(SFW/NSFW) Simple Z Image Turbo img2img (Bringing Realism to Any Picture)

詳細
ファイルをダウンロード
モデル説明
ざっくり言うと:お気に入りのモデルで1girlを前屈みの姿勢で生成し、Z-Imageを使ってリアルに仕上げよう!
PS:ワークフローに問題があれば、修正できるように教えてください。
Z-Image Turboは、圧倒的に優れたテキスト→画像モデルです。その出力のリアリズムと成熟度は、プロンプトから直接画像を生成するために活用できるだけでなく、他のモデルで生成された画像の仕上げにも使用できます。コツは、低ノイズで仕上げ工程として使用することです。これにより、構造を保ちながら自然な質感、奥行き、照明を追加できます。
たとえば、以下はSDXLモデルで作成した画像です:

以下は同じ画像をZ-Noise img2imgで処理した結果です。彼女の顔が整えられ、背景の「ノイズ」が大幅に減り、一貫性が高まりました。また、手に持っている携帯電話の外観もシャープで整った仕上がりになっています。

Z-Image Turboは、細部の合成能力が非常に優れています。低ノイズ設定では、完全な再描画ではなく、リアリズムの仕上げのように機能します。肌の毛穴、髪の一本一本、布地の質感、微細な影、より自然な照明を追加しつつ、ポーズ、顔の構造、デザインはそのまま維持できます。
NSFWコンテンツで使う方法
もともと、私はZ Imageでimg2imgを試したかった理由がこれです。
問題は、Z Imageは「陰茎」や「膣」が何であるかをまったく理解していないことです。これらを台無しにしてしまいます。そこで、私が考えた最も単純な解決策は、その部分をマスクして、それ以外の画像部分をノイズ低減することです。私の実験では、この方法はうまく機能しています。
たとえば、以下は私が非常に手抜きで作成した画像です。顔の詳細調整は一切行っておらず、ベース画像を1216×832で生成しました。
この画像はIllustrij(Illustriousモデル)で生成しました。LoRAは韓国系女性用の1つだけ使用し、画像の編集はほとんど行わず、Z Imageの驚異的な性能を示すために、やや半リアルでプラスチック的な仕上がりにしました。

性器部分をマスクし、そのマスクを反転させて、画像の残り部分をZ Imageでノイズ低減します。

マスクを反転させた後(ComfyUIのマスクエディタで)、Load Imageノードは以下のようになります:
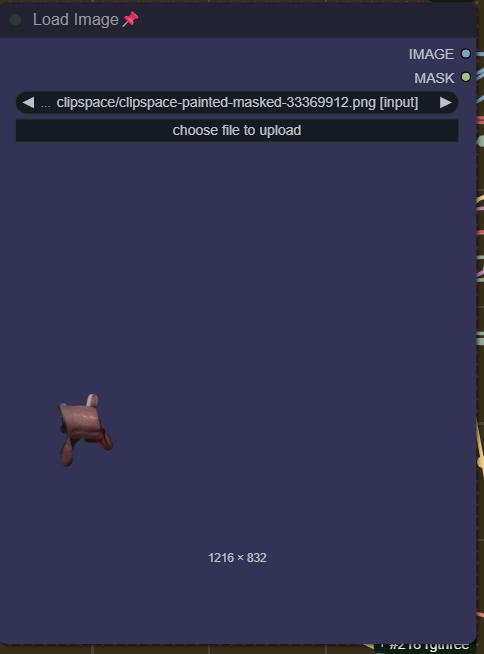
その後、img2imgを実行します。
以下は、ノイズ低減値0.55で得られた結果です。顔や他の細部にいくつか追加のディテールを加えましたが、基本的なアイデアは同じです:

もう一つの例:
処理前(私の好きなモデルの一つであるNova Asianで生成):

処理後(Z Image img2img使用):

男性の陰茎に小さな膨らみが見えます。これは私のプロンプトの問題によるものかもしれません。たまに小さなアーチファクトが発生することがあります。もし完全に消せない場合は、Photoshopや類似のソフトで手動で修正してください。
あと、彼女の足の近くに金色のリングが見えることに気づきました。これは、Z Imageが彼女が耳につけていることを認識しているにもかかわらず、プロンプトに「金色の輪っかのイヤリング」と残していたためです。ノイズ低減やプロンプトを調整する際には、このような点に注意してください。
重要:マスクが不十分だと、性器とその周囲の画像部分の連続性が悪くなります。私はマスク作成のプロではないですが、清潔で正確なマスクを作るには時間をかけてください。後で感謝するはずです。
理想的な入力画像
- 半リアルなポートレート
- 良い陰影を持つアニメ風画像
- ある程度の奥行きをもつスタイル化されたアート
- 他のモデルで生成された軽度なフォトリアリスティックなレンダリング
ベース画像がフラットまたは過度にスタイル化されている場合、リアリズムの効果は弱くなります。
ノイズ低減値(Denoise)
0.1 から 0.65 の範囲
もちろん、1.00のノイズ低減が理想ですが、それでは構造と元の画像スタイルが壊れてしまいます。この設定は、調整に時間がかかる部分です。
サンプラー
私は個人的にeuler/simpleを使用しています。他の優れたサンプラー/スケジューラーコンボがあれば、お好みで使ってください。Res_multistepは興味深いです。
ステップ数
9~20
これは完全にあなたの選択です。私は通常12ステップで、結果は非常に素晴らしいです。この範囲を超えると、ほとんど効果の向上が見られず、処理時間が大幅に長くなります。
CFG(クリティカル・ファクター)
1~3
低ノイズのimg2img処理なので、CFGを少し上げても問題ありません。通常の1.00ノイズ低減のtxt2imgのように、画像の要素が「過剰に処理される」ことはほとんどありません。
ワークフロー(通常のimg2imgとマスク付きimg2imgを添付)
以下は、Z-imageでimg2imgを行うために私が作成した現在のワークフローです。Z ImageのAIOチェックポイントを使用しています(もちろん、通常のZ Imageモデルと別々のCLIP/VAEを使用することも可能ですが、その場合はノード接続を再構成してください):
https://huggingface.co/SeeSee21/Z-Image-Turbo-AIO/tree/main
開始前にワークフロー全体を確認してください。メイン画像生成部分、FaceDetailer、HandDetailer、オプションのSkinDetailer、Upscaler、Save Imageが含まれています。カスタムノードが多くてごめんなさいが、私は時間をかけて自分でこのワークフローを構築し、非常にうまく動作しています。
- Load Imageノードに画像を貼り付けます。
- プロンプトやパラメータを設定します。
- KSamplerのノイズ低減値を任意の値に変更します(最初は0.40など、低めから始めましょう)。
- 実行します。
- プロンプトやCFGを調整して、満足いく結果になるまで試行錯誤します。
- 少し繊細なので、忍耐強く、このプロセスの仕組みを理解してください。
ヒント
以前にも述べましたが、CFGを積極的に調整して、Z Imageでデフォルトで弱められがちな重要な特徴を強調してください。私はよくCFGを2~3に設定し、「彼女の肌は非常に白い:1.2」のように重み付けタグを使って、超白い肌を引き出します。これは一例です。
- このCFG調整はFaceDetailerノードにも有効です。
初期プロンプトをimg2imgワークフローに転送できます。ただし、修正が必要になる場合が多く、試行錯誤が必要です。私のすべての画像はDanbooruタグに基づいています。そのため、テストレンダリングを見て、Z Imageがプロンプトをどのように誤解しているかを確認し、プロンプトの一部を削除したり、自然言語で書き直したりします。画像やプロンプトをLLMに投入して、Z Imageがよりよく理解できる強力な自然言語プロンプトを生成することもできます。
私の理解では、すでに完成・アップスケール済みの画像から始めるのがベストです。低解像度の画像からimg2imgを始め、その後で激しくアップスケールすると、バンドリング(帯状のノイズ)などの小さな問題が発生することがあります(私は実際に経験しています)。img2imgは、2つの異なる画像スタイルを「ブレンド」する行為であり、モデル間では影、照明、カラーパレットなどの理解と実装が大きく異なります。そのため、最終画像を丁寧にチェックし、適切な生成パイプラインで修正できた可能性のある欠陥がないか確認するのが良いでしょう。
処理前/処理後の期待値
低ノイズのTurboは、構成や解剖学を置き換えるものではありません。このツールは、既存の画像に、奥行きや質感を理解したリアリズムフィルターをかけるような、自然な仕上げを提供します。
キャラクターはそのまま、デザインもそのまま維持されます。
ただ、よりクリーンでシャープで、より信頼性の高いバージョンになります。
質問、コメント、懸念事項は?
このワークフローについて、またはそれ以外の点について、ご質問やご意見があれば、ぜひコメントしてください。
ちなみに、私はこの分野の専門家ではありません。ただ、この方法がうまく機能することを発見しただけです。このワークフローが最終的かつ完璧であるとは考えていないので、あくまで参考としてご利用ください。