」LoRA: Redditのu/Adventurous-Bit-5989 がこのLoRAを提案しました。
リンク:こちら、ワークフロー内にもリンクされています。
小さなディテール(例:唇の質感など)をわずかに良質に引き継ぐのを観察しました。
衣服のロゴが新しい衣装に引き継がれるなど、ランダムな特徴の引き継ぎがより確実になります。
しかし、他の部分の品質がランダムにわずかに低下することもあります。たとえば、人の脚の形状を通常のLoRAなしのときより正確に引き継げないことがあります。
また、モデルの創造性を低下させ、ときとして「興味深い」出力が得られにくくなります。
したがって、トレードオフです:細部を重視するなら有効ですが、そうでなければ不要です。
CivitAIページの指示に従ってください。ただし、彼らが推奨するワークフローは必要ありません。
-- その他の注記 --
新登場の2509 Lightning LoRA
結論:悪質(2025-10-14現在)
他のLoRAと品質面でほぼ同じです。
一部のユーザーは、それらの方が悪化しているとさえ言っています。
基本的に、品質とプロンプト適合性が低下するので、使用しないでください。
「テスト」用としても役に立たない。通常のモデルと比べて半分の確率でまったく異なる結果を出力します。
より速く「テスト」したい場合、このワークフロー(LoRAなし)を10ステップに設定し、品質を戻したいときは20ステップに戻すことをお勧めします。
一部のユーザーはオフセット問題を修正したと主張しています。
修正した可能性もありますし、していないかもしれません。彼らのいずれも例や証拠を提供していないため、私にはわかりません。
誰かが実際に証明するまでは、修正されていないと考えてください。
誰かが説得力のある修正をした場合、この記事および私のReddit投稿を更新します。
-- 更新セクション 終了 --
このワークフローとは?
現在、ベースで最高品質の2509結果を出力するワークフローは存在しません。このワークフロー設定は、公式QWENチャットバージョンとほぼ同等の結果を出力します。
また、他のすべてのワークフローは非常に複雑です。このワークフローは、最小限の設定で極めてシンプルです。これにより、簡単な出発点として使用でき、拡張したり、他の複雑なワークフローに組み込むこともできます。
つまり、このワークフローは次の2つの利点を提供します:
最高品質の2509出力の設定を、どこにでもコピーできる形式で提供。
余計なものを一切含まない、超シンプルな基本ワークフローを提供。
モデルの詳細と使用方法については、以下に多数の情報があります。
このワークフローには何が含まれていますか?
ノードと設定が極めて少ない小さなワークフロー
私が知る限り2509モデルで最大品質の結果を出力
必要なカスタムノードは1つだけ:ComfyUi-Scale-Image-to-Total-Pixels-Advanced
- GGUF版モデルを実行する場合は、もう1つのカスタムノードが必要です。
モデルダウンロードリンク
必要なすべてのファイルです。これらはワークフロー内にもリンクされています。
QWEN Edit 2509 FP8(22.5GB VRAM必要):
低VRAM用GGUFバージョン:
https://huggingface.co/QuantStack/Qwen-Image-Edit-2509-GGUF/tree/main
ComfyUI-GGUFが必要です。「Unet Loader」ノードでモデルを読み込みます。
注意:GGUFはFP8より遅く、品質も低くなります(Q8を除く可能性あり)
テキストエンコーダ:
このエンコーダのGGUF版の使用は推奨されません。不思議な効果が出ることがあります。
VAE:
参照画像リンク
猫: freepik
サイバーパンクのバーテンダー少女: civitai
シャツとスカートのランダムな少女: どこにもアップロードされていません。例として生成しました。
クイック使い方
ComfyUIを最新版に更新してください。QWENテキストエンコーダノードは2509モデルのリリース時に更新されました。
任意の画像サイズを入力してください。画像スケーリングノードが適切にリサイズします。
1MPx以上が理想的です。
ワークフローの画像スケーリングノードで、画像サイズが縮小されているか確認してください(拡大しないように)。
異常なアスペクト比も使用できます。「普通」でなくても構いません。16:9または9:16を超えると奇妙な結果が出る可能性がありますが、それでも動作することがあります。
設定の詳細をいじらないでください。この配置は意図的に最適化されています。
参照画像の入力、ゼロアウト、Kサンプラー設定、入力画像のリサイズが重要です。これらは変更しないでください。
Kサンプラーのステップ数を10にすると高速生成、30にすると高品質生成が可能です。
低VRAM環境ではGGUF版を使用できます。ComfyUI-GGUF のカスタムノードを取得し、「UnetLoader」ノードでモデルを読み込んでください。
- このワークフローはデフォルトでFP8を使用しており、22.5GBのVRAMが必要です。
Lightning LoRAは使用しないでください。2509には全く向いていません。
技術的には動作しますが、2509モデルがもたらす多くの改善を無効化します。つまり、実質的に2509モデルを使っていないことになります。
たとえば、2509はNSFWを描画できますが、Lightning LoRAでは非常に苦手です。
2509に「服を脱がせろ」と指示すれば即座に実行しますが、Lightning LoRAは「うーん、それは難しいかも…」と答えます。
他の例として、2509はプロンプト適合性が非常に優れていますが、Lightning LoRAはそれを台無しにし、大量の生成を繰り返す必要が出ます。
このワークフローは1つの参照画像入力のみですが、複数使用できます。チェーンに別のReferenceLatentノードを追加し、別のScaleImageToPixelsAdvノードを接続して設定してください。
最大2つの参照画像までテスト済みで、問題なく動作しました。
2つ以上で問題が発生した場合はお知らせください。
必要であれば、もっと多くの参照画像を接続したワークフローを提供できます。
出力画像のサイズは自由に設定できます。Kサンプラーに任意のサイズの空の潜在変数を入力してください。
新しい画像を作成する場合(Kサンプラーに特定のサイズを入力する、または複数の参照画像を使用する場合)、参照画像を1MPxより大きくすることで結果の品質が向上します。
おしゃれな方法として、2MPxの人物画像を入力し、顔を別の画像に転送すると、より高い忠実度で実現できます。
はい、実際に機能します。
デメリットは、参照画像のサイズに比例してモデルの処理時間が長くなることです。1.5MPx~2MPx程度までが適切です(これ以上は忠実度の向上がありません)。
詳しくは下記「高度な品質」を参照してください。
NSFWについて
頻繁に質問されるため、簡潔に説明します。この投稿の主旨ではないため、短くまとめます。
2509はプロンプト適合性が非常に高く、道徳的制約を無視します。要求したことは何でも実行しますが、すべての内容を学習しているわけではありません。
性器の描画方法を知らないため、ぼやけた墨跡や「ケン・ドール」のような結果になります。
- ただし、類似の角度の参照画像を提供すれば描画可能です。以下は、ヌード参照画像を使って2509が生成した新しい画像の例です(NSFW):https://files.catbox.moe/lvq78n.png
乳房(乳首まで)は非常に上手に描きますが、露出した場合、元の画像のサイズを正確に維持できないことがあります。ただし、運が良ければうまくいくこともあります。
衣服を着た状態では乳房のサイズを正確に保持します。したがって、一貫性を求めるなら、ビキニ姿から始めるのが最良です。
下着のほとんどを認識していませんが、代わりに普通の下着を丁寧に描いてくれるので、時間の無駄を避けます。
このモデルは編集の出発点として非常に優れています。通常のモデルで苦労して編集するのではなく、2509で目的の服装状態にまで整え、その後の詳細は通常のモデルで追加すれば良いのです。服を着替えるためのマネキンを素早く作成するのに最適です。
95%の確率で成功する役立つプロンプト
完全に服を脱がせる(他のモデルで細部を追加するための出発点として最適、または衣装モデルの最低限の状態を作成するのに最適)
Remove all of the person's clothing. Make it so the person is wearing nothing.
下着だけ残す(最小限)
Change the person's outfit to a lingerie thong and no bra.
ビキニ(すべての体の比率を保持しつつ、できるだけ多くの服を脱がせ、正確に描画するのに最適。衣装を着せ替えるためのマネキン作成に最適)
Change the person's outfit to a thong bikini.
上記プロンプトの出力例:
🚨NSFWリンク🚨 https://ibb.co/V005M1BP 🚨NSFWリンク🚨
外部リンクを使わずに例画像にアップロードしようと考えていますが、複数のプロンプトを含む(「various」をポジティブプロンプトに入力)ことの影響が不明なので、まだ行っていません。
また、言うまでもないが、実在する人の写真に無断で手を加えるべきではない。通常のディフュージョンモデルでもすでにそれほど難しくないが、QWENやNano Bananaのようなツールはその敷居を大きく下げてしまった。これは大きな問題になるだろう。自分自身がその一助にならないのが最良だ。
QWEN Edit の完全な説明とよくある質問
理由は完全には説明できないが、この特定の設定は最高品質の結果をもたらすことが確認されており、その差は非常に明確である。一部は説明できるので、以下に述べる。以降、QWEN Edit 2509を「Qwedit」と呼ぶことにする。
参照画像とQwenテキストエンコーダーノード

Comfyに付属するTextEncodeQwenImageEditPlusノードは、最悪の方法で画像を単純にリスケールしてしまうため、クオリティが低い。
しかし、これを完全に無視することはできない(可能ではあるが)。完全にバイパスすると、結果は平均的なクオリティにとどまる。
ReferenceLatentノードを使えば、Qweditに参照画像を2回渡すことができる。2回目は、劣化しない適切なスケールで。
そして、元のコンディショニングをゼロにし、そのゼロ値をksamplerのネガティブ入力に渡すことで、Comfyの劣化したスケーリングによる画像の使用を抑制し、代わりに私たちがより適切にスケールした画像を使用させる。
注:ゼロアウトには、実際のテキストエンコーダーからのコンディショニングを必ず渡す必要がある。
「すべてをゼロにしている」ように思えるが、実際にはksamplerに多くの情報を引き渡している。
よって、ゼロアウトにランダムなゴミを渡してはいけない。必ずQwenテキストエンコーダーノードからのコンディショニングを渡すこと。
この処理が、このワークフローが高品質な結果を得られる要因の80%を占める。何をコピーするにしても、これは必ずコピーすること。
画像のリサイズ
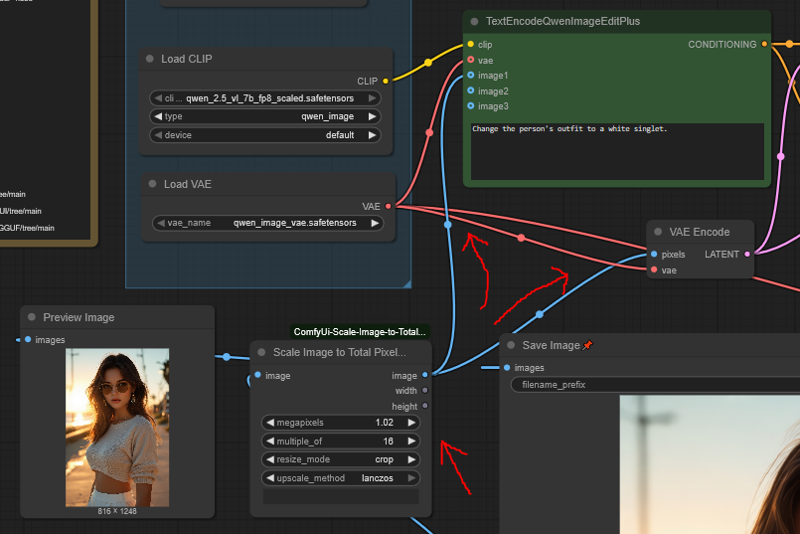
ここでは1つの必須のカスタムノードが登場する。
ほとんどのワークフローは通常のScaleImageToPixelsノードを使用しているが、これは存在するノードの中でも最も劣悪なものの一つであり、ComfyUIから削除すべきである。
このノードは、すべてのディフュージョンモデルが2、4、8、または16の倍数で動作することを無視して、単純に1MPxにリスケールする。
画像を1177x891にスケール?ああ、よし、完璧だね、スターブリーフモデルにはぴったりだよ。
そこで登場するのがScaleImageToPixelsAdvノード。
この優れたノードは、指定したピクセル数に画像をスケールするだけでなく、指定した数で割り切れるように調整してくれる。
1MPxにスケールするのはこのワークフローの半分に過ぎない。実際にはワークフローは1.02MPxに設定されている。
その理由は、TextEncodeQwenImageEditPlusが、前述の劣化した方法で画像を再スケールするからである。
最初に1.02MPxにスケールすることで、この再スケールを「アップスケール」ではなく「ダウンスケール」に強制し、結果のぼやけを大幅に軽減できる。
さらに、ScaleImageToPixelsAdvは常に切り捨てを行うため、画像が16で割り切れない場合、1MPxよりわずかに小さくなる。1.02MPxにすることで、ノードが求める本当の1MPxに非常に近づける。
Qweditは0.5MPxから1.1MPxの画像を十分に処理できるため、ksamplerに1MPxを超える画像を渡しても問題ない。
16で割り切れるサイズが最適。112や56といった他の数字を推奨する人がいるが、それは無視してよい(理由は後述)。
「拡大」ではなく「切り抜き」を用いる。理由は画像の歪みを抑えられるから。画像を10ピクセル分削ってでも品質を保つ価値はある。
画像のオフセット問題 – いいえ、これは修正できません。修正できると言う人は嘘をついています
オフセット問題とは、編集後の画像でオブジェクトが意図した位置からわずか(または大幅に)ずれてしまう現象です。
このワークフローは、オフセット問題の発生確率を可能な限り最小限に抑えます。
- はい、他の「56の倍数」や「112の倍数」などのランダムな修正法よりも低いです。
「56や112の倍数」のアプローチが機能しない理由は以下の通りです:
- それは問題の完全な原因ではない。Qweditモデルは、ただランダムにこのオフセットを発生させるだけなので、制御できない。
- モデルの構造上、112の倍数にしようが何の意味もない。1MPxの画像サイズは112の倍数に一致しないため、結局画像は112の倍数でないサイズにスケールされ、悲劇が起きる。
本気で言います:これは修正できません。発生確率を減らすしかなく、このワークフローはそれを最大限に実現しています。
このワークフローは、どのようにして画像のオフセット問題を減らしているのか?
問題の90%は画像のリスケールに起因する。
1.02MPxにスケールし、16の倍数にすることで、Qweditが実際に対応したい解像度に最も近づける。
信じられない?公式Qwenチャットで、異なるアスペクト比の画像をいくつか試してみよう。
編集された画像が返ってきたとき、1MPxで16で割り切れるサイズにスケールされていることに気づくはずだ。ScaleImageToPixelsAdvノードがまさにそうするように。
つまり、Qweditに最適な画像サイズは:1248x832、832x1248、1024x1024。
非正方形のサイズは、通常のStable Diffusionのサイズよりわずかに縦長であることに注意。
- しかし心配いらない。このワークフローはあらゆる合理的なアスペクト比で動作する。
残りの10%は、Qweditの特有の奇妙な挙動によるもので、これまで誰も解決できていない。
たとえ1024x1024の完璧な画像であっても、時々この問題が発生する。だから、誰かが「この問題を解決した」と言うなら、法的に平手打ちしても問題ない。
入力するプロンプトもこの問題に影響を与える。画像で発生しているなら、プロンプトを少し言い換えてみることで改善する可能性がある。
Lightning LoRA、使わないほうがいい理由
短く言えば、Lightning LoRAを使用すると、出力品質がQweditの初版レベルまで低下し、2509のすべての利点を失う。
2509と比べて、プロンプトの忠実度が低い。
NSFWに対応できない。
描画品質が劣る。
アスペクト比が「普通でない」場合、より頻繁に失敗する。
理解できる概念が少ない。
もし高速生成が欲しいなら、20ステップではなく10ステップを使用すること。
描画されていない部分(例:人の顔)は依然として綺麗に見えるが、描画された部分のディテールが劣化する。
実際のところ、それほど悪くない。本当に速度が欲しいなら、10ステップでも問題ない。
ksamplerの設定は?
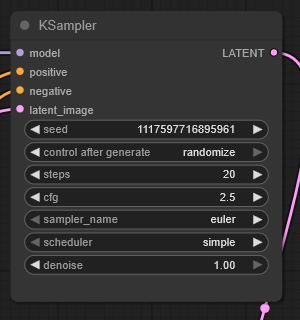
正直、なぜかは全くわからないが、誰かのワークフローでCFG 2.5と20ステップを使っていたところ、うまく動いた。
CFG 4.0と40ステップでも可能だが、特に良くなさそうなので、やる意味がない。
CFG 2.0や3.0といった他の値は、常に結果を悪化させる。なぜか非常に敏感。
よって、CFG 2.5をそのまま使い続けるのが最良。変更しようとするのは苦痛に値しない。
10ステップで高速生成が可能。顔や変化のない部分は完全に問題なく見えるが、描画された部分(例:革ジャケット)のディテールが粗くなる。
実際にはそれほど悪くない。スピードを優先するなら、10ステップでも問題ない。
30ステップだと20ステップよりディテールが改善されるが、僅かであり、その価値は低い。
絶対に30ステップ以上にしないこと。それ以上は画像品質が低下し始める。
より多くの参照画像は可能ですか?
このワークフローは簡略化のため1枚の参照画像にしていますが、複数追加可能です。
もう1つのReferenceLatentノードと画像スケーラーノードを追加する。
2番目のReferenceLatentを最初のノードの直後に直列に接続し、2番目の画像をリサイズ後、そこに接続する。
2枚の画像でテスト済みで問題なく動作する。3枚については未確認。
重要:参照画像は1MPxである必要はない。気分が乗ったら、1.5MPxや2MPxの画像を参照として入力し、ksamplerには1MPxの潜在変数を渡すことで、はるかに高品質な結果を得られる。
例:顔の転送がより詳細になる。
ただし、2MPxの参照画像は処理に時間がかかる。
単一の画像入力にも同様に適用可能。ksamplerには1MPxの潜在変数を渡すこと。
高品質の高度な手法
参照画像に関するこの話は……?
はい!1MPxに正確にリサイズ可能で16で割り切れる2MPxの画像を、プリスケールせずに直接入力し、ksamplerには目的の1MPx潜在変数を渡せば、2MPx画像を1MPxに直接編集できる。
明確に高品質な結果が得られる!
設定が面倒だが、動くのは面白い。
手順:
1MPxにリサイズしたバージョンをテキストエンコーダーノードに渡す。
2MPxのバージョンをReferenceLatentに渡す。
ksamplerには1MPxの正しいスケール(2MPxと1:1で16で割り切れる)の潜在変数を渡す。
あとは、動くだけだ™
Qweditはどのような画像サイズに対応していますか?
1MPx以下は問題ない。
ただし、1MPxにスケールアップすることを推奨。プロンプトの忠実度とぼやけを軽減できる。
1MPx以上にすると、Qweditは徐々に画像を「深く揚げ」始める。
プロンプトの忠実度も低下し、オブジェクトを複製して画像を歪ませることが多い。
それ以外は、実際には動作する。
よって、1MPxを超えて使用するかどうかは、どれだけ「揚げた」画像を受け入れられるか、どれだけ再試行する意欲があるかに比例する。
実際、1.5メガピクセル(例:1254x1254)までは、画像品質の劣化はそれほど激しくない。気づかれるが、用途によっては「許容できる」レベル。
- ただし、いくつかの試行が必要になる。他の方法で失敗する可能性がある。
2MPx以上になると、深刻な深揚げが発生し、画像はオブジェクトの複製で汚染される。
ただし、状況によってはまだ使える。
以下はバーテンダーの女の子の1760x1760(3MPx)編集画像です:https://files.catbox.moe/m00gqb.png
ややうまく動作しているように見える。シーンが暗かったため、深揚げの影響は目立たない。しかし、彼女の手がボトルに奇妙に重複しており、顔を拡大するとディテールの歪みが確認できる。また、両腕をロボット化するという意図も守られなかった。あくまで状況次第であり、繰り返すが、1MPxを超える使用はあまり推奨しない。