aimaginedworlds: Z-Image Turbo LoRA Guide (Best Version)





















詳細
ファイルをダウンロード
モデル説明
最良の結果: V1アダプター学習
スタイル: アニメ / イラスト
トリガーワード: aimaginedworlds
ベースモデル: Tongyi-MAI/Z-Image-Turbo
📖 私の物語: 「完璧」なLoRAへの道のり
私は、このLoRAの学習経験を、最終的な成果だけでなく、全過程を共有したいと思います。なぜなら、透明性がコミュニティの学びに役立つと信じているからです。
🚫 試行1: 1000枚の画像データセット + V2アダプター
私は大規模なスタートを切りました。データが多ければ結果も良くなると考え、1000枚の画像を集め、最新のアダプターを使用しました:
結果: 完全な失敗。 LoRAはアニメスタイルをまったく捉えられず、出力は汎用的で、学習データの個性が一切反映されていませんでした。
⚠️ 試行2: 精選した100枚以上の画像データセット + V2アダプター
私は「量より質」であることに気づきました。詳細なキャプションが付いた、約118枚の高品質なアニメ画像を厳選してデータセットを構築しました。
- 結果: 改善されたが、まだ満足できない。 V2アダプターは強いスタイル転送に苦戦しているように見えました。出力は「まあまあ」でしたが、目指していた鮮やかなアニメ的美観には程遠かったです。
🔄 試行3: Z-Image-De-Turboの使用
私は方針を完全に変更しました。非ターボベースモデルで学習すれば、より制御できるのではないかと考えました:
結果: 特に目立った成果なし。 技術的には可能でしたが、私が求めていた鮮やかでスタイル化されたアニメ風の外観は得られませんでした。「フラット」に感じられました。
✅ 試行4: V1アダプター——勝者!
絶望的な気持ちで、私はオリジナルのV1アダプターに戻りました。そして、何が起きたと思いますか?
アダプター:
ostris/zimage_turbo_training_adapter_v1.safetensorsデータセット: 精選した118枚のアニメ画像
結果: 驚異的! これがブレイクスルーでした。V1アダプターに適切な設定を組み合わせることで、ついにアニメスタイルを美しく捉えることに成功しました。高速推論、強いスタイル、一貫した品質。
時として、「古い」バージョンの方がより優れているのです。
💸 実際のコスト: この学習にかかった費用
LoRAの学習は無料ではありません。この成果に至るまで、Modalクラウドコンピューティングで私が支払った費用を正直にまとめます:
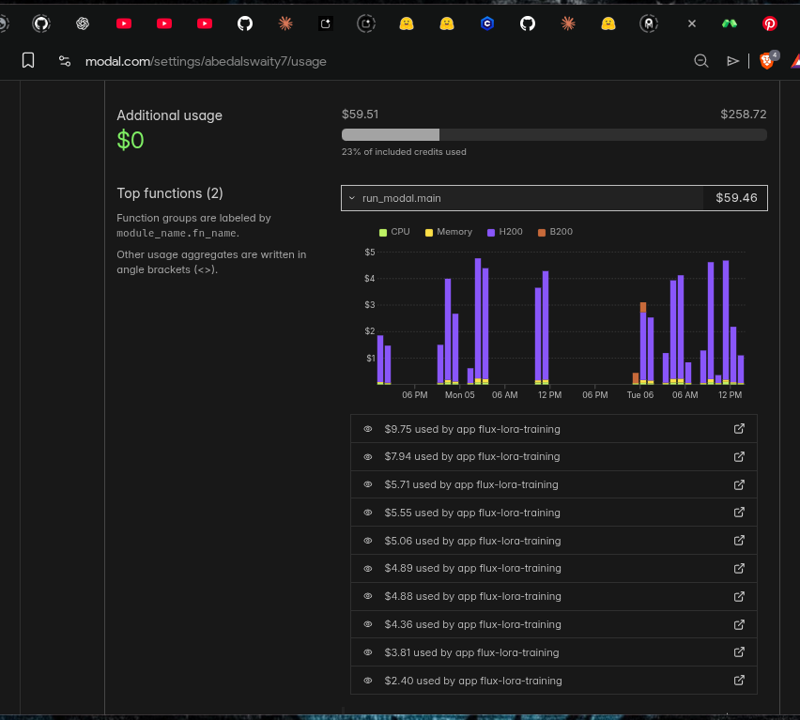
使用GPU: NVIDIA H200
合計学習回数: 10回以上
合計コスト: 約$60
投入時間: 数日間の実験...
この成果を得るまで、$60と、無数の時間をかけてアダプターの比較、ハイパーパラメータの調整、学習ジョブの完了を待つという試行錯誤を繰り返しました。
⚙️ 最適な設定
以下は、最良の結果を生み出した正確な設定です。ご自身の学習の出発点としてご自由にお使いください!
job: "extension"
config:
name: "aimaginedworlds_turbo"
process:
- type: "diffusion_trainer"
training_folder: "/root/ai-toolkit/modal_output"
device: "cuda"
trigger_word: "aimaginedworlds"
network:
type: "lora"
linear: 32
linear_alpha: 32
conv: 16
conv_alpha: 16
save:
dtype: "bf16"
save_every: 250
max_step_saves_to_keep: 4
datasets:
- folder_path: "/root/ai-toolkit/training_data/aimaginedworlds"
caption_ext: "txt"
caption_dropout_rate: 0.05
resolution:
- 512
- 768
- 1024
train:
batch_size: 1
steps: 5000
gradient_checkpointing: true
noise_scheduler: "flowmatch"
optimizer: "adamw8bit"
lr: 0.0001
dtype: "bf16"
model:
name_or_path: "Tongyi-MAI/Z-Image-Turbo"
arch: "zimage:turbo"
assistant_lora_path: "ostris/zimage_turbo_training_adapter/zimage_turbo_training_adapter_v1.safetensors"
sample:
sampler: "flowmatch"
sample_every: 250
guidance_scale: 1
sample_steps: 8
重要な設定:
- Rank 32 / Alpha 32: オーバーフィッティングを避けつつスタイルを最適化するバランスの取れたポイント。
- V1アダプター: その秘密の鍵!
- 5000ステップ: 完全な収束に十分なステップ数。
- FlowMatchスケジューラー: Z-Image Turboにネイティブ対応。
🚀 このLoRAの使い方
このLoRAはアニメ/イラストスタイルに特化して学習されています。プロンプトをシンプルに保ち、トリガーワードに重きを置くことで、最も効果的に機能します。
✨ トリガーワード
プロンプトの最初に aimaginedworlds を追加するだけです:
aimaginedworlds, 青い髪の少女がカフェで座っている
これだけでOK!複雑なプロンプティングは不要です。スタイルはすでに組み込まれています。
🔌 推奨: Z-Image-Turboプロンプトテンプレートノード
このLoRAの最適な結果を得るには、私のComfyUI-OllamaGeminiノードと新しいZ-Image-Turboプロンプトテンプレートをご使用ください:
Flux、Veo3.1、Qwen、Gemini、Banana Pro、Imagen4などを使って、魔法のようなプロンプティングを実現します!
❤️ 私の活動をサポートしてください
高品質なLoRAの作成には、実際の時間、労力、お金がかかります。上記のように、このプロジェクトだけでもクラウドコンピューティングで約$60、数日間の実験を費やしました。
このLoRAが美しい画像の作成に役立つなら、ぜひ私の活動をサポートしてください。たとえ小さな支援でも、以下のようなことに役立ちます:
- 🖥️ 次のモデルのクラウドコンピューティング費用を賄う
- 🎨 より高品質なアニメLoRAを学習する
- 📚 経験をコミュニティと共有する
あなたの支援は、私にとって世界と同じくらいの意味を持ち、継続の原動力になります!
🛠️ 使用ツールとクレジット
このLoRAは、Ostrisが開発した素晴らしいAI-Toolkitを使用して学習しました:
🔗 https://github.com/ostris/ai-toolkit
ご自身でLoRAを学習したい方は、ぜひチェックしてください。強力で、丁寧にドキュメント化され、積極的にメンテナンスされています!
🙏 あなたができること
もし今回の内容が役立ったなら、以下のようにサポートしてください:
💸 PayPalで支援 — GPUコストをカバーするお手伝いを!
📢 あなたの作品を共有 — 作成した作品を私にタグしてください!
愛と挫折と、膨大なGPU時間で作られました。