Iori Yoshizuki ( diag-oft experiment version ) - I''s





















詳細
ファイルをダウンロード (2)
モデル説明
This resulted once again from a bout of curiosity for this new "LORA" type. The result? It seems an in-between IA3 and a LORA in quality. You can compare against the IA3 version, the LORA version or the LOCON version. All of them use the same dataset only with changes in repetitions to keep them at 8 epochs total.
Image wise it looks serviceable reflecting the dataset while not getting much "creativity" from the training model. Pretty much an in between AI3 and a LORA.
Here's my analysis of pros and cons
Pro:
As it refrains from overwriting previous training, it is a bit harder to overcook.
Small-ish as it is trained with an equivalent of dim 2
relatively quick to train with prodigy it requires 150~200 steps per epoch per concept. I got good results in the 5th epoch(using 300 steps per epoch) which remained stable until the 8th epoch. each iteration takes about 1.58 times a LORA iteration step so that lowers the gains somewhat.
Cons:
It is more sensitive to shortcomings of the dataset that normally get filled by the model(missing angles, low hair detail, fabric textures, low color, blurriness)
The quality/training-time ratio is not very favorable as IA3 is faster and LORA/LOCON look better.
Conclusion:
At the moment Diag-OFT seems to just be another addition to the Lycoris zoo. Nothing exotic nor particularly exciting other than it being harder to overcook.
I will add the dataset, previous epochs, training TOML file and an XYZ file comparing the results of 6 different models and all 8 epochs.
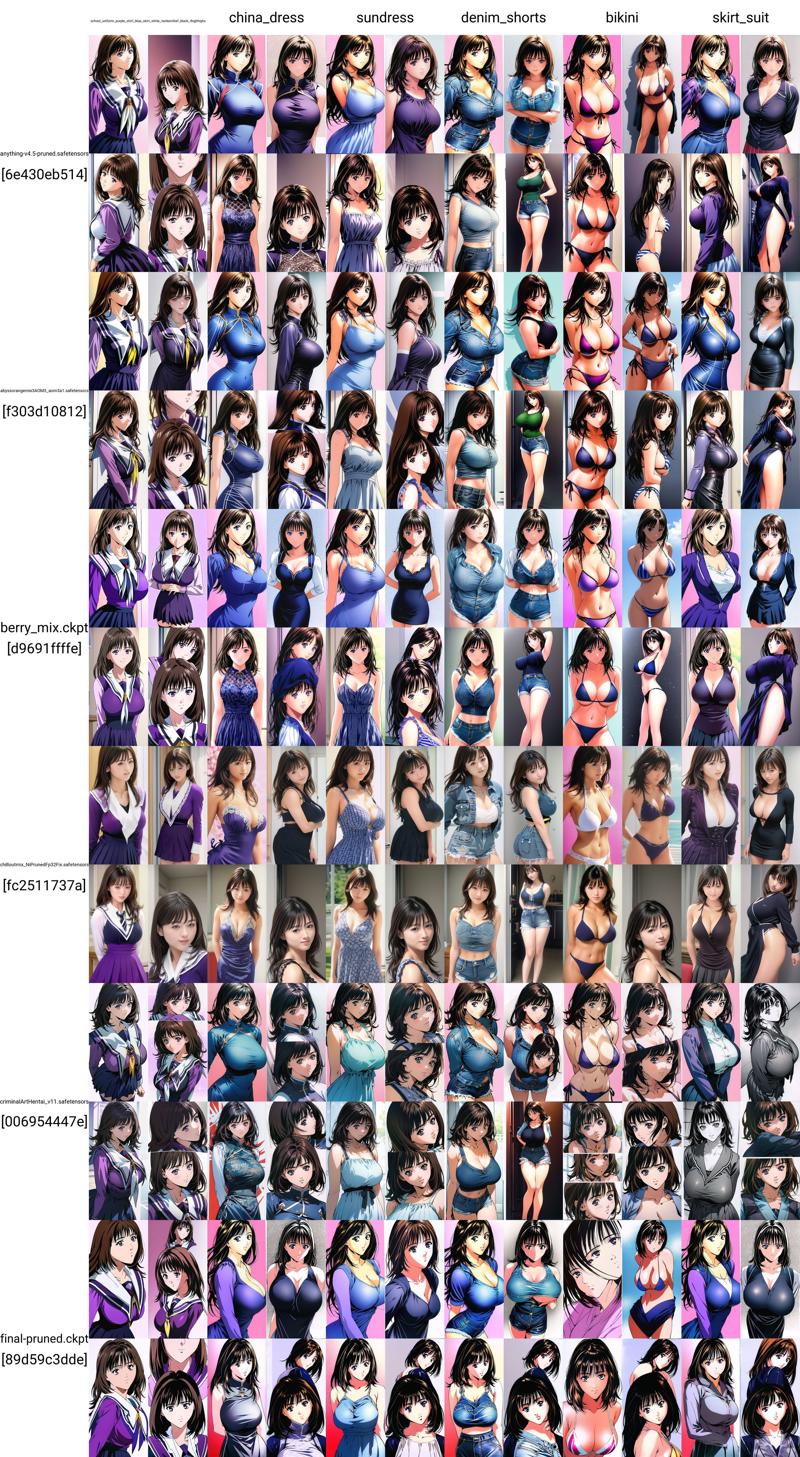

Btw got good results using: <lora:yoshizuki_ioriV5:1> yoshizuki_iori,
The only tagged outfit is:
school_uniform_purple_shirt_blue_skirt_white_neckerchief_black_thighhighs