Wan2.2 I2V long video with audio - FOR DUMMIES!

详情
下载文件
关于此版本
模型描述
你和我一样是新手吗?
更新:2025年11月1日 14:44(太平洋时间)
刚刚上传了 v1.2 版本。采纳了所有评论者的建议——谢谢你们!速度和质量都显著提升了!你们太棒了!
所有这些工作流看起来都复杂得要命,对吧?我该调哪个神经病旋钮?为什么我突然把所有东西都搞砸了?
我花了好几天时间玩 Coyotte 的 Moviemaker——超棒的工作流,用起来很有趣(如果你比我聪明的话)——然后我决定,得为我自己把这玩意儿彻底简化。也许你也会从中受益。
工作流如何运作:
你只需提供一张起始图像和一个提示词。只需寻找绿色框。
有一些参数可以调整,但那些紫色的(在我看来是粉红色的,不过无所谓)只有在你大概知道你在做什么时才碰。黑色框是用于加载模型的——这些最好留给高级用户。红色框千万别碰,否则你会把一切搞砸。
它使用 JoyCaption 分析你的图像,并构建组合提示词的第一部分;使用 LoraManager 提取你 LoRA 的触发词,并将你的提示词合并进去。它对采样器做了一些“魔法”操作(again,我是新手,你也是新手,我们俩都不知道这玩意儿到底怎么运作,所以我们叫它魔法),然后输出到你的“工作”视频中。留意这个步骤;如果你不喜欢结果,就别浪费 GPU 时间去上采样和加音效了。
使用 LoraManager:
首先,确保你用 Comfy Manager 安装了 LoraManager。
现在,访问 http://[你的IP地址]:8188/loras
如果你从未用过 LoraManager,它可能需要一点时间来索引你所有的 LoRA。没关系,反正你迟早会想重新整理它们。
现在,选择一个 LoRA,当你把鼠标悬停在上面时,会看到一个小的“发送”箭头。
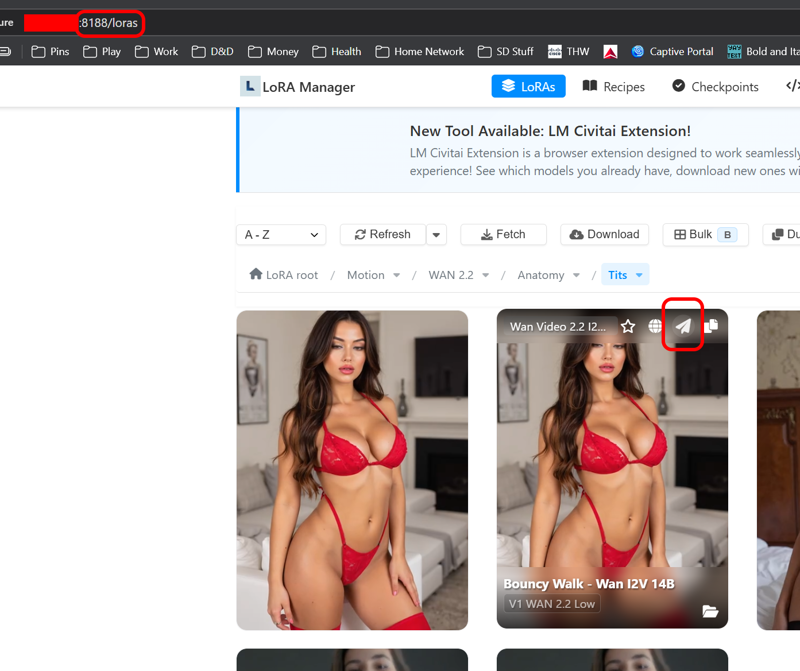
选择一个看起来最符合你当前需求的 LoRA 加载器。
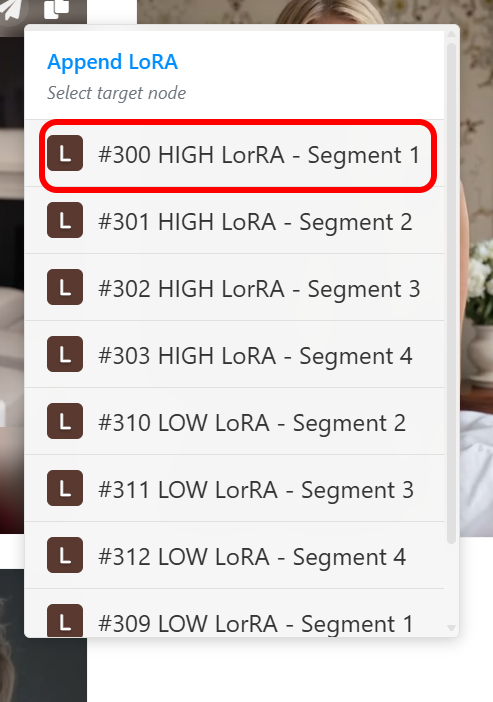
然后切换回你的 ComfyUI 标签页。你会看到它出现在列表中,旁边是触发词。
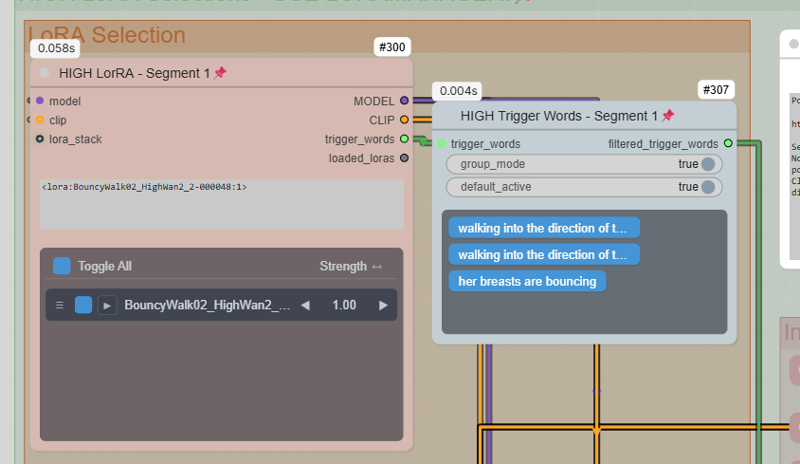
这些触发词会自动添加到提示词中。使用滑块确定你想要的 LoRA 强度,然后点击你不想要的触发词,它就会取消选中。
就这样。它会为你生成一些视频,你可以玩得很开心。
在我这台 5090(这就是我用的,没测试其他显卡)上,生成一段 10 秒、非循环、带声音的视频需要 30 分钟。考虑到它一路上做了这么多事,这已经不错了。
如果你的显卡 VRAM 更少,建议把 JoyCaption 的设置大幅调低。你需要在右下角的“String Ops”部分取消固定并展开它。如果你的 VRAM 小于 24GB,建议最多只做 3-4 秒的视频。
安装:
如果你是 Comfy-UI 新手,请先安装 ComfyUI Manager。不,我不会教你怎么做;谷歌会帮你。安装完成后,打开这个工作流。然后打开 Comfy-UI Manager,选择“安装缺失节点”。它会自动完成安装,接着你从 ComfyUI Manager 内部重启 Comfy-UI。完成后,刷新页面,再次打开 Manager,进入 Model Manager,将筛选条件改为“In Workflow”,然后安装所有这些模型。这可能需要一段时间,因为它们体积很大。
不过,这可能不会自动安装 MMAudio 模型。如果没有,请从这里下载模型:https://huggingface.co/Kijai/MMAudio_safetensors/tree/main
将它们放入:ComfyUI/models/mmaudio
感谢 KIJAI!
Nvidia bigvganv2 应该会自动下载,但如果没下载——请从这里获取:https://huggingface.co/nvidia/bigvgan_v2_44khz_128band_512x
将 nvidia huggingface 中的所有内容放入:ComfyUI/models/mmaudio/nvidia/bigvgan_v2_44khz_128band_512x
祝你好运!祝你拍片愉快!
如果你觉得我的工作流很烂,别担心,我不会难过。告诉我哪里可以改进。这真的是我的第一个工作流。
如果你喜欢它,那太棒了!