🎼MMAudio + 🎹ACE-Step (Music/Song Gen) Workflow for Videos

详情
下载文件 (1)
关于此版本
模型描述
🤡 I tend to overcomplicate workflow. (Consider this an advance version)
For simpler one, use this:
Reference & Credit :
🔗(NSFW) Dead-Simple MMAudio + RIFE Interpolation Setup for WAN 2.2 I2V
😀SeoulSeeker(CivitAI)
🪁 I was messing with MMAudio, so I decided to drop this workflow here.
12/12/25 - Added wf with ACE-Step (Music/Song Generation)
Fixed Audio from Video.
⚠️8 Custom Nodes Required
⚠️ Subgraphs
⚠️ Only tested in ComfyUI Desktop version
✅ UI Oriented workflow
✅ Audio from Video Upload
✅ Audio from File Upload
✅ 2 MMAudio for Sound/Music Generations
✅ Volume control
✅ Upscaler and/or Frame Interpolation
✅ Watermark/Logo (Comes along with the Video FPS Resampling node(White Rabbit), so might as well.)
✅Condensed Workflow
‼️Custom node ComfyUI-Swwan can cause problems with the workflow. (Make sure to uninstalled it, it has conflict with some of the switches in the workflow)
‼️Disable "Node 2.0".
🎹 Capable of combining all selected options (Audio from Video upload, Audio from File Upload, MMAudio 1, MMAudio 2, ACE-Step)
💡It is recommended to use uninterpolated videos. It is faster. But you still can use any interpolated videos with any fps, it might be slower.
⚠️ If your video is upscaled to a large resolution, it may cause out of memory.
⚠️ When interpolating video in this workflow, the FPS for output is fixed to avoid confusion and complication. (Changing fps = changing duration = affecting MMAudio)
💡It is better to use background music(BGM) from other audio files than to use MMAudio.
(I'm using Ace-Step to generate BGM)
MMAudio is very reactive to your video, because of that, it does not do music very well. For example: a transition in the video might break the flow in the music. It works out fine sometimes with the break, or a smile might create a sound from a horror movie. Sometimes the beats or tunes will follow the actions in the video.
Once in a while, I will use MMAudio for BGM, but will require a ton of tries.
📼Video posted above includes Embedded Workflow. (Download the video, drag into ComyfUI)
Need ComfyUI-VideoHelpSuite custom node to open up workflow from video in ComyfUI.
⌨️Usage:
Drag and drop your video into the "📲Models Loaders & Video Upload" subgraph
Enable Options of what you want at the top of each segment.
Write simple prompt for 🎼MMAUdio or/and Upload music file or audio from video.
3a. Click on "🎲New Fixed Random" for a new sound generation for 🎼MMAudio.
▷RUN
Preview video in "🎥🎼Video Combine"
Repeat 3a. if you want a new sound from 🎼MMAUdio and hit ▷RUN.
Select option to "🎞️Frame Interpolation", "📐Upscaler" and/or ":💾Save Output" and ▷RUN
💿Installing ComfyUI-MMAudio
1. Git Clone
Go to your ComfyUI, custom node directory.
🗂️ ComfyUI\custom_nodes
Windows:
Git clone the ComfyUI-MMAudio into the directory.
Right-click in the directory and select "Open Terminal"
Enter:
git clone https://github.com/kijai/ComfyUI-MMAudio.git2. Installing
For Desktop:
Open ComfyUI,
Click on "🧩Manager" in ComfyUI.
Click on "Install Missing Custom Nodes".
Select "Try Fix" on ComfyUI-MMAudio.
Restart ComfyUI.
For Portable:
Go to your "python_embeded" folder.
Right-click in the directory and select "Open Terminal"
Enter:
python.exe -m pip install -r ComfyUI\custom_nodes\ComfyUI-MMAudio\requirements.txt📥MMAudio Models/Files Download Link
⚠️Create a folder in "🗂️: ComfyUI/models/" folder and name it "mmaudio". Put all the files in there.
mmaudio_model (Can get both or either, I used both, depending on what audio I want)
SFW Model (Not so good at NSFW Stuff)
NSFW Model (Not so good at SFW Stuff)
🗂️: ComfyUI/models/mmaudio
📐Upscaler Model Download Link
📐2x Upscaler Models
🗂️: ComfyUI/models/upscale_models
(recommended to use a 2x upscale model, you can still use other 4x upscale model, but it might take longer to upscale)
🎹ACE-Step Model Download Link
When you load the workflow in, Comfyui will notify you of missing model. You can download directly from ComyfUI or use the link below:
🎹 ace_step_v1_3.5b.safetensors
🗂️: ComfyUI/models/checkpoints
🗺️Guide
📲Models Loaders & Video Upload
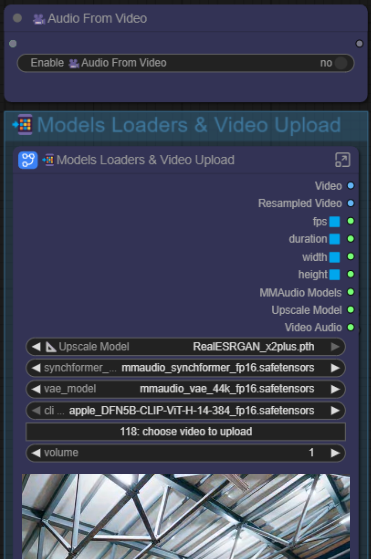
🎥Audio From Video
Enable to use with uploaded video's audio.
Disable to use uploaded video only.
📲Models Loaders & Video Upload
- Drag and Drop video into the subgraph to upload your video, a video preview will be shown below the subgraph, hover the mouse on the video preview and you can hear the audio, if any.📐Upscale Model - Select your upscale model here.
MMAudio synchformer_model - mmaudio_synchformer_fp16.safetensors
MMAudio vae_model - mmaudio_vae_44k_fp16.safetensors
MMAudio clip_model - apple_DFN5B-CLIP-ViT-H-14-384_fp16.safetensors
choose video to upload - You can also click here to open up a window to select video to upload or you can just drag and drop your video in this subgraph.
Volume (⚠️Preview in this node does not preview the adjusted volume)
- Set the volume of the video's audio. (in decimal)
- 1 = default
- negative = decrease volume (example -6)
- more than 1 = increase volume
📤Load Audio From Folder
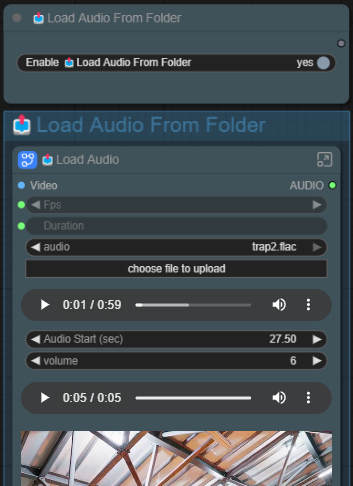 ⚠️You will need to click on "choose file to upload" in order to upload an audio/video file.
⚠️You will need to click on "choose file to upload" in order to upload an audio/video file.
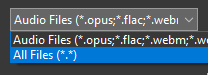
To upload a video with audio (only load audio from video) or mp3 files, select "All Files(*.*)".
📤Load Audio From Folder
Enable to use audio file from folder.
📤Load Audio
choose file to upload - Click her to upload an audio file or video with audio file.
Audio preview (Top) - Only appears after you upload an audio file, preview the full length of the audio uploaded.
Audio Start - Input which seconds to start the audio .
0 = from start.
If you set, for example 6.50, it will trim off anything before 6.5 sec of the audio.
The end will be trim off based on your video's duration.Volume - Set the volume of the video's audio (in decimal)
1 = default,
negative = decrease volume (example -6),
more than 1 = increase volumeAudio preview (Bottom) - Only appears when the workflow is ▷RUN. Preview the trimmed off audio with adjusted volume.
💡Click on the "⋮ " (three dots )and you will have an option to save the trimmed audio.Video Preview - Only appears after the workflow is ▷RUN. Preview the video used + audio upload with adjusted volume. Hover the mouse on the video preview and you can hear the audio.
🎹ACE-Step
 ACE Step use normal KSampler to generate music. You can go into the subgraph if you want to change the sampler or scheduler.
ACE Step use normal KSampler to generate music. You can go into the subgraph if you want to change the sampler or scheduler.
🎹ACE-Step
Enable to use 🎹ACE-Step.
ckpt_name: ace_step_v1_3.5b.safetensors
Shift & Steps - You can leave this as it is, unless you want to experiment.
Vocal Volume - Increase the vocal volume if there is any.
⚠️Need to be set to 1, even there is no vocal or the song is just instrumental.seconds - Duration of the song/music. (recommended at 60)
⚠️ At least 20-30 sec. Its better to have a longer duration, and later set the starting point for your music. ACE-Step will not generate properly if the duration is too short (5-10 secs is too short)Audio preview (Top) - Only appears after the workflow is ▷RUN, preview the full length of the song generated by ACE-Step.
💡Click on the "⋮ " (three dots )and you will have an option to save the generated song/music.
💡Use this to search for where you want your music to start.🎲New Fixed Random & Seed - Click on this and ▷RUN to get a new seed for a new song/music generation.
Audio Start - Input which seconds to start the audio .
0 = from start.
If you set, for example 6.50, it will trim off anything before 6.5 sec of the audio.
The end will be trim off based on your video's duration.Volume - Set the volume of the video's audio (in decimal)
1 = default,
negative = decrease volume (example -6),
more than 1 = increase volumeAudio preview (Bottom) - Only appears when the workflow is ▷RUN. Preview the trimmed off audio with adjusted volume.
💡Click on the "⋮ " (three dots )and you will have an option to save the trimmed audio.Positive Prompt for ACE-Step - Write prompts for music genres, instruments, style or mood.
Music Structure/Lyrics Prompt for ACE-Step - Construct the song and add lyrics. or set it as instrumental.
💡For more examples for prompts and structures, go to : https://ace-step.github.io/Video Preview - Only appears when the workflow is ▷RUN. Preview the video used + generated ACE-Step music/song with adjusted volume. Hover the mouse on the video preview and you can hear the audio.
🎼First & Second MMAudio
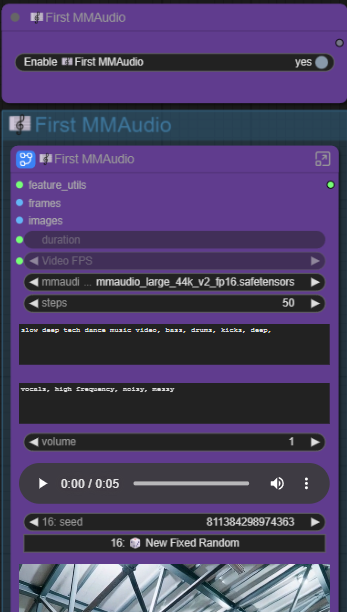
🎼First/Second MMAudio
Enable to use MMAudio.
🎼MMAudio
mmaudio_model - Here can choose/swap out the MMAudio model.
steps - 50 steps give good enough quality and very fast.
Positive Prompt (Top) & Negative Prompt (Bottom)
- Write your prompts here. you can keep it simple. A few words or tokens are good enough. Add audio prompt if the audio does not produce it. Or add negative prompt if there are audio sound you don't want in it.
-Example:
If your video only have a person playing guitar but there are no audio for drums. Write/Add it in the prompt: "drums" or "drums, snare".
If you don't want the person to sing, you can put "vocals" in the negative prompt.
-⚠️It is not perfect, might require and few tries.
- (Don't ask me for prompts, I'm still figuring out what works and what is placebo.)Volume - Set the volume of the video's audio (in decimal)
1 = default,
negative = decrease volume (example -6),
more than 1 = increase volumeAudio Preview - Only appears when the workflow is ▷RUN. You can preview the generated MMAudio sound with adjusted volume.
💡Click on the "⋮ " (three dots )and you will have an option to save the generated audio.🎲New Fixed Random & Seed - Click on this and ▷RUN to get a new seed for a new sound generation.
Video Preview - Only appears when the workflow is ▷RUN. Preview the video used + generated MMAudio sound with adjusted volume. Hover the mouse on the video preview and you can hear the audio.
🎥🎼Video Combine
Preview the output of the video + combined audio used/generated.
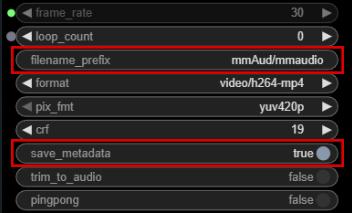
filename_prefix
- Here you can set the video output filename. Adding a "/" will create a folder.The examples: "mmAud/mmaudio" .
Video will be save into "🗂️:ComfyUI/output/mmAud/" and the filename will be "mmaudio_00001-audio.mp4". ComfyUI will automatically add a numbering system at the end of the filename and add "-audio" in the end of the file to indicate the video is with audio.All Generated videos will be save into 🗂️:ComfyUI/output.
save_metadata
- Enable to save the workflow at the state when ▷RUN. Drag and drop the output video with saved meta in ComfyUI and every input/state of that video's workflow will be loaded.
- Disable to empty the workflow metadata.
💡The video combine node will save 3 outputs when saving a video with audio. (video with audio, video only, first frame).
To reduce clutter in your output folder:
Go to ComfyUI Settings.
Look for 🎥🅥🅗🅢 on the left and select it.
Disable: (on the right, top 2 options)
"Keep required intermediate files after successful execution" (this save video with no audio if you generated a video with audio. With this disable, video only output will be saved, don't worry.)
"Save png of first frame for metadata" (if you disable save_metadata above, you can enable this to retrieve the workflow from the png - first frame)
🎞️ 📐🦄💾Options
💡You can disable these options when drafting for your sound/music.
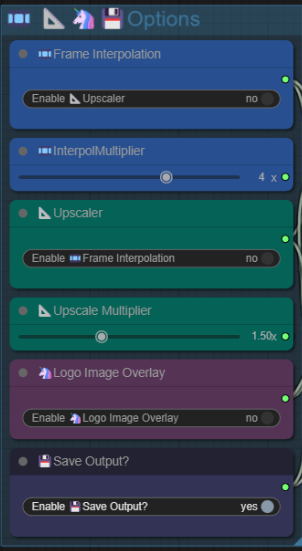
🎞️Interpol Multiplier (Enable/Disable)
- Frame interpolation to make video look smoother by filling up frames in between of video frames.
- 3-4x Multiplier = very smooth.
- 2x Multiplier = slightly smooth, cinematic feel.
- Interpolate Multiplier = how many frame to fill up in between original video frames.
- A 5sec video - 81 Frames, with 4x Multiplier, video will result in 321 total frames.
- A 5sec video - 81 Frames, with 3x Multiplier, video will result in 241 total frames.📐Upscaler (Enable/Disable)
Input/Adjust the final video output dimension by upscale factor.
Example: 720x960 - 1.5x =1080x1440 - 2x = 1440x1920🦄Logo Image Overlay (Enable/Disable)
- Add logo/watermark for you video.💾Save Output? (Enable/Disable)
- Enable and ▷RUN to save your used video + audio outcome.
💡You can disable 1st when drafting, in order to reduce clutter in your output folder.
💡Or, you can just leave it enable (if you tend to forget), and prune your own output folder.
🦄Logo Overlay (Watermark)
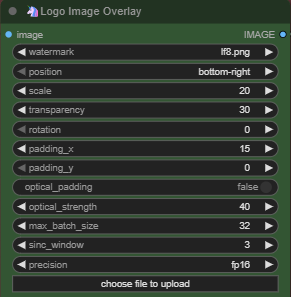
Enable to watermark your videos.
Drag and drop your logo/watermark image into this.
Support images with transparency backgroundSelect the position you want the logo/watermark to be
Scale the size of your logo/watermark
Transparency - Adjust the opacity of you logo/watermark
Rotation - If you want your logo/watermark to be tilted
Padding X - How much spacing for the logo/watermark to be offset from the horizontal side
Padding Y - How much spacing for the logo/watermark to be offset from the vertical side
Leave the rest of the settings as it is.
🧩Custom Node:
rgthree-comfy
ComfyUI-East-Use
ComfyUI-KJNodes
ComfyUI-VideoHelpSuite
ComfyUI-Frame-Interpolation
ComfyUI-mxToolkit
WhiteRabbit
ComfyUI-MMAudio