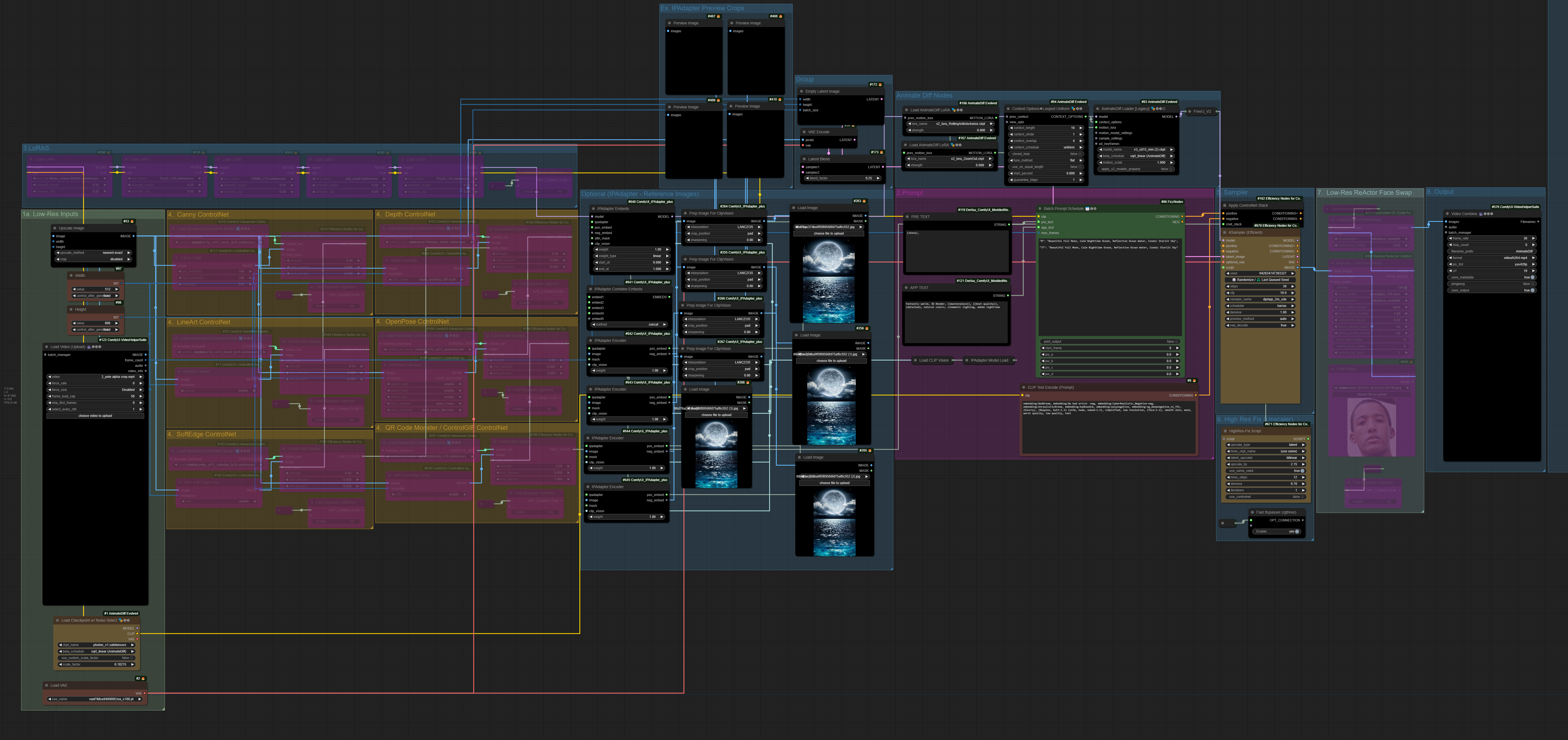
JBOOGX & MACHINE LEARNER ANIMATEDIFF WORKFLOW - Vid2Vid + ControlNet + Latent Upscale + Upscale ControlNet Pass + Multi Image IPAdapter + ReActor Face Swap

详情
下载文件 (1)
关于此版本
模型描述
WELCOME TO THE JBOOGX & MACHINE LEARNER ANIMATEDIFF WORKFLOW!
Full YouTube Walkthrough of the Workflow:
1/8 UPDATE
Added ReActor Face Swap to Low-Res & Upscaler. Added Bypass / Enable Toggle Switches using rgthree node pack.
12/7 UPDATE
About this version
v2 brings a few quality of life changes and updates.
I've separated all of the ControlNets into individual groups for you so that you can bypass the one's you don't want to use with ease.
In the IPAdapter, please download and place this file in your comfyui\clip_vision directory. This is for the 'LOAD Clip Vision' node.
https://drive.google.com/file/d/13KXx6u9JpHnWdemhqswRQJhVqThEE-7q/view?usp=sharing
You can find the IPAdapter Plus 1.5 model for the 'LOAD IPAdapter Model' node here.
https://github.com/cubiq/ComfyUI_IPAdapter_plus
If you don't want to upscale, then bypass all Upscale groups on the bottom right.
That should be it :)
Please tag me in anything you make using the workflow and I will share on my social!
@jboogx.creative on Instagram
---------------------------------------------
DISCLAIMER: This is NOT beginner friendly. If you are a beginner, start with @Inner_Reflections_Ai vid2vid workflow that is linked here:
https://civitai.com/articles/2379/guide-comfyui-animatediff-guideworkflows-including-prompt-scheduling-an-inner-reflections-guide
After many requests, I have decided to share this workflow that I use on my streams publicly. This is capable of the following....
-------------------------------------------------
Vid2Vid + Control Nets - Bypass these nodes when you don't want to use them and add any CN and preprocessors you need. The one's included are my go to's.
Latent Upscaling - When not Upscaling during testing, make sure to bypass every upscaling group and the very latent upscale video combine node.
A 2nd ControlNet pass during Latent Upscaling - Best practice is to match the same ControlNets you used in first pass with the same strength & weight
Multiple Image IPAdapter Integration - Do NOT bypass these nodes or things will break. Insert an image in each of the IPAdapter Image nodes on the very bottom and whjen not using the IPAdapter as a style or image reference, simply turn the weight and strength down to zero. This will essentially turn it off.
QR Code Illusion Renders - To do this, use a black and white alpha as your input video and use QR Code Monster as your only ControlNet.
-------------------------------------------------
This was built off of the base Vid2Vid workflow that was released by @Inner_Reflections_AI via the Civitai Article. The contributors to helping me with various parts of this workflow and getting it to the point its at are the following talented artists (their Instagram handles)...
@lightnlense
@pxl.pshr
@machine.delusions
@automatagraphics
@dotsimulate
Without their help, this would not have provided the many hours of video making enjoyment it has for me. I am not the most technically gifted person in this, so any input from the community or tweaks to further improve upon this would be greatly appreciated (that's really why I want to share it now)
There may be some node downloading needed, all of which should be accessible via the Comfy manager (I think). You can bypass any number of the LoRAs, ControlNets, and Upscaling as you need for what you are currently working on. Having intermediate to advanced knowledge of the nodes will help you mitigate with any of the errors you may get as you're turning things on and off, if you're a total beginner, I would recommend starting with @Inner_Reflections_AI base Vid2Vid workflow as it was the only way I was able to understand Comfy in the first place.
The zip file includes both a workflow .json file as well as a png that you can simply drop into your ComfyUI workspace to load everything. Be prepared to download a lot of Nodes via the ComfyUI manager.
Any issues or questions, I will be more than happy to attempt to help when I am free to do so 🙂
If you make cool things with this, I would love for you to tag me on IG so I can share your creations. Also, a follow is greatly appreciated if you extract any value from this or my Vision Weaver GPT 🙂 If you use it and like it? Leave me a dope review and throw me some stars!
@jboogx.creative