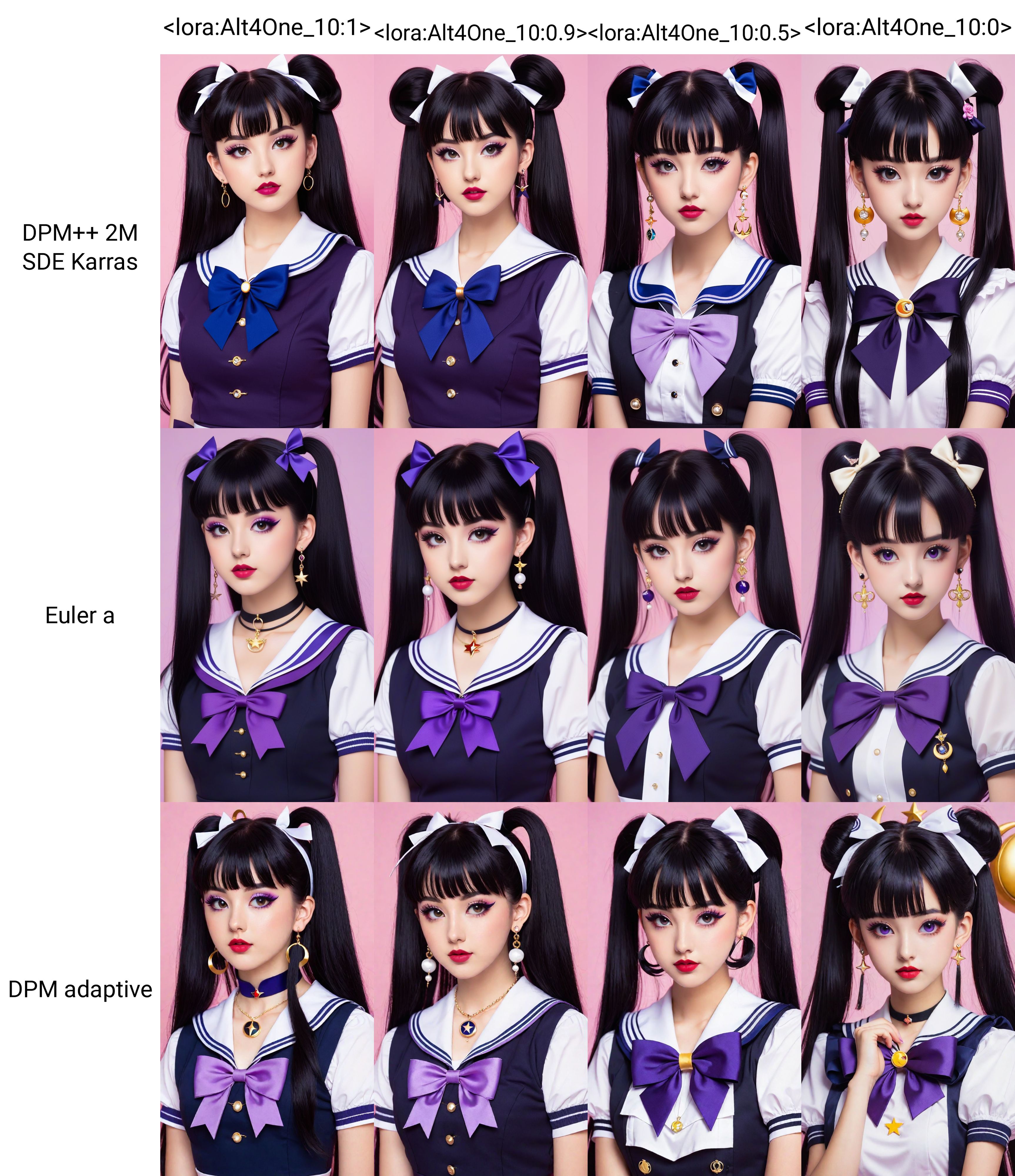
このモデルはSDXLを用いて460枚の画像で学習されました。次のバージョンでは1000枚以上で学習したいと考えています。
このLoRAの目的は、より多様なスタイル、女性、衣装、ポーズなどを生成することです。キャプションはDeepBooruを用いて作成されているため、このスタイルのプロンプトとよく組み合わせられます。