Pyro's NSFW Proof of Concept for FLUX













Details
Download Files (1)
Model description
WARNING: Those three models are proof of concepts with half the shit not working. It’s meant to be a REAL proof of concept, not some marketing BS like slapping "EXCLUSIVE CLOSED ALPHA TEST" on a pre-release. And honestly, every time Call of Duty does that, it probably is an alpha, and they’re just double reverse bamboozling you.
The purpose of this is to document my progress toward a final model and to evaluate Flux's capabilities so I can one day tell my grandkids, "Look at this model, where I tried to de-bias it around pussy shapes. Man, what a jokester I was." And we’ll all laugh and have a good time. Don’t you dare take that away from me.
I’m also uploading this so you don’t get scammed by garbage that wants all your Civitai shillings for some early access crap.
Here, you get shit without paying.
Training on this particular model has been halted because I learnt so much about flux that it invalidates pretty much everything this model is based on. Also the model bricked. Is gone. Is in model heaven somewhere next to my "hulk hogan as pikachu" lora.
So, if you're expecting perfection, wait a few weeks. If you're here for the chaos, read on. If you try it out and shit doesn’t work as expected, hold your horses, breathe in deeply, and remind yourself of everything said above. Know that you’ll soon™ get salvation in the form of a full release. So, no need to throw your Kleenex and socks away just yet.
Buckle up. Very long text ahead
Can't he just shut the fuck up?
At first, I wasn’t planning on releasing these models because, honestly, they’re unfinished. These are basically just the results of some test runs to learn the ins and outs of FLUX and to shut up the morons who told me, "You need millions of hours to train a penis back in" or the even dumber, "ARE YOU STUPID? YOU CAN'T TRAIN FLUX!"
Spoiler alert: those idiots were wrong, and proving them wrong is like a top 3 feeling for me.
Flux is a fine-tuner's wet dream if you know what you're doing. It’s way more flexible than SDXL, and it has a semantic understanding you can abuse like nobody’s business (which is weirdly overlooked, but whatever - the model is still fresh out of the womb).
But here’s the thing - you need to know a few tricks, or your model will end up in the same trash heap as these proof-of-concept models. Mistakes were made, concepts were missed, and now these models are collecting dust in "/usr/pyro/failures-of-the-past"
So why did I upload them anyway?
My community on Discord practically begged me to release these models. They even joked about forming a cult around me, which was funny but wasn’t going to change my mind. However, they then started explaining the current state of Civitai, since I basically only visit this site to upload shit, and have a place for my ramblings until my website is done.
When Civitai announced their Civitai dollars, I was like, "Oohhhhh... I don’t know..." Turns out, it’s done absolutely no good. Now you see models where you can spot ten mistakes in the dataset or training from the first image, and they’re asking for 900k Civitai shekels. Or a Lora for a red bra for 14k Civitai lire.
What kind of cancerous garbage is this? I’m all for model makers getting some donos to recoup their training costs, but scraping 5k porn images, running them through the WD14 tagger, and calling it a day isn’t worth some elaborate early access buhai that costs 900,000 Civitai marks.
I remember back in SD1.3 before Civitai was a thing, we were a huge Discord family, everyone helping each other out. People wrote hundred-page-long Rentrys with everything they found out, with links to other hundred-page Rentrys from some other guy. You had a feeling of being able to access every model and every piece of information with just two clicks. With early SDXL, it was the same. It worked because nobody gave a shit about money. We all just wanted to make perfect waifus.
But now, since there’s the opportunity to invest real materialism into models, everything feels split, and there’s already community segregation going on and "my model > your model" attitudes. I’d bet a whole 5 Civitai dinars that when AuraFlux Pony releases, everything will be about Pony vs. Flux.
That pisses me off, and saddens me
I want to do my part to push back against this trend. To set a base level you should expect from a model, so people stop trying to monetize low-effort garbage because they can’t compete with better, free stuff. And even though my model isn’t finished yet, it should be good enough to explore what to expect. So please, save your Civitai pesos. Do some FLUX Lora experiments with them instead.
And I promise you one thing: You will get a NSFW model as good as I can make it, using tech and science Mr. Early-Access has never even heard of - most of it custom written (and when I’m done, open-sourced for everyone!) - all for completely free!
Also, on the very slim chance an Arabian Sheik is reading this and wants to donate an H100 or something... I’m not saying no!
If you want join the cult, this way: https://discord.gg/r2tJpTv4
What do I get?
So what can you expect?
- No "same face woman" syndrome - in depth facial analysis of the dataset to make sure hitting on "Generate" feels like opening a box of wonder of never knowing what comes.
- Removal of the "Flux" sheen of the skin
- The ability to use normal English words or sentences to describe what you want to see - You don't have to remember 20 different magic words all prefixed with my short handle as a pitiful try to stay relevant in your mind, and you can use tags, natural language or both at the same time.
- No teleporting nipples - You see it in other models. nipples drilling through bras like they are nothing - I found a fix, but then my model went up in flames, so it still happens sometime and will be fixed 100% in the main release

- perfect compatibility with my other loras, and loras I think are worthy (and probably all others too)
- Fixed some of the main criticisms of my SDXL model
- And I know it's highly subjective, but imho my model makes the most beautiful women I've ever seen (especially combined with the other 'modules'). And an infinite amount of them. I'm lucky that my opinion on this matter is the only one that matters.
- And last but not least my general plan as a model maker for the future, my endgame goal with this particular model, and also my goal as a solution architect - The software landscape in StableDifussion land is a disaster
No same face syndrom and fixing other problems
Even the juggernauts (heh) of the models you find here suffer from this, with names like "same-face syndrome," "1-girl-itis," or just "lol."
For me, it’s the worst defect a model can have. I love to explore the "world" of a model and be surprised by its generations. When the RNG gods bless you, and the most beautiful human just pops out, it’s like finding a mirror in PoE - you’re like, "oh woowowowowowowow."
But you can’t be surprised if you already know what the girl is going to look like. It’s boring and kills all the fun. I started tackling this issue with my SDXL model, and I think my solution is pretty solid, but you can decide for yourself.
So, why does this happen? Basically, it’s bias in the dataset. A certain face or feature appears more often than others, so features of that face become the default. Another reason is over-merging models, which basically averages the concept of a face to death, and from this average, the only entity the model knows emerges.
And I’m sorry for what I’m about to do, because once you see it, you can’t unsee it - yes, even FLUX.dev suffers from same-face syndrome already.
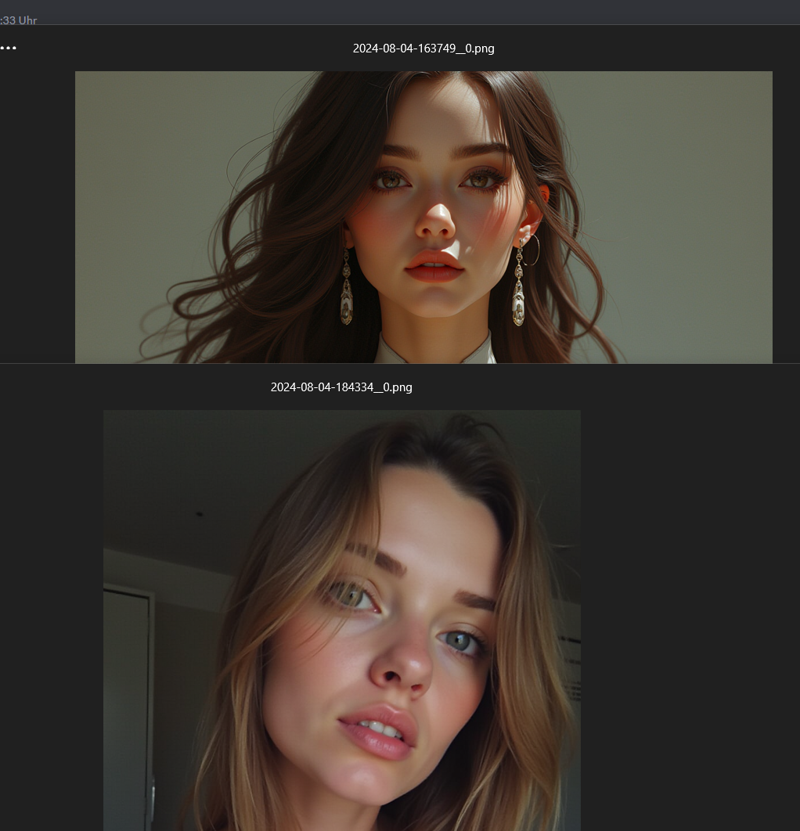 Flux girls have basically all the same lips, especially upper lips and it's almost like only mesocephalic heads that get generated
Flux girls have basically all the same lips, especially upper lips and it's almost like only mesocephalic heads that get generated
What can you do about it?
At the beginning during SD1.5 days I was literally removing and adding images by hand until I had the feeling there's no bias.
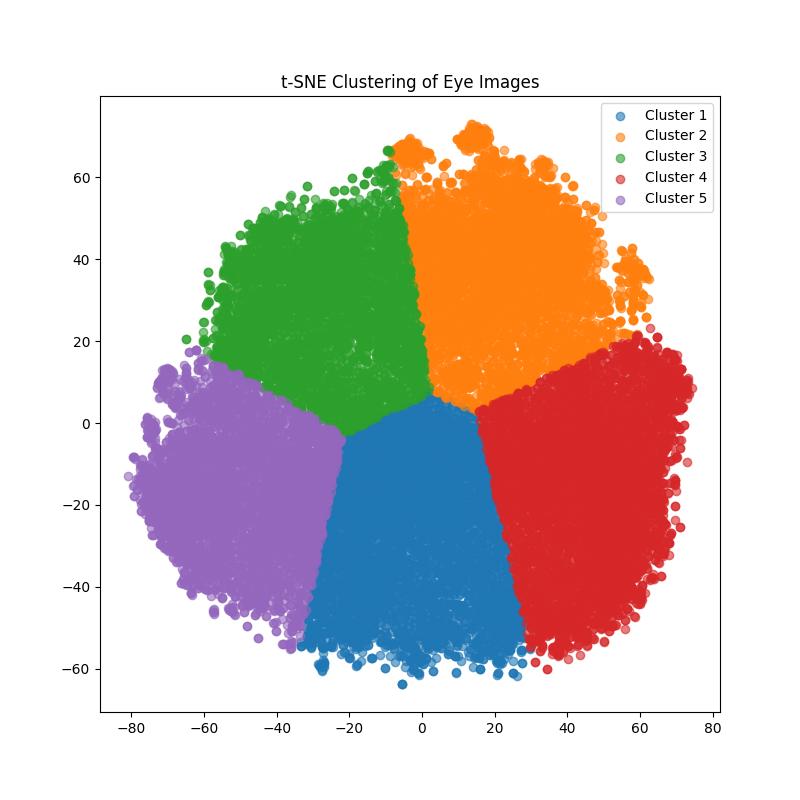
Today there's a bunch of automatic feature extraction, a bunch of models that do analyzing clustering pipapo so I find out which feature of which face is particularly strong in my dataset.
let the 50k pair of eyes take a look of you! and there's a nose that looks like a pig's nose... wtf
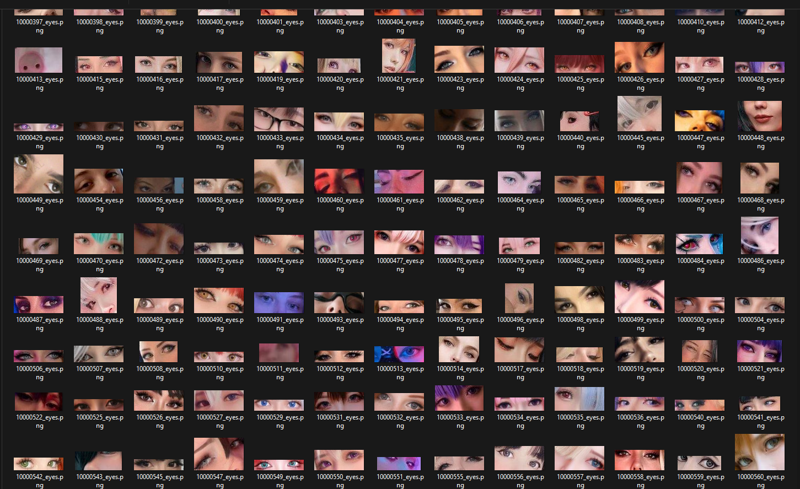
 but they are all perfectly balanced as all things should be
but they are all perfectly balanced as all things should be
Basically, every feature that can lead to bias gets extracted, clustered, and analyzed so you know what to expect before you even start training.
Here’s a little hint about what I’m up to: This is something that should be in every fine-tuner's toolkit. The sad reality, though, is that there isn’t even a proper fine-tuner’s toolkit.
Examples: (Nothing here is cherry-picked unless explicitly mentioned - all using the same prompt)
upper body potrait of a woman
 Pyro's bottom and Flux in the upper row with a strong case of same woman face, also while I love Roger Deakins, not every image has to have his cold-greenish color grading.
Pyro's bottom and Flux in the upper row with a strong case of same woman face, also while I love Roger Deakins, not every image has to have his cold-greenish color grading.
Here some other random faces

 What Else is Inside?
What Else is Inside?
 (prompt: a woman on a gaming chair)
(prompt: a woman on a gaming chair)
Well, that’s for you to find out. Each of the PoCs was about trying out different things, and I’d guess anyone experienced in fine-tuning will instantly recognize some of the experiments.
Oh, you mean what kind of sexy stuff it can do, and you don't care about the science? Fair enough.
Honestly, I’m too lazy to check exactly what data went into which version. But here’s the scoop: Blowjobs should work best in almost all of them. The rest? Probably not as much, because, well, Blowjobs stole all the latent space.
 omnomnom, eating all the other concepts
omnomnom, eating all the other concepts
I recommend using a strength of 0.7-0.95 for best results.
And definitely pair it with my other Loras.
One of the main critiques of my SDXL model was that every girl looked like, as the zoomers would call them, an "e-girl"—you know, the highly polished advertisements for beauty docs you find on Patreon and OnlyFans. And, to be fair, they’re right, because I think it’s fucking hot. I’ve got a partner if I want to see normal-looking women. This model? It’s for reality escapism.
But I get it. I did some analysis and moved some of the biggest bias-causing factors into the "Pyro's PMI" Lora, so now the women in this model look more "normal." But if you’re like me and still dig the bimbo plastic look, grab the Lora, and you can enjoy the old ways.
Because of this, my plan is to build some kind of modular system with Loras that you can connect together like Lego pieces. In the end, you’ll have your own personal NSFW model. Plus, this way, it’s less of a disaster if one model fails during training. Let me know what you think about this idea or if you prefer a big bad motherfucker of a 22GB finetune.
Also, "Boring Reality" and "X-Flux's Realism" Lora are a very good fit with this model. Final model will also have a override for "realistic" images.
Talking with Flux
With CLIP, you’re in the "seeing is believing" territory, or rather, "having an embedding is believing." The best approach is to ensure that everything you want to see in your image also exists as an embedding in your prompt. This way, everything is conceptually anchored as it explores the space. That means you start collecting quite a pool of information in one prompt, like this:
"pov, 1girl, penis, blowjob, cleavage, kneeling, a woman kneeling in front of a man sucking his huge cock."
 You have your camera point of view encoded, the body parts you want to see, the actual act, and some other information that shapes the world the image lives in. Also, because of the second CLIP encoder, you can include a short natural language description to refine some details.
You have your camera point of view encoded, the body parts you want to see, the actual act, and some other information that shapes the world the image lives in. Also, because of the second CLIP encoder, you can include a short natural language description to refine some details.
This is literally as good as it gets for SDXL.
I don’t know why - maybe because I love burning money - but I was completely oblivious to FLUX using T5 for encoding (next to CLIP) and I just completely forgot about it. I was like, "Yeah, why wouldn’t it work?" So I took my SDXL dataset, and here we go!
But no, that shit doesn’t work with FLUX! Or at least not as well as I wanted it to.
My captions aren’t giga complex, dense prompts. Your average neckbeard on this website has longer default negative prompts for generating anime feet than I have for captioning my dataset.
So why doesn’t it work? I really recommend, just for fun and because it’s like computer science history, that you go through one of the hundreds of "build a sentiment analyzer with T5" online tutorials. You’ll learn how to fine-tune T5 to say if a review is positive, neutral, or negative.
Basically it works exactly like with images, you have your dataset and gave every entry of your dataset a label or caption. In this case your dataset consists of amazon reviews and your caption, well how would you caption a review so an AI learns the meaning of it? Take a sec and think about it.
T5 is amazing, but it’s pretty strict and very literal about its interpretation of the world. You never want to caption a review like, "this is a positive review because it says the food was good." You just forced T5 to connect "positive review" with "food," even though you don’t even know if that’s a relevant quality. Whatever T5 figured out on its own about how to classify reviews will now have "food" somehow mixed in. Not good. That’s why you just caption the reviews with "positive," "negative," and so on. You only caption what you want to get out and let the AI handle the rest. That’s why you have AI in the first place - because even a mediocre AI model can do classification, clustering, and similar tasks way better than a human.
An example how literal T5 can be - A pussy with big hole
 Your inner smartass might be screaming, "But we don’t even fine-tune T5… we just use it as an encoder!"
Your inner smartass might be screaming, "But we don’t even fine-tune T5… we just use it as an encoder!"
And you're absolutely right. But here’s the thing: the UNet is essentially a representation of the world as understood by T5, which is why it generates a cat when you prompt "cat." It’s tuned to the encoder, meaning it relies heavily on how T5 interprets and represents the text. Because of this, some principles that apply to T5 fine-tuning also apply here, at least to some degree. (to what degree we don't know yet)
That’s why you don’t want to overload the model with unimportant details -because the model is much more efficient at building up its own understanding of the world than trying to integrate every little detail you throw at it.
So, my "pov, 1girl, penis, blowjob, cleavage, kneeling, a woman kneeling in front of a man sucking his huge cock" prompt is crazy overloaded, especially since the prompt essentially repeats itself, and the rest is stuff FLUX already knows.
What do you want FLUX to learn? That you have to mention "woman" twice and "penis" twice? T5 is a model that often take things very literal. It will see that this is true for all other BJs as well and than it becomes reality and, and then there's no chance in hell that will turn out good.
You could probably reduce the complete prompt to "a woman sucking a penis," and you’re done. Or "penis, blowjob, a woman" if you want tags. And please stop telling everyone that you have to use natural language with FLUX. We’re talking about like a 1-2% performance difference—hardly a big deal—so please stop acting as if all instances of FLUX would implode if you use tags.
SDXL captioning will cause FLUX to brick. You might get away with it with a complete fine-tune, but I wouldn’t bet on it.
And yeah, after spending quite some cash, I’ve already seen my Yoga model brick twice and my NSFW model brick three times. Bricking means it freezes. The model literally stops understanding how to integrate new information into the network, and nothing changes anymore, except everything slowly becomes more blurry. Even the concepts it had learned well start to brick. For example, the tittyfuck concepts were the first to brick because they share almost all tags with blowjobs. Since blowjob is a much bigger part of the dataset, it wins, and concepts like "penis," "1girl," "pov," etc., all get connected with blowjob. FLUX just doesn’t know how to make the connection with tittyfuck anymore. The concept bricks and generates the same image for the last 10k steps. Once bricked, the model is gone, even if you stop training and start over with blowjobs removed or something.
Imagine your brain breaks by having an information overload on tiddies. I really, really hope that sometime in the future, when we figure out what consciousness and sentience are, we don’t accidentally find out that even the models of our time are sentient because their network is bigger than some sentient threshold. Imagine breaking someone’s brain by giving them an information overload on tiddies.
And if you don't believe me, just go to the flux lora page and marvel at the monstrosities I wouldn't even download if that was a SD1.3 lora and some are sharing their dataset and their captioning and I wonder how they look like....
The future is now old man
Yes, and the future has plenty of stuff to be excited about! Of course, there’s the full NSFW model, but there's even more on the horizon.
Over the years, I’ve amassed quite a collection of tools that help me create my models. Unfortunately, the only person in the world who can navigate this clusterfuck is me, so you won't find it anywhere else. But I'm getting older, and the chances are increasing that while reading some stupid shit on reddit, I might just drop dead - and all that knowledge would be lost. But honestly I'm pretty sure people are actually dying while reading some of the factually wrong anti-ai shit you can read on the technology sub. why is a technology sub full of luddis anyway?
Much like my dissatisfaction with the state of affairs on Civitai, I’m also not thrilled with the overall state of software in the Stable Diffusion ecosystem. I’ve been doing software for 20 years, and honestly, it’s the worst ecosystem I’ve ever seen. Worse than Gentoo Linux before it imploded.
But I won’t dive into that right now because it would definitely hurt some egos and rustle some jimmies, and I want to enjoy my weekend. You’ll have to wait until I’m in the mood for that rant.
However, if you talk with LLM software people, one thing is clear: they see image-gen AI as a joke, and their reasoning is surprisingly valid.
The eye feature cluster extraction teaser above should be enough to get you hyped, and you'll be getting some new info pretty soon :)
Nonetheless, one small teaser. Imagine this: You have a collection of 200k unsorted images, and you don’t even know what’s in there, because you hit "download all" in your booru scraper by accident but decided to just live with it.
Now, what if I told you that by playing three rounds of a quick game (takes a minute per round, max), you could find all the images related to any given concept in the dataset? Even fuzzy concepts like "I think my mommy would like that image." Would that be something you'd want for building datasets and concepts? I bet you would. I use that shit every day.
Don't believe me? It'll be a pleasure to prove you wrong!
Until next time!
Cheers,
Pyro
Discord channel
https://ko-fi.com/pyros_sd_models
If you made it down here, congratz, I like you, and you deserved a very early sneak peek at some skin texture and lighting experiments for the upcoming final model





