crying_with_tears_flux









详情
下载文件 (2)
模型描述
V2.0
Special thanks:
The dataset can be downloaded (26 images). The workflow is similar to V1.0, but I changed the generated model, to get anime style training dataset. With additional prompts you can tweak the poses (looking up/down, smiling, etc.).
I found a thing: when I used realistic training data, the lora can generate realistic photos. However, it's hard to generate anime style ones (though add "anime" prompt). On the other hand, using anime training data is good. You can add "photorealistic" prompt when generating to avoid anime style.
(I added the "anime style" tag in training data, maybe it has influence?)
{
"engine": "kohya",
"unetLR": 1,
"clipSkip": 1,
"loraType": "lora",
"keepTokens": 0,
"networkDim": 2,
"numRepeats": 6,
"resolution": 512,
"lrScheduler": "cosine",
"minSnrGamma": 5,
"noiseOffset": 0.1,
"targetSteps": 1040,
"enableBucket": true,
"networkAlpha": 12,
"optimizerType": "Prodigy",
"textEncoderLR": 0,
"maxTrainEpochs": 20,
"shuffleCaption": false,
"trainBatchSize": 3,
"flipAugmentation": false,
"lrSchedulerNumCycles": 3
}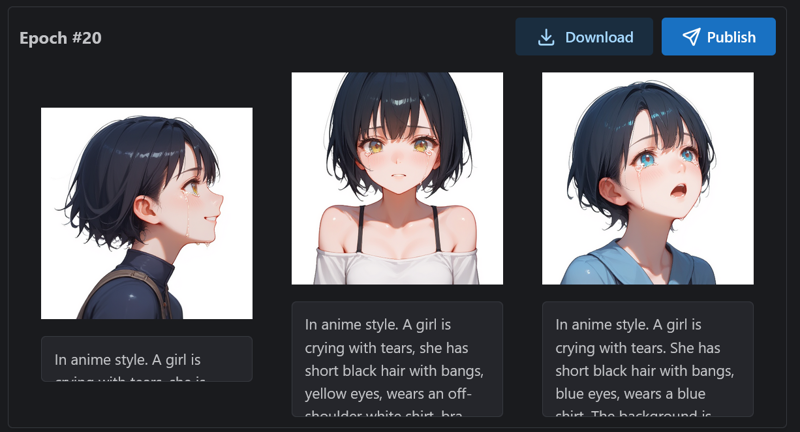
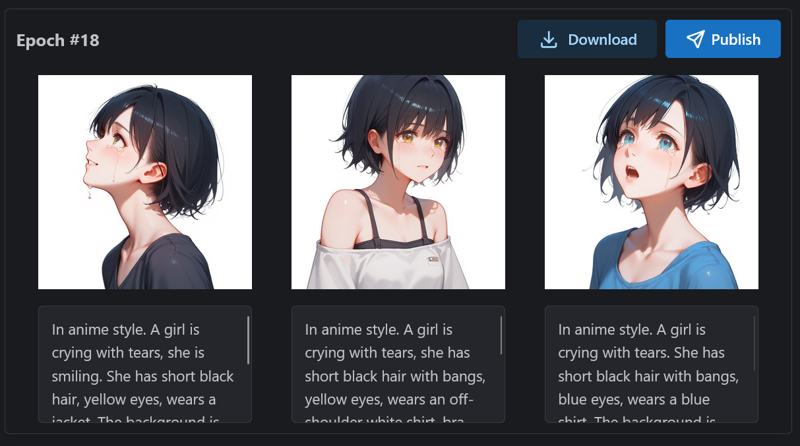 Finally, I chose the epoch #18 model to publish.
Finally, I chose the epoch #18 model to publish.
V1.0
Special thanks:
The dataset can be downloaded (27 images), which is generated by the above two models (1024×1024, then reduced to 512×512). Then I tagged them using tools in webui, and used natural language to re-tag them manually based on these auto-generated tags. Finally, using this lora, with additional prompts you can tweak the poses (looking up/down, grin and smiling, close mouth, etc.).
Training parameters:
{
"engine": "kohya",
"unetLR": 1,
"clipSkip": 1,
"loraType": "lora",
"keepTokens": 0,
"networkDim": 2,
"numRepeats": 6,
"resolution": 512,
"lrScheduler": "cosine",
"minSnrGamma": 5,
"noiseOffset": 0.1,
"targetSteps": 1080,
"enableBucket": true,
"networkAlpha": 12,
"optimizerType": "Prodigy",
"textEncoderLR": 0,
"maxTrainEpochs": 20,
"shuffleCaption": false,
"trainBatchSize": 3,
"flipAugmentation": false,
"lrSchedulerNumCycles": 3
}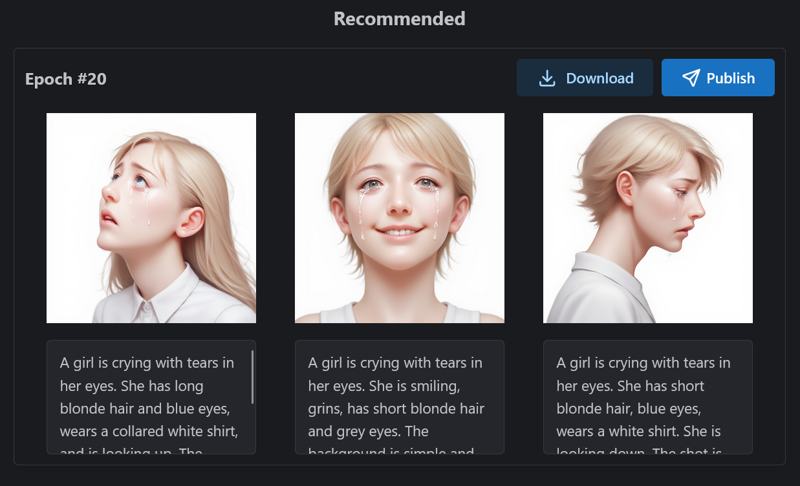
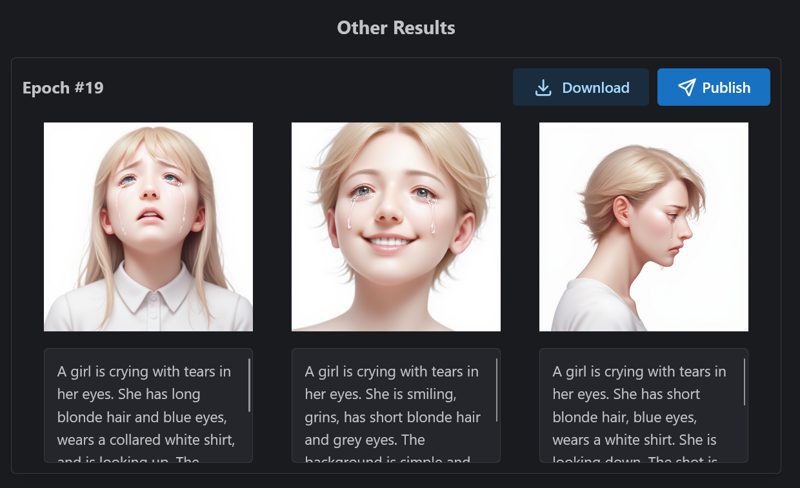 I think the final epoch is a bit better than epoch #19. So I choose the final one.
I think the final epoch is a bit better than epoch #19. So I choose the final one.