NEW ERA / LORA / PONY DIFFUSION















詳細
ファイルをダウンロード
このバージョンについて
モデル説明
モデル学習におけるまったく新しい飛躍。当初の目的は、単なるレトロ風モデルを作るのではなく、古いアニメを真似るのではなく、完全に再現する本格的なレトロツールを作ることだった。今回のリリースで、その目標にさらに一歩近づけた。 (BOORUタグを使用)





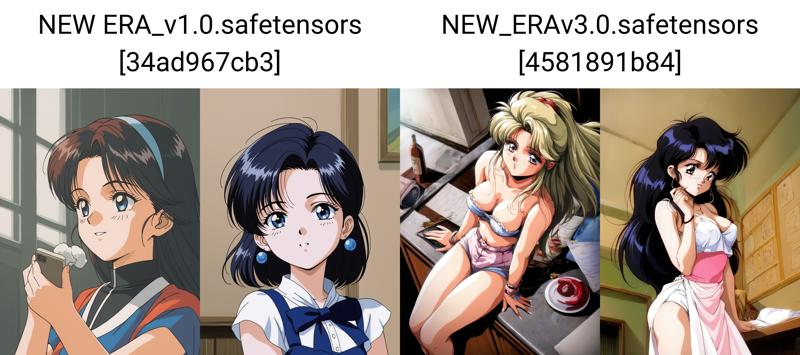
モデルの基盤は、1980〜2000年代のアーティストたちの追加、および膨大な数のキャラクターの収録にあります。
順を追って説明します。
リリースは少し遅れました。完了したLoRAの改善を試み、細部やボリュームを向上させようとしたのですが、現段階でのすべての試みが効果がなく、このテーマをさらに深く調べる必要があると気づいたからです。しかしその結果は、初版とは比べ物にならないほど優れています。モデルよりもLoRAの方が良いの?とおっしゃるかもしれませんね。簡単です。まず、訓練の際、すべてのVRAMを利用して、最良の結果を得ようとしたのです。私の計算では、最適なLoRA(あるいはモデル)には約60〜70GBのVRAMが必要ですが、24GBでは不足しています。しかし、ニューラルネットワークがキャラクター、とりわけそのスタイルを記憶し始めるには十分であり、特に異様な顔、目、鼻、非標準的な体型まで含め、記憶できるようになったのです。このプロセスはさらに改善可能だと信じていますが、現時点での最高の成果です。
LoRAウェイト: 0.7〜1(ウェイト1では解剖学的な問題が発生するため注意)
CFGスケール: 3〜4 (即時アラート!CFGスケール3を使用してください。高すぎるCFGスケールによるアートの褪色問題は未解決のままです。低めに設定してください。低すぎると解剖学的な問題が発生する可能性があるので、下限は守ってください)
プロンプト: retro artstyle, 1girl <lora:NEW ERA_v2.1:0.8>

4th tail (Hentaiモデル) このモデルを使わなければならない非常に重要な点です。私がデータセットを学習したモデルです。他のモデル(オリジナルの pony 以外)では、アーティストやキャラクターの認識に問題が生じ、LoRAへの影響力が高すぎるためご注意ください。
プロンプト: masterpiece, best quality
ネガティブプロンプト: worst quality, low quality, bad hands, fewer digits, extra digits, bad anatomy, english text, engrish text
anime screencap, anime coloring - 二つの強力なトークン。非常に効果的で、画像をアニメのスクリーンショットのように見せてくれます。両方併用しても、別々に使用しても効果が発揮されます。
retro artstyle - 主なレトロトークン。すべてのトレーニング画像にほぼ存在し、1980〜90年代の異なるスタイルを生み出します。
1990s \(style\) - 非常に強力なトークンで、モデルのスタイルを大幅に変化させます。
1980s \(style\) - 現在のところ、前と同程度の強さです(理由は、90年代のスタイルが早めの90年代が多く、その早めの90年代は80年代に似ているため)
2000s \(style\) - まだ完璧ではないですが、00年代にわずかに近づいています。
複数キャラクターの表示:
これ以上、「まるで双子」のように全く同じ感情、肌、髪型、服装を持つキャラクターではなくなりました。
プロンプト:
score_9, source_anime, 3girls, 1980s \(style\), cleavage, by kawarajima kou, smile, open mouth, one eye closed, serious, closed mouth, official art lora:NEW\_ERAv2.1:1

必要に応じて、品質に満足できない場合、pony diffusionの標準トークンもご使用いただけます:
score_9, source_anime, score_8_up, score_7_up, best quality
正直に述べておきたいことがあります。現在、コミュニティ内でニューラルネットワークにアーティスト名を使用することの是非について多くの議論が行われています。率直に、断固として言います——私は気にしない。どんな三文字の変換コードに隠すわけでもなく、人々がモデル内でアーティストを見つけるのを困難にしようとはしません(pony diffusionの作者が行っていることですが、彼の権利であり、非難するつもりはありません。しかし、私はそうしない)。将来、膨大な数のアーティスト、キャラクター、アニメタイトルを、すべてオリジナル名で追加していきます。
現在実装済みのアーティスト(常に「by」から始めてください):
by urushihara satoshi
by danmakuman
by kitazume hiroyuki - 追加予定
by kawarajima kou
by kotobuki tsukasa
by hirano toshihiro - もう少し追加予定
 データセットには他のアーティストも含まれていますが、その影響力はまだ弱いです。
データセットには他のアーティストも含まれていますが、その影響力はまだ弱いです。
現時点では、追加されたキャラクターの一覧はまだ作成していません。それほど多数いるため、まだ時間を使う準備ができていませんが、後日作成する可能性が高いです。
詳細について知りたい方は、私の投稿 NEW_ERAv1.0 を参照してください。
以下は、Stable Diffusion 1.5 を基盤とする旧モデルにのみ適用されます。
小規模なバージョン比較(SD 1.5):
 モデル比較(SD 1.5):
モデル比較(SD 1.5):


90年代のスタイルにようやく手が届いた。多くの困難があり、数十のバージョンを経て、黄金比(最適解)を見つけ出し、今後もこの基盤をもとに更新を続けていく。
お使いのGPUに応じて、Hires Fixを可能な限り使用してください。エラーを回避するために、Hires Fix 2、アップスケーラー Latent (nearest-exact) を使用すると、断然詳細になります。オリジナルに忠実なスタイルで詳細を増やしたい場合は、ノイズ除去強度(Denoising strength)を0.55以上にしないでください。ただし、アーティファクトを避けるために、低すぎる値も避けてください。最適は0.5です。
SD 1.5対応:以下の負のプロンプトとともに、Abyssorangemix3aom3_aom3a3.safetensors モデルを使用してください。
(worst quality, low quality, extra digits:1.4)
他のLoRA と併用可能
auto1111でのLoRAの使い方:
WebUIを更新する(
git pullこちらの方法 を使用または再ダウンロード)ファイルを
stable-diffusion-webui/models/loraにコピーこの動画 のように、LoRAを選択
ウェイトを変更することを確認してください(デフォルトは
:1で、通常は高すぎる)
*Lykonさんの情報を参考にしています
作品をコメント付き・なしで投稿していただければ、私の改善にも役立ちます。どうかよろしくお願いします!
もし私の作品が気に入ったら、上のハートを押してください。とても嬉しいです :3