Wan2.2 AIO Workflow (I2V - S2V - Upscaler - Frame Interpolation - Faceswap)



詳細
ファイルをダウンロード
モデル説明
まず、このワークフローの基盤を提供してくれたthesharque588にすべてのクレジットを捧げます!
シナリオと自動化対応の長尺動画用 AIO ワークフロー
このワークフローに寛容になっていただけたら幸いです(私は8月からComfyUIをゼロから一人で始めました)!
このワークフローの目的は、私が必要なすべての要素を1か所に集め、それらを連鎖させて使用できるようにすることです。そして、これは共有するに値する十分な出来栄えだと考えています。
このワークフローには以下が含まれます:
- インデックスによるシナリオ制御
- 各インデックスの長さを個別に選択
- 自動プロンプト翻訳機能
- カラーマッチング
- フェイススワップ(ReActor Faceswap)
- フレーム補間(RIFE-VIF)
- S2V(MMaudio対応、音声ソース不要)
- アップスケーラー x2-x4(Upscaler Tensorrt(x4) + Video Upscaler(x2))
- グループを個別に実行するグループ制御機能
これはどのように動作するのか?
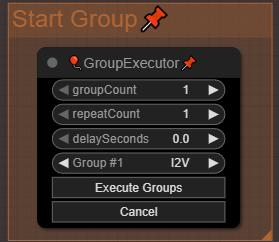
まず重要な点!「GroupExecutor」ノードを使ってグループを実行する必要があります。これにより、選択したグループのみが起動されます。この仕組みは、すべてのグループをアクティブなままにして、待機中のグループのモデルを読み込まないように設計されています。ComfyUIの「Execute」ボタンで生成を実行すると、I2V生成の初期段階でMMAudioモデルが並列で読み込まれ、I2Vに使用可能なVRAMが減ってしまいます。時々、「GroupExecutor」ノードの1つが動作しなくなることがあります(理由はまだ調査中です)。その場合は、新しいノードに置き換えるか、ワークフロー内の他のノードに差し替えてください。
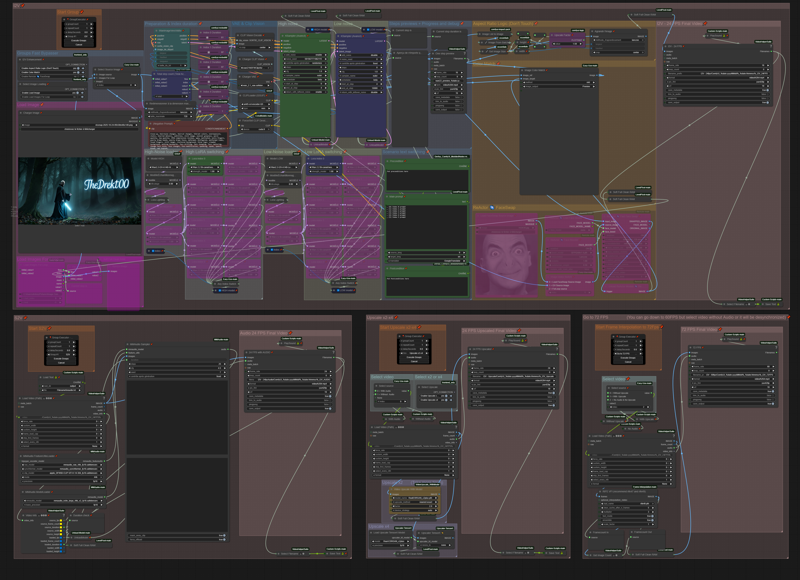 各処理ステップは4つのグループに分かれています:画像→動画(I2V)、音声→動画(S2V)、アップスケーラー、72fps化(フレーム補間)。
各処理ステップは4つのグループに分かれています:画像→動画(I2V)、音声→動画(S2V)、アップスケーラー、72fps化(フレーム補間)。
I2V
ステップ1:I2V強化 - 動画に適用したい強化オプションを選択します。
「Select Source Image」で0または1を選択してソース画像を指定:

0 = 個別の画像を読み込む
1 = フォルダから画像を読み込み、設定した枚数分処理する(AFK状態でワークフローを継続させたい場合に使用。各生成後にフォルダ内の次の画像をループして読み込みます - フォルダパスを設定することを忘れないでください)。まだ改善の余地あり、現在作業中です。
ステップ2:準備 - 動画のパラメータを設定

バッチサイズと合計ステップ数を設定します(各インデックスが1ステップに相当。ステップ数が3ならインデックス0~2の3つを使用します)。
画像を最大サイズにリサイズしてください(毎回同じ解像度の画像を使用しないように、自動化を意図しています。より細かい制御が必要な場合はノードを変更してください)。
スライダーで各インデックスの長さを個別に設定(スライダーはWanImageToVideoと同じフレーム値、4ずつ増加)で設定されていますが、別のINT値ノードで変更可能(ただし、否定プロンプトボックスの裏にあるAny Switch Indexに接続する必要があります)。
ステップ3:ローダー - モデルとLoRAを設定
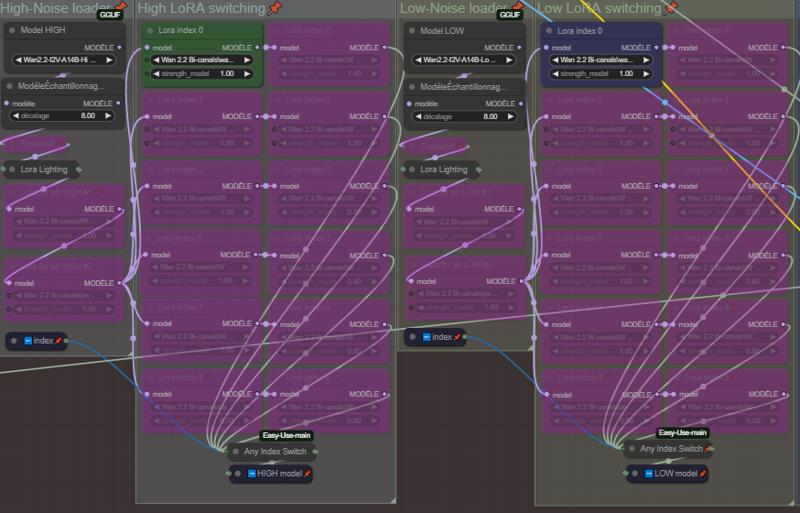
HighとLowノイズ用のモデル(GGUF)を選択。Lightning LoRAとFusionX LoRAを選択(LightningとFusionX LoRAは必須ではありません。使用しない場合はノードを無効化してください)。
High-NoiseローダーグループとLow-NoiseローダーグループのLoRAは、すべてのインデックスに共通して適用される汎用LoRAです。
各インデックスごとにLoRAを選択。この部分は5つのインデックス(インデックス0から開始)用に設定されています。必要に応じて追加または削除してください。追加した場合は、各列の下にあるAnySwitchIndexに接続してください。
ステップ4:プロンプト - シナリオを設定
🚨🚨🚨🚨 英語が苦手な方でも大丈夫!プロンプトには内蔵翻訳機能がついています 🚨🚨🚨🚨
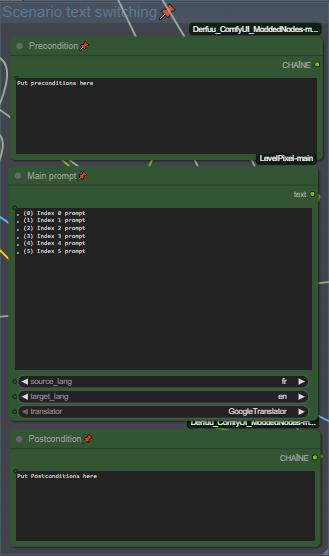
各インデックスのプレ条件とポスト条件を設定し、シナリオ用プロンプトを入力してください。プロンプト内のインデックスの区切りは改行で行います。私は「,(0)」、「,(1)」などの区切りを使用して、シナリオをわかりやすく整理しています(他の方法も可能で、グループノードの裏側で区切り方法を変更できます)。
🚨🚨 翻訳のソース言語とターゲット言語を必ず設定してください 🚨🚨
ステップ5:フェイススワップ - フェイススワップのパラメータを設定
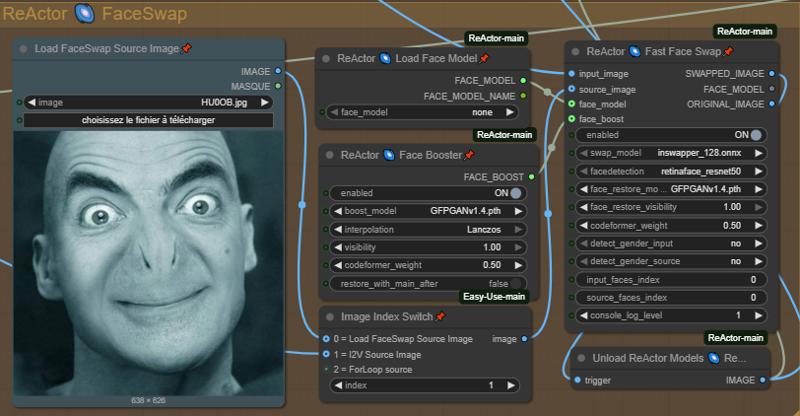
Wan2.2は多くのLoRAが顔の変形・ズレを引き起こすことで知られています。そのため、一部のLoRAによる顔のズレを補正するためにReActor Faceswapを追加しました。設定はこのままでも十分ですが、自由に変更して実験してください(ComfyUI Managerで利用可能。モデルは自動ダウンロードされます)。
スワップに使用する画像ソースを選択:
0 = ソース画像を読み込む
1 = スタート画像をソースとして使用
ステップ6:アスペクト比ロジック+カラーマッチ
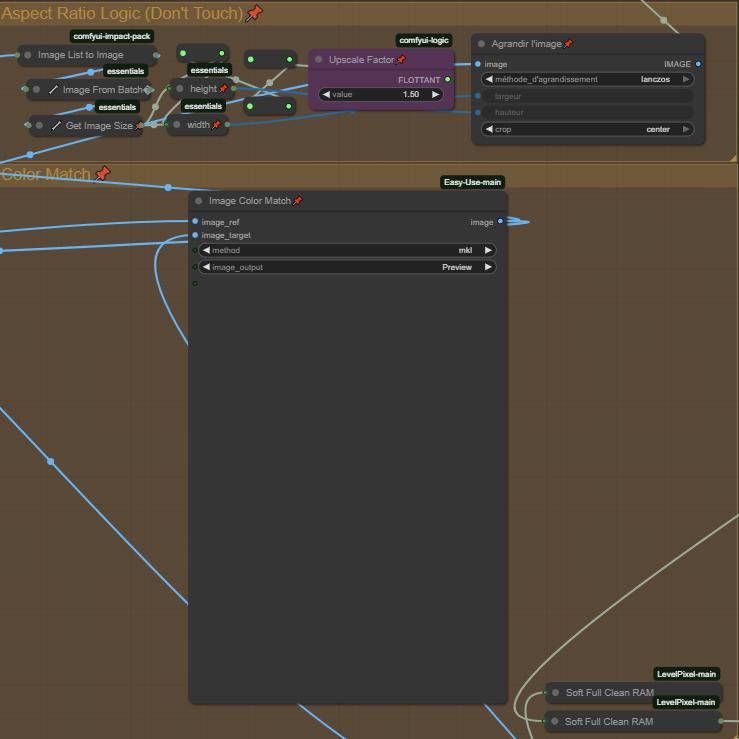
アスペクト比ロジックは、動画の見栄えを少し改善するための簡単なズーム機能です。アップスケール係数を変更してズームの度合いを調整してください。
画像カラーマッチは、ソース画像と同じ色を維持・一致させるために使用されます。無効化することはできません(たとえバイパスしても、次のノードには何も送信されません)。色の問題が発生した場合は、「Method」を変更するか、ノードを削除してください。この問題は今後のアップデートで修正されます。
(重要)
ステップ7:最終動画とチェーン機能
すべての最終動画のフォルダパスはテキストファイルに保存されます(Save Textノード)。この目的は、生成を連鎖させることです。I2Vの生成が終わったら、テキストファイルに保存された最終動画のファイル名を読み込んで、次のグループの開始時に自動的にロードできます。テキストファイル名を変更する場合は、「Save Text」および「Load Text」ノードの他のファイル名と一致させることを忘れないでください!
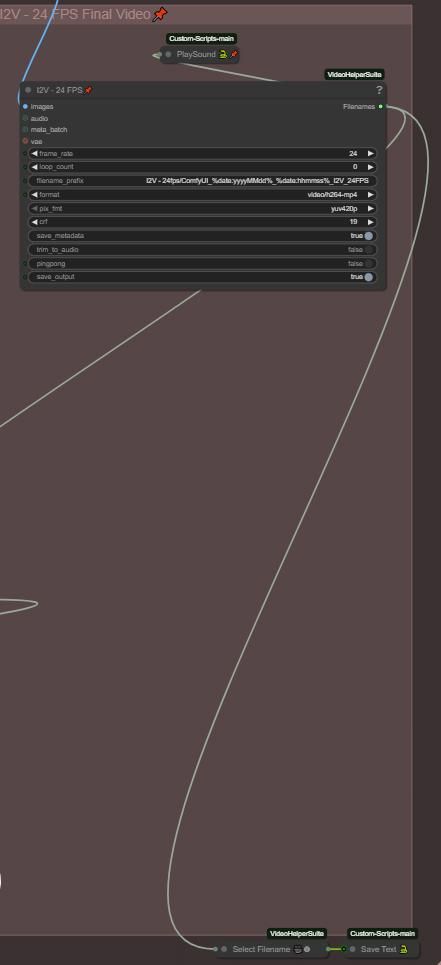
最終動画はMMaudioとの互換性を高めるために24fpsに設定されています(MMaudioは24fpsで学習されています)。動画に音声を追加しない場合は、16fpsに下げることもできます。
また、ワークフローの生成が完了したときに通知する「Playsound」ノードも用意されています。必須ではありませんので、不要な場合は削除してください。
ステップ8:プロセス監視とデバッグ
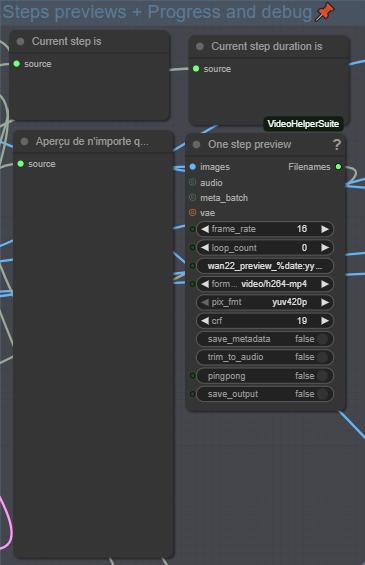
この部分では、現在処理中のインデックス、合計フレーム数、プロンプト、各インデックスのプレビューを表示します。これにより、生成を監視し、必要な調整を行うことができます。
S2V
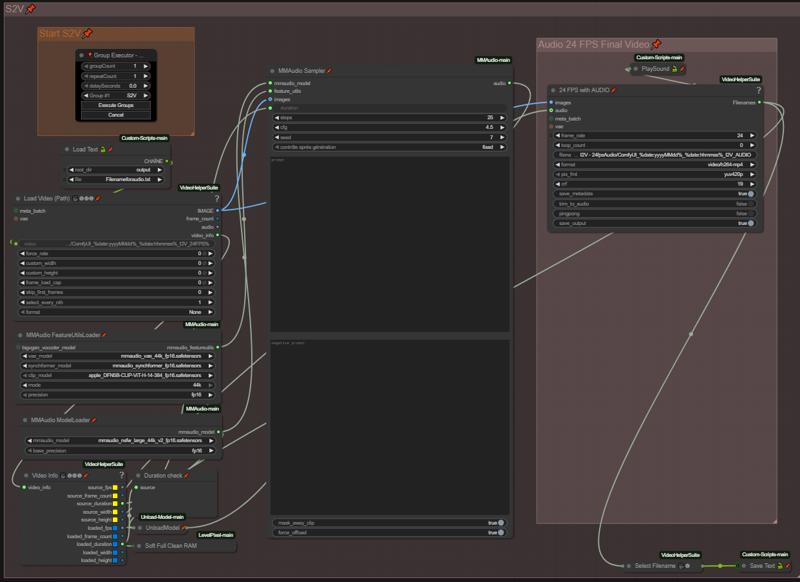
ここで音声用プロンプトを入力します。基本モデルよりはるかに良い結果が得られるため、NSFW MMaudioの使用を推奨します。すべてが自動化されているため、ポジティブ・ネガティブプロンプトを設定したら、グループを実行するだけです。自動的に「Load Text」ノードから前回のI2V生成動画を読み込み、音声を追加します。
アップスケーラー x2-x4
ステップ1:ソース動画を選択(音声あり/なし)
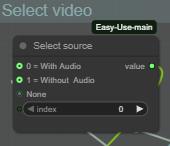
ここで、MMaudioグループの音声付き動画をアップスケールするか、I2Vグループの音声なし動画をアップスケールするかを選択します。
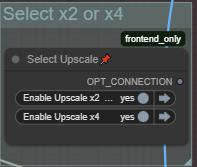
ここで、どのアップスケールグループを実行するかを選択します。
注意:
x2アップスケーラーはTensorRTを使用していないため、x4よりもはるかに遅いです。x2を高速でアップスケールするより良い方法があれば、ご提案ください。
x4アップスケーラーはTensorRTを使用します。すでに.\models\upscale_modelsにアップスケールモデルが存在する場合、自動的にインポートされます。x4アップスケーラーのみ対応。x2モデルのインポート・変換を試みましたが、動作しませんでした。
必要に応じてアップスケーラーのパラメータを変更し、「GroupExecutor」ノードでグループを実行してください。
フレーム補間(72fps化)
前のグループと同じロジックです。
ステップ1:ソース動画を選択(アップスケール/音声の有無)
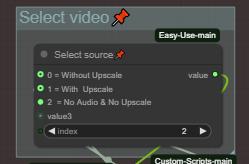
直前の生成グループに応じて選択:
0 = アップスケールなし(MMaudio 24fps音声付き動画を読み込む)
1 = アップスケールあり(アップスケール済み動画を読み込む)
2 = 音声なし・アップスケールなし(I2Vグループの動画を読み込む)
ステップ2:調整
最終動画は音声と同期を保つために72fpsに設定されています(音声グループを使用した場合)。音声グループを使用しない場合は、必要に応じて60fpsに下げることもできます。
前のグループと同様、必要に応じて補間パラメータを調整してください。
リソース
カスタムノードはComfyUI Managerで自動検出されます。不足しているものがあれば、お知らせください。
私はRTX 5080 16GB、RAM 64GBでこのワークフローを使用しています。
GGUFモデルとVAE:
https://huggingface.co/QuantStack/Wan2.2-T2V-A14B-GGUF/tree/main
NSFW ClipVision:
https://huggingface.co/ricecake/wan21NSFWClipVisionH_v10/tree/main
Umt5 xxlエンコーダー GGUF:
https://huggingface.co/city96/umt5-xxl-encoder-gguf/tree/main
NSFW MMaudio:
https://huggingface.co/phazei/NSFW_MMaudio (ダウンロード後、「mmaudio_nsfw_large_44k_v2_fp16.safetensors」とリネームしてください)
Lightx2v LoRA:
https://huggingface.co/lightx2v/Wan2.2-Lightning/tree/main/Wan2.2-T2V-A14B-4steps-lora-250928
FusionX LoRA:
https://huggingface.co/vrgamedevgirl84/Wan14BT2VFusioniX/tree/main/FusionX_LoRa
このワークフローは継続的に最適化されています。将来的にV2が登場する可能性があります。何か見落としている点があれば、追加します。ご質問があれば、遠慮なくどうぞ(プロフィールのDiscordリンクをご利用ください。皆様にとって便利です)。
_このComfyUIワークフローをご利用いただきありがとうございます。責任を持って、尊重してご利用ください。
このワークフローは、創造的・技術的・個人的な実験のために作成されたものであり、害やハラスメント、虐待のためのものではありません。
_