ComfyUI Local LLM Qwen Prompt Refiner (Offline LLM Node)


详情
下载文件
关于此版本
模型描述
ComfyUI 的本地 Qwen LLM 加载器与思维提示优化器
使用 safetensors 格式完全离线加载任何 Qwen 模型(如 Qwen3-4B-Thinking-2507)。非常适合在完全控制下优化 Stable Diffusion 提示词:可自定义指令、可见的思维链输出、固定种子以确保结果一致,以及可选的完全内存释放功能,使用后释放 VRAM。
无需 API,无速率限制,与重型生成工作流并行运行时也不会出现 OOM 问题。
只需将模型文件放入 models/qwen/model-main-folder-goes-here/repo-files-goes-here,重启 ComfyUI,即可本地创作更优质的提示词。
模型放置位置:
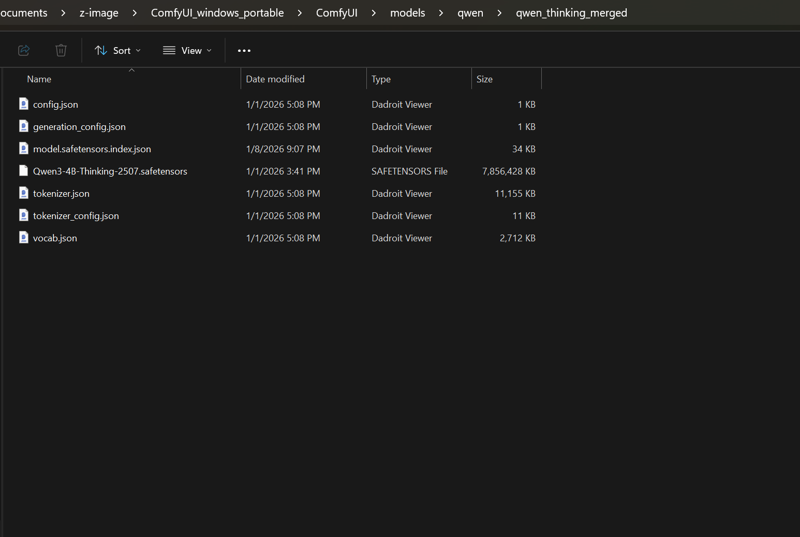
子文件夹内应包含的内容:
此模型生成的图像
未找到图像。