Geeky Ghost AI Voice Assistant Workflow

詳細
ファイルをダウンロード
このバージョンについて
モデル説明
最新:v4.20(4.2とは混同しないでください。単に4.2を超えたくなかっただけです、すみませんlol)画像を複製するためのAny Nodeを追加。大きな変更ではありませんが、これでwav2lipのシングル画像バージョンが完成しました。つまり、wav2lip動画を作成するにはAny Nodeのおかげで1枚の画像だけで十分です。他の方法もありますが、これはテストであり、うまくいったのでなぜ使わないでしょうか。シングルイメージバージョン。
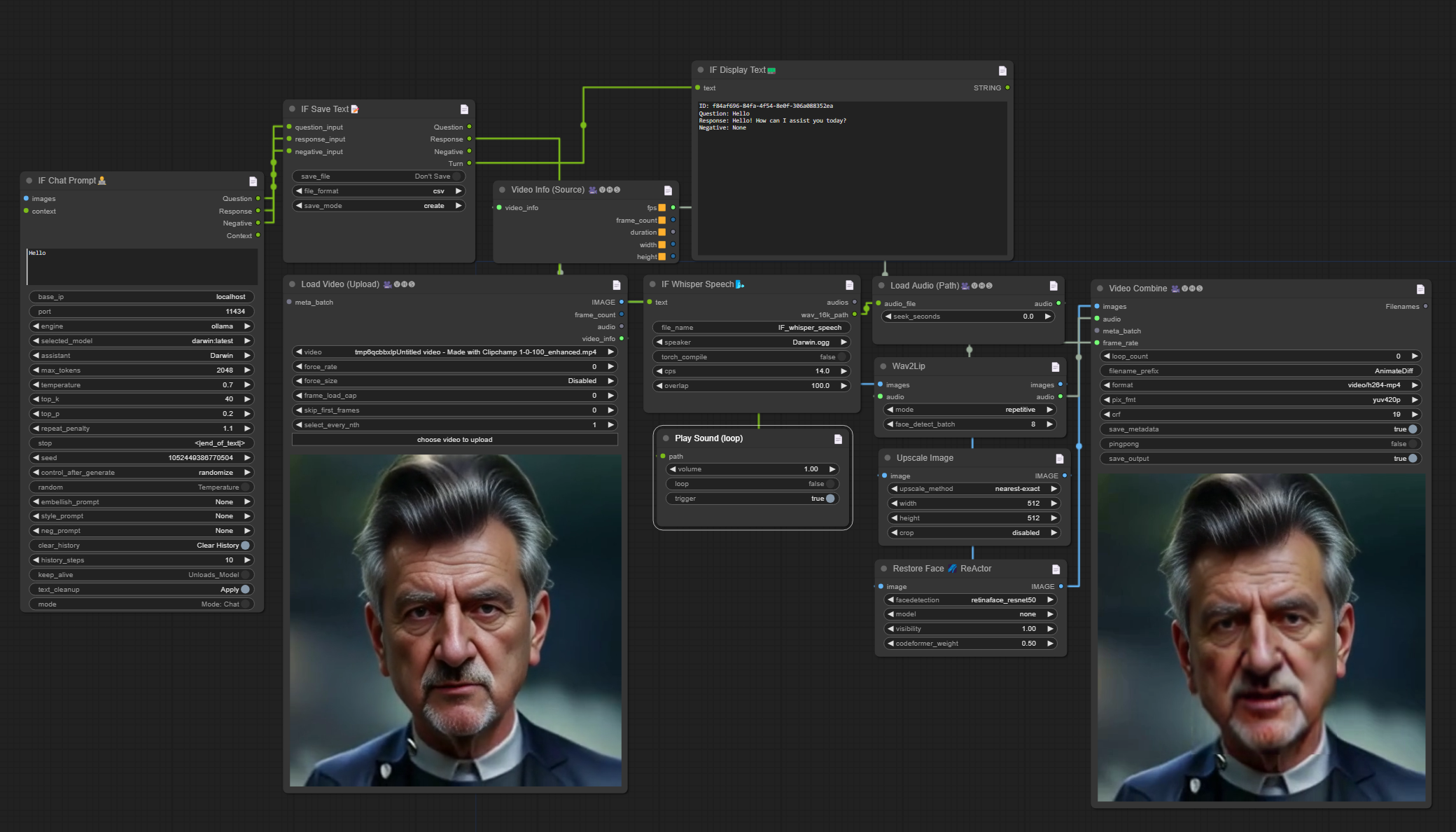
最良のバージョン - v4.2 - ワークフローにwav2lipを追加しました。誰かが動作するノードを作成していたので、これで動画を読み込み、Whisperがアシスタントの声を生成し、音声付きのアニメーションアバターが可能になりました。楽しいワークフローで、組み立てるのも楽しかったですlol。LLMプロファイルを編集し、本来の用途ではない場所にさまざまなコネクターを接続しています。このワークフロー内で良好な音声を得られるのは「Play sound (loop)」ノードだけです。パスを入力に変換し、WhisperのWAV出力をPlay soundの入力として使用する必要があります。これにより、声が再生され、聞こえるようになります。
その後、アップロードした動画と合わせてwav2lipに送信して動画を生成します。ノードは動作しますが、ForgeやAutoほど良くはありません。しかし、ノード作成者は素晴らしい仕事をしました。ここからさらに向上するしかないし、今のところ悪くないですよlol。
以前のバージョン-------------
音声をwav2lipとSadTalkerに通して楽しさを試し、以前作成したキャラクターの顔をダーウィンに使いましたlol。
さらにグループと説明ノートを追加。
テキストまたは音声を通じたAIアシスタント。
インペインティングとアウトペインティング
SVD、Cascade、AnimateDiff
スプライトシート作成ツール
.OGGオーディオファイルをトレーニングデータとして使用した音声生成(Whisper to Speech:ボーカルのみのオーディオ、3分ほどで十分ですが、例示の10分の方がより良い)
私のレイヤリンググループノード設定を追加
音声アシスタント用テストワークフロー。Rosebud AIワークフロー用にいくつかのノードを試しています。ダーウィンはカスタムパーソナリティのため、含んでいません。
Ollamaのインストールと実行が必要
Impact FramesまたはIFノードによりこれが可能になります
作業中