Qwen3-TTS + RVC Ultimate Pack V2 (Director's Mode)


Details
Download Files (1)
About this version
Model description
# 🎬 UPDATE V2.0 (Jan 29, 2026) - DIRECTOR'S MODE
The Ultimate Voice Workflow just got a massive upgrade.
Now integrating RVC (Retrieval-based Voice Conversion) directly inside ComfyUI.
🚀 3 Modes in 1 Workflow
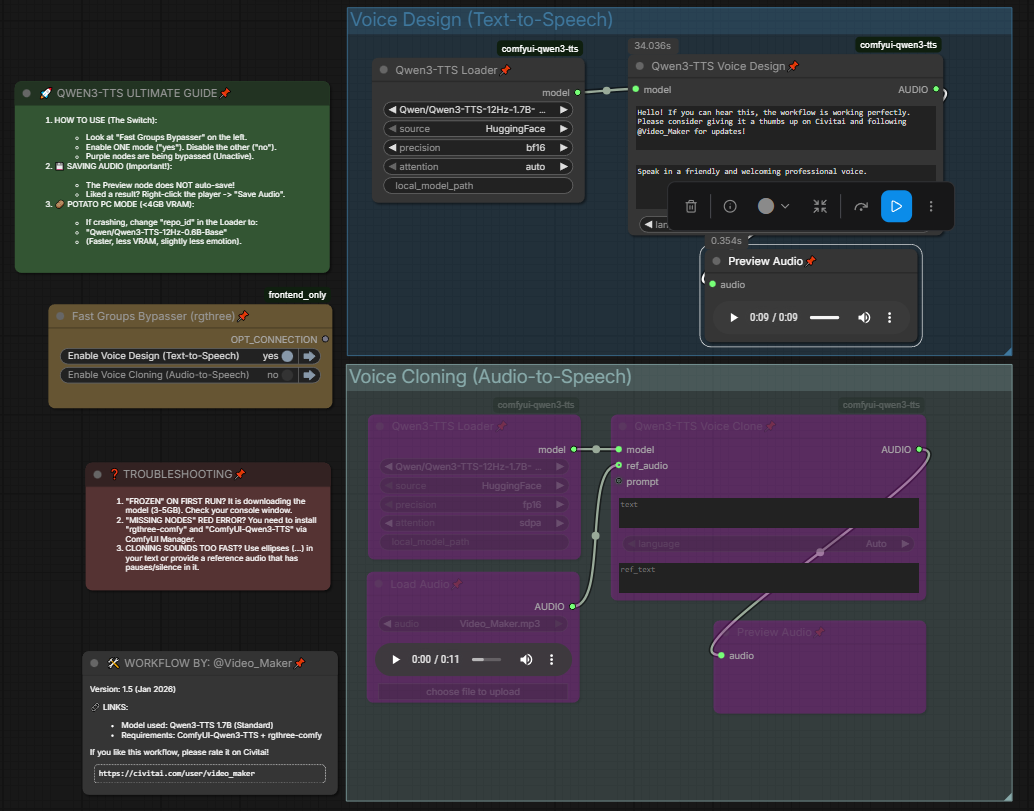
This isn't just an update; it's the ultimate pack. You can switch between 3 distinct modes using the Fast Bypasser:
🎙️ Voice Design (Text-to-Speech): Create high-quality voices from scratch using prompts.
👯 Classic Cloning (Audio-to-Speech): The original V1 method. Quick and easy cloning using a reference audio file.
🎭 Director's Mode (Qwen + RVC): [NEW] The advanced mode where you design the performance and paint the voice texture using RVC models.
(Watch the video above for a full tutorial on how to use the Director's Mode)
---
### 🤯 The Problem with Standard Cloning
Usually, when you clone a voice, the AI tries to copy the accent and the tone of the reference audio.
* If your reference is boring, the result is boring.
* If your reference has a heavy accent, the result will have it too.
### 💡 The Solution: Director's Mode (V2)
This workflow separates the Acting from the Timbre.
1. Direct the Actor: Use Qwen3's "Voice Design" node to generate the perfect performance (whispers, shouts, sadness, speed) using a generic high-quality voice.
2. Apply the Mask: The workflow automatically feeds that performance into RVC, which applies the target character's voice (e.g., Michael Jackson, Darth Vader, or your own) over the performance.
Result: Perfect acting, perfect character voice, zero accent bleed.
---
## 🚀 What's New in V2?
* ✅ RVC Integration: Load .pth and .index models directly in ComfyUI.
* ✅ Director's Mode: A specific group set up to pipe Qwen3 output into RVC.
* ✅ Smart Settings: Optimized Pitch, Index, and Protection settings for realistic results.
* ✅ Low VRAM Optimized: Still runs perfectly on a GTX 1060 (6GB).
* ✅ Bypass Groups: Easily toggle RVC on/off to save resources while testing prompts.
---
## ⚠️ BEFORE YOU RUN (Important)
When you load this workflow, some nodes might turn RED. This is normal!
It happens because the workflow is looking for my audio files and my RVC models.
To fix it:
1. Load Audio Node: Upload your own reference audio.
2. Load RVC Model Node: Select your own .pth and .index files (you need to download RVC voice models and put them in your ComfyUI/models/rvc folder).
---
## ⚙️ Requirements
To make the magic happen, you need these Custom Nodes (Install via ComfyUI Manager):
1. ComfyUI-Qwen3-TTS (by DarioFT) - The brain.
2. ComfyUI-RVC (or similar RVC suite) - The voice changer.
3. rgthree-comfy - For the bypass switches.
---
## 💡 How to Use (Step-by-Step)
1. Voice Design (Text-to-Speech) - (Blue Group)
- Type your text.
- Describe the acting in the prompt box (e.g., "A terrified whisper, breathing heavily").
- Generate the audio to check the performance.
2. RVC (Director's Mode) - (Purple Group)
- Enable the RVC Group using the Fast Bypasser on the left.
- Load your target voice model (e.g., Deadpool.pth).
- 🧠 SMART SETTINGS (Don't guess!):
- I included a note node inside the workflow called "🤔 How to use this".
- Copy the prompt from that note and paste it into ChatGPT, Gemini, or Grok.
- The LLM will analyze your character and give you the exact Pitch, Index, and Qwen Instructions to get the best result.
- Watch the video at 03:05 to see this in action!
---
### ❤️ Support the Project
If this workflow saved you time or improved your projects:
👍 *Thumbs Up** and Review (It helps a lot with visibility!)
⚡ *Buzz:** If you are feeling generous, some Buzz helps me test new models and create V3!
Enjoy being the Director!
@Video_Maker