ComfyUI Workflows





詳細
ファイルをダウンロード
モデル説明
BGMasking V1:
インストール:
https://github.com/Fannovel16/comfy_controlnet_preprocessors をインストール
Fannovel16 さんへ感謝
ダウンロード:
/model/9251/controlnet-pre-trained-models
Cannyは必須、Depthはオプション
または差分モデル(自分のモデルを入力として使用可能、さらに正確な結果が得られる可能性あり)
/model/9868/controlnet-pre-trained-difference-models
これらのControlNetモデルを ComfyUI/models/controlnet に配置
Ally さんへ感謝
添付ファイルをダウンロードし、ComfyUI/custom_nodes にノードを配置
以下を含んでいます(すべてではないが):
/model/20793/was-node-suites-comfyui
ComfyUIを再起動
使い方:
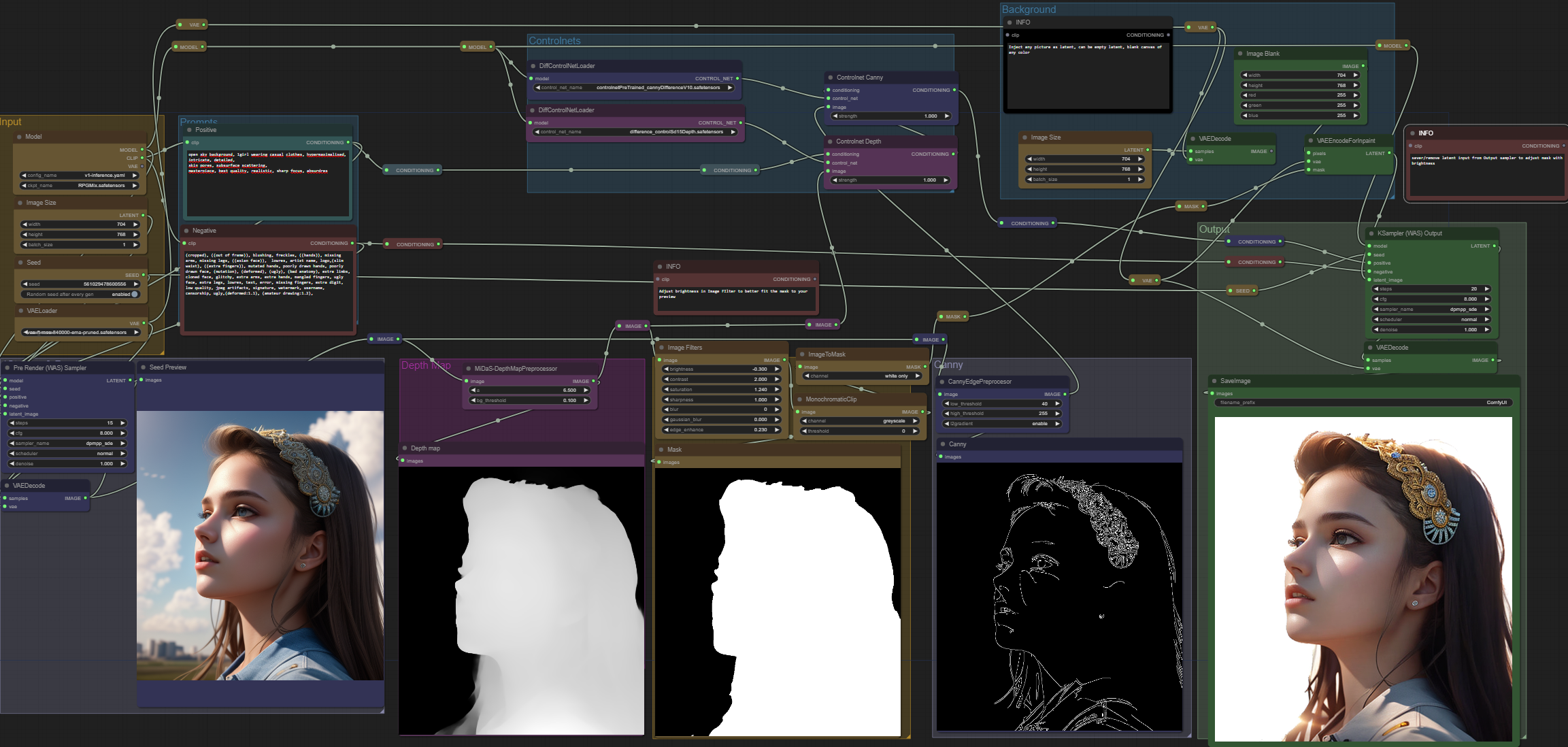
まず、出力サンプラーの潜在変数入力(latent input)を切断してください。
希望するプロンプトを生成します。"open sky background" を加えると、シーン内の他の物体が混入しにくくなります。
画像フィルタの明るさを調整してください。テストでは -0.200 以下が効果的でした。特にうねり毛や、壁などの物体に体を預けるようなポーズは問題になりやすいです。
立ち姿で短くまっすぐな髪のスタイルが非常に効果的です。
明るさの調整の目的は、深さマップをある程度制限し、被写体にピッタリ合うマスクを作るためです。
背景画像を選択します。元の潜在変数画像でも、ノードで作成した空の画像でも、あるいは読み込んだ画像でも構いません。
あるいは、黄色のノードの間にある別の画像フィルタを追加し、少しブラーをかけることで、被写体と新しい背景の間のなめらかな融合が可能になります。
マスクの見た目が満足いくらになったら、VAEEncodeForInpaint 潜在変数出力を改めて Ksampler (WAS) 出力に接続し、プロンプトをキューに追加してください。
これを行うには Canny ControlNetが必要です。HEDやNormalmapも試しましたが、Cannyが最も効果的でした。
被写体によっては、別のControlNetタイプが必要になる場合があります。
Cannyから別のControlNetに切り替えるには、事前に前処理を切り替えて、使用目的に合ったControlNetをインストールする必要があります。
Depth ControlNetの適用は任意です。強度によって出力にわずかな3D効果が加わります。
アニメや絵画といった厳密に2Dで作業する場合、Depth ControlNetを飛ばすことができます。
単にDepth ControlNetの条件を削除し、その出力をCanny ControlNetに入力すればよいです。しかしながら、Canny ControlNetがないと、出力生成はシードプレビューと大きく異なったものになります。
入出力を明確にするために、多くのリルーティングノードを追加しました。
automatic1111でこのワークフローを再現するには、多くの手作業が必要です。第3者ツールを使ってマスクを作成しても同様です。したがって、ComfyUIを使う方法は非常に便利です。
免責事項:追加した背景の一部の色が最終画像にわずかに漏れ込む場合があります。
BGRemoval V1:
必要条件:
https://github.com/Fannovel16/comfy_controlnet_preprocessors
/model/9251/controlnet-pre-trained-models
(OpenPoseとDepthモデル)
推奨(オプション):
https://civitai.com/api/download/models/25829
F222やProtogenなど、いくつかの他のモデルでもテスト済み。
以下の説明と手順は、ワークフロー内のテキストノードにも含まれています:
ロード追加ノードで、異なる「マスク」を使用したこともあります。結果は大きく異なりましたが、すべて背景が返ってきました。同じマスクでも色を変えると結果も変わります。
今回は、完全な黒背景上に作られた白のグラデーションのみを使用しています。
AIがノイズの配分のためのガイドとして使用していると推測します。
緑の条件結合ノードでは、入力順序が実際に重要です。「Depth Strength」の出力は下の入力に接続する必要があります。
このノードの上の入力は、ポーズ付きのCLIPポジティブから来ています。
青のサンプラー部分は、単に深度マップを生成し、それを潜在変数にエンコードして、シアンの出力サンプラー用の潜在変数入力として使用するだけです。
緑の画像スケールに関しては、オリジナル画像サイズに合わせて、クループを「オフ」にすることをおすすめします。
DEPTH STRENGTHの設定は最終画像の見た目に大きく影響します。あまりに高すぎると、オリジナルのポジティブプロンプトの重みが失われます。
場合によっては0からスタートしてもよいですが、背景が現れる場合は、1まで上げてもよいです(低い方がより良い結果を得られます)。
まだでなければ、以下のFannovelの前処理ツールをダウンロード・インストールすることをおすすめします:
https://github.com/Fannovel16/comfy_controlnet_preprocessors
シードノードおよびシード入力のあるサンプラーはここからダウンロード:
https://civitai.com/api/download/models/25829
OpenPoseおよびDepthモデルはここにあります:
/model/9251/controlnet-pre-trained-models
WASのDepth前処理を使用する試みも可能ですが、私はそれだと深さマップが細かくなりすぎたり、この用途に有用なしきい値が得られなかったと感じました。
使用しているモデルはここにあります: