Colorful


















세부 정보
파일 다운로드 (2)
이 버전에 대해
모델 설명
Project by AiArtLab
Colorfulxl is out! But who cares then we have so great 1.5 checkpoint?
https://civitai.com/models/185258/colorfulxl
Thank you so much for the feedback and examples of your work! It's very motivating.
About v 8.0:
This is a unique synthesis of cinematic, photos, anime and art.

I think this is the final version. Most likely I'll do ColorfulXL now. At the moment I don't see anything else that can be improved. Thanks to everyone who has been with me all this time (more then year)! Try different resolutions and check 1-step generation with DPM adaptive (but other samplers, with 10 steps may be faster)
My settings
Portrait: 768*1088
Landscape: 576*1280
Samplers: DPM++2M SDE Karras - 20 steps, best (work with 10)
Also work: Euler a, DPM2, DPM++2s a, DPM++ SDE, DPM++ 2s a Karras
DPM adaptive - 1 step
VAE - included! (civitai bug requires indication of a VAE that is not on this site: vae-ft-mse-840000-ema-pruned.safetensors)
About v 7.3:
A very controversial and complex version.
Very sensitive to negative prompt, sampler, resolution and number of steps. Probably bad at art.
In fact, an attempt was made to remake SD1.5 globally. Which often leads to incorrect anatomy. Still, I think it's an interesting version and I'm curious what you can create with it.
Before

After

Most huge train details
https://wandb.ai/recoilme/finetuning/runs/nkfsrchd
About v 6.2:
I don't have luck with hires training (1280 - just throw in trash millions steps and $70)
So, i returned to v3.7 as a base and trained on 960*576, 576*960 and 768*768. Some cinematic added. But its not photorealistic model (i like art), mostly semi-realistic
Please respect my time and resources. If you use my model to make money - contact me for fair use
About v 5.0:
It was hard. But cheap) I spent less then $30 and ~1000 civitai credits on train.
At 1st of all i preserve ability to generate in 9-12 steps on 768/832 resolution. By my opinion quality is better then Turbo/LCM. But it works only on some samplers

So, at 1st of all i continue playing with negative training. At this time i train deformed, worst_quality, oversaturated and so on loras
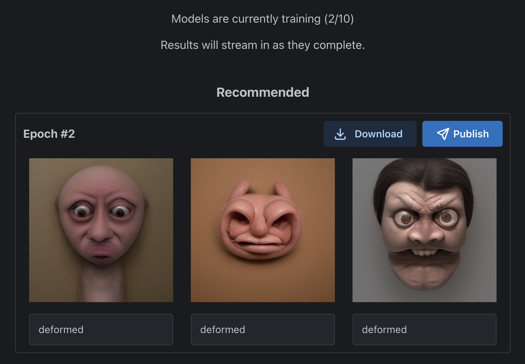
And merge it with different weights, like -0.3
You will be surprised how many trash in SD 1.5!
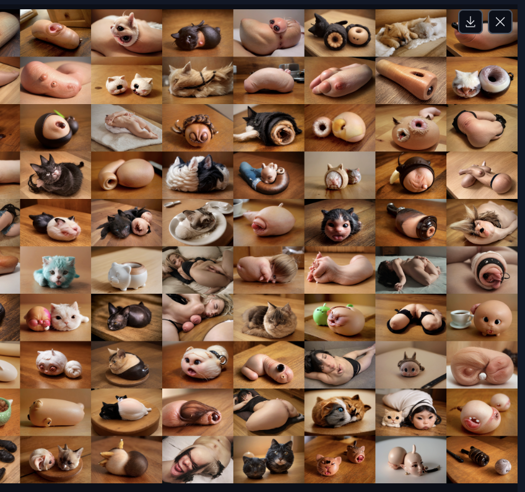
At same time i train realistic checkpoint. Realistic is tricky
For example "woman, covered by snow", looks like

But thanks to Supermerger team and my brilliant cosine similarity merge algo, we may fix it to something like this

best ratio, a photo of attractive stunning Ukrainian woman, messy bun, covered by snow, skin pores, behind glacial mountains, snow, high detailed skin, film grain
And last
Anatomy not ideal at hi res, images was cherrypicked from batch 4 on 832*1024. If you want more stable anatomy try 768 on 960 and low
Have fun!
About v 4.6:
I create 'ugly' dataset

And train on it, and merge with 'add difference'
After that anatomy little better on 768*968, 968*768 and so on, before

after
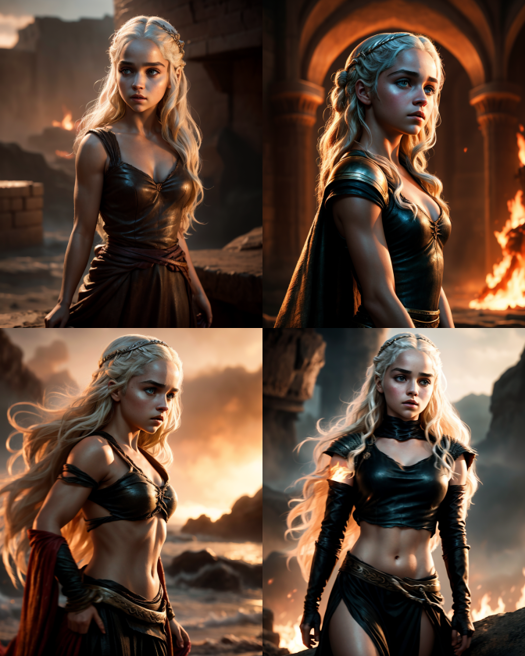
But it was oversaturated:
After a longer study, I discovered that this method gives a very large shift and, unfortunately, while correcting in one place, it breaks in another. This is no better than other methods available to us or direct training.
So, i train again, but on "good images", and merge with cosine similarity
Strange, but i found what it may produce hi quality images at low steps in some cases
About v 3.7:
What's on the train. Compared to SDXL it is 10 times faster, I overfitted out of habit, saved the low lr 4e-7 and the adafactor (although I didn’t cut much). After 4 epochs the result is absolutely normal. Over the course of a night and an evening, she learned the realistic model, so much so that she forgot everything she had been taught all these years. I trimmed it with merging. Charged it for another 4 epochs - again it floated into realism. Trimmed it again)
Something like that little by little. Taught in a multi aspect ratio with an emphasis on portrait and landscape generation. Few people like to generate squares. Dolls/cartoon - etched to a state by a certain semi-realist. Hands/faces in the distance/composition - better, but not perfect
The optimal resolution is 768 by 960. A negative prompt has a very strong effect on the quality, see the examples - I did well with this negative, but with the basic one it was kind of crap. Idnk why is this so
Of course, it wasn’t possible to make SDXL from 1.5 overnight, but I’m happy as an elephant with the result)
Contacts
Models