Super Easy CivitAi Friendly Workflow with Full Notations








詳細
ファイルをダウンロード
このバージョンについて
モデル説明
⚠️こんにちは!
このモデルを更新して、あるノードパックの更新によって引き起こされた小さな(しかし破壊的な)問題を修正しました。すべて正常に動作するはずです。ありがとうございます!
また、はい、これはIllustriousとNoobモデルでも動作します。
さらに、個人的なワークフローのより近代的なパブリック版を準備中です。私はしばらく引退していましたが、近い将来(あるいは来年、誰か知らんけどc.c)に復帰して公開するつもりです。
– ありがとう! 🐭
– 2025年6月17日
こんにちは! 🦌
これは、私の「ユーザーに優しく、CivitAiに優しい」ワークフローのバージョン4です!
SD1、SDXL、Pony、およびそのバリエーションをサポート!
再び、ただの趣味で完全に新しく構築しました!わーい!
(バージョン5は現在開発中で、ControlNet機能、より洗練されたアップスケール、および私の個人版で使っている追加の手法などを含む予定です。下のコメントをご覧ください)
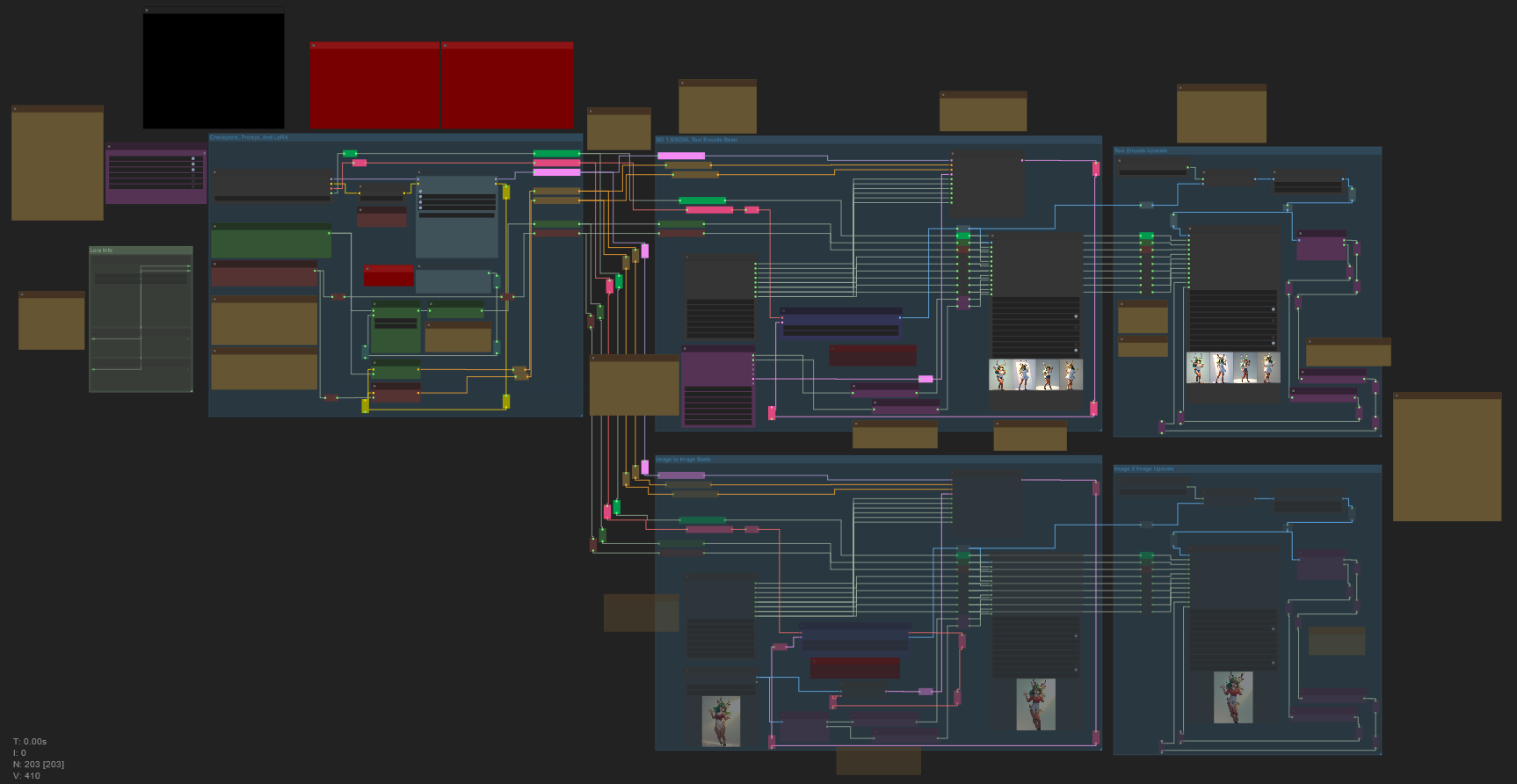
このワークフローは、画像をCivitAiにアップロードする際に正しいメタデータを送信することを主な目的として、可能な限り使いやすく設計されています。つまり、あなたが特別な操作をしなくても、すべてのリソースやLoRAが正しく記録されます!
また、柔軟性と読みやすさを重視しています。意図的にコンパクトにせず、すべてのノードと接続が点対点で追跡できるように構成しているため、あなたのワークフローにImage Saver機能を追加するための学習ツールとしても役立ちます。
さらに、現代的なワークフローに求められる使いやすさのオプションや高解像度機能を豊富に備えています。
以下はその主な機能です:
ビルドインVAE/カスタムVAEセレクター。ワンクリックでビルドインVAEと別ファイルのVAEを切り替えられます。
SD 1.5およびSDXL/PDXLエンコード対応。SD1、SDXL、Ponyのいずれのチェックポイントとも使用可能です。
SDXLスタイルの汎用的なプロンプト記述対応。SDXLモデルが単語ではなく文の使用法で学習されている場合、このワークフローはそれを活用できます。逆に、従来のキーワード/タグプロンプトを使用したい場合も、スイッチを一つクリックするだけで実現できます。
マルチプロンプト処理。使いやすさと読みやすさを考慮し、プロンプトを複数のセクションに分割しています。詳細・スタイル・スコアタイプのプロンプトは1つのテキストボックスに、シーンの説明用プロンプトは別の読みやすく編集可能なボックスに配置し、ワークフローが実行時に自動的に組み合わせます。
セカンダリープロンプト。ある概念が画像の他の部分に漏れ出る問題を抱えていますか?被写体にツノをつけたいが、画像の他のすべての部分に不思議なツノが生えてしまうのは嫌ですか?セカンダリープロンプトを割り当てて、プロンプト間の優先度をスライダーで調整し、画像をより精密に制御できます。
SDXL/PDXL潜空間解像度。エンコーダーは、スケジューラー処理中に画像をより高い解像度とみなすことで、全体的な詳細を向上できます。内部解像度の処理係数を簡単に選択でき、シード固定画像の微調整をCFGやステップ数をいじらずに実現できます。
Kohya Deep Shrink。品質やGPUリソース、タイリングエラーのコストをかけずに画像の全体的なサイズを拡大する高解像度生成プロセスです。画像に後からダウンスケールを適用(このワークフローではまだ対応していません)すると、元のサイズで生成するよりもはるかに詳細な同じサイズの画像が得られます。
搭載アップスケーラー!アップスケールを行い、同時にメタデータを適切に調整します。すごい!
LoRA検索機能。ウェブサイトにアクセスせずに、LoRAのトリガー、推奨プロンプト、その他の有用な情報を探せる簡単な機能です。名前が意味不明なファイルでも安心!(L10n_h34r7さんありがとう)
CivitAi向けLoRAレポート機能!このワークフローは、すべての埋め込みとLoRAリソースをメタデータに自動的に記録します。CivitAiにアップロードする際に、サイトの生成ツールやAuto1111を使っている人と同じリソース一覧が得られます。モデル作者に自動的にクレジットを表示でき、プロンプトタグもそのまま反映されます。追加の作業は一切不要!
バージョン4ではLoRAが自動更新されます!正しい入力方法に頭を悩ませる必要はありません。ワークフローがすべてを自動で処理します。当然の仕様です!
Auto1111対応ファイル!CivitAiと同様、ファイルをAuto1111に直接インポートでき、すべてのプロンプト、設定、LoRAなどが正しく認識されます。UI間の移行が容易になります。
極めて読みやすい構成。このワークフローは以前のバージョンに比べてはるかに複雑ですが、すべての要素が視覚的にわかりやすいように丁寧に設計されています。意図的に拡張してコンパクトにせず、すべてのノードと接続が明確に識別できるようにしています。
詳細なコメント付き。私は説明が好きです。以前のバージョンほど丁寧に手取り足取りではありませんが、すべてのプロセスとステップに豊富なコメントを記載しています。ComfyUIの基本的な理解は前提としますが、初めての人でも追えるように工夫しています。ただし、バージョン3ほど単純化はしていません。むしろ、ComfyUIの初心者向けの実際のクイックコースを別プロジェクトとして作成するつもりです。
注意:v4には画像から画像への機能(Image to Image)は含まれていません。この機能を削除したのは、今後画像から画像生成に特化したワークフローをリリースする予定だからです。そのワークフローは読み込まれた画像のメタデータを読み取り、自動的にプロンプトを伝播する機能を備えます(Auto1111が画像をインポートする方式と同様)。 (v3.1にはCivitAiメタデータ付きのimg2img機能が含まれています)
このワークフローは複数のノードを使用しています。自動でそれらをインストールできるComfyUI Managerの使用を強く推奨します。
多くのカスタムノードをインストールしており、どのノードを使っているか忘れてしまっているため、私自身にもあなたにも便利です。ただし、私のメモによると、このワークフローで使用しているノードのリポジトリは以下の通りです。正確だと思いますが、このリスト外のノードも使っている可能性があります。もしそうなら、お知らせください。
使用リポジトリ:
https://github.com/alexopus/ComfyUI-Image-Saver
https://github.com/Suzie1/ComfyUI_Comfyroll_CustomNodes
https://github.com/pythongosssss/ComfyUI-Custom-Scripts
https://github.com/rgthree/rgthree-comfy
https://github.com/jitcoder/lora-info
私のワークフローをご覧いただき、ご利用いただきありがとうございます!気に入っていただけたら、ぜひ評価とコメントをお願いします。また、質問やご意見があれば、フォローまたはお気軽にご連絡ください。
オリジナルのアイデアを提供してくれたL10n_h34r7さんに心より感謝します。彼らのワークフローは(カスタムグループノードの部分で、彼らのせいではありませんが)私が使おうとしたときに壊れ、それを直そうとしたのがこのプロジェクトのバージョン1の始まりでした。その後、このプロジェクトは独自の存在へと発展しました。
このワークフローを、あなたの学習やカスタマイズに自由に使用・分解していただいて構いません。これはImage Saverの仕組みを明確に示すための学習ツールであり、他にもいくつか興味深い機能を紹介しています。私にクレジットを表示していただけると大変嬉しいですが、必須ではありません。
ありがとう!
– Kizzi 🦌