深崎暮人[ misaki_kurehito ] | artist sytle | 3 in 1




















詳細
ファイルをダウンロード
モデル説明
注意:本モデルは許可なく他のプラットフォームへ移転することを厳禁とします(liblibは既に承認済み:https://www.liblib.art/userpage/a68d8219ddf245ecbd3e1da465409eaa/publish )。発見次第、即座に該当プラットフォームに削除を要請します。
Notice: Unauthorized transfer of this model to other platforms is strictly prohibited (liblib has been authorized: https://www.liblib.art/userpage/a68d8219ddf245ecbd3e1da465409eaa/publish). If discovered, the relevant platform will be contacted immediately for removal.
免責事項:本モデルの利用者は、自国の法律・規制を厳格に遵守し、AI技術を合法かつ適切に使用する必要があります。利用者が地元の法律・規制違反などにより生じたあらゆる不利益や損害については、作者は一切の責任を負いません。
Disclaimer: Users of this model must strictly comply with the laws and regulations of their respective locations and use AI technology in a lawful and compliant manner. The creator shall not be held responsible for any adverse consequences arising from users' violation of local laws and regulations or other reasons.
Noobvpredv10\epsv11 v1.1 バージョンについて
For Noobvpredv10\epsv11 v1.1
このバージョン(v1.1)ではトレーニングデータセットを再調整し、各時代の画風に対する適合性を向上させました。
This version (v1.1) has readjusted the training set, resulting in a higher fit to the art styles of each period.
1:本モデルはNoobXL vpred V1.0ベースのSDXL LoKRモデルであり、VAEにはsdxl_vaeを使用しています。
1:This model is a sdxl-lora based on NoobXL vpred V1.0 .Using sdxl_vae as a vae.
ATTENTION !As a kind of Lycoris model, most of times its usages are as same as the sdxl lora. However, lokr CANNOT be used on some batch nodes on Comfy UI (e: Lora stack). You can use the XYZ PLOT on Web UI to achieve similar functionality !!!
注意!Lycorisモデル系列に属するLoKRモデルであり、ほとんどの場合通常のLoRAと同様に使用できますが、ComfyUIの一部のバッチノード(例:Lora stack)では使用できません!同様の機能を実現するには、Web UIのXYZ PLOT機能をご使用ください!!!
加注:本モデルの表示画像は、テキストから画像への生成(1024x1536)と高解像度拡大(2048x3072)のみで生成されています。
Tips: Pictures showed on the screen were only generated by t2i (1024x1536) and hire-fix (2048x3072).
加注2:表示画像の多くが、通常のテキスト→画像生成や画像→画像拡大とはやや異なる効果を示していることに気付かれたかもしれません。これらの画像は、線がより丸みを帯び、ディテールがより自然で、画風やキャラクターへの適合性も高くなっています。これは、eps予測モデルまたはv予測モデルを個別に使用しただけでは実現しにくい効果です(?)
Note 2: You may have noticed that a significant portion of the displayed images exhibit effects that are slightly different from those achieved through ordinary text-to-image or image-to-image upscaling. Their lines are more rounded, details more reasonable, and the fit to the artistic style and characters is relatively higher. These are effects that are difficult to achieve when using only the eps prediction model or the v prediction model (?).
 まず、これは同じパラメータでeps拡散を完全に使用して生成された最終画像です。
まず、これは同じパラメータでeps拡散を完全に使用して生成された最終画像です。
First, this is the final image generated using the eps diffusion process throughout with the same parameters.
 一方、こちらは他のパラメータをそのままに、以下で説明する方法を適用した結果です。
一方、こちらは他のパラメータをそのままに、以下で説明する方法を適用した結果です。
And this one is the result obtained by employing the method described below while keeping all other parameters unchanged.
この違いを説明する前に、NoobXLの予測方法に関する仮説をお話しします。まず、DDPM(ノイズ除去拡散モデル)には4つのネイティブな予測方法があり、それぞれeps(ノイズ)、v(速度)、x(最終画像)、score(スコア)予測です。これらの4つの予測方法は数学的に等価であり、UNet内の知識とは無関係です。したがって理論的には、1つのモデルが4つの予測方法を同時に備えることも可能です。また、新しい予測方法(再マッピング)をトレーニングしても、既に学習済みの予測方法(以前構築されたマッピング)が完全に忘れ去られるわけではありません。単に不整合が生じているだけで、モデル自体はその能力を忘れていません!!!
それに対応して、NoobXLのeps v1.1バージョンがリリースされたとき、同じシリーズのv予測モデルもすでに公開されていました。そこで私は、NoobXL eps v1.1バージョンがepsとvの両方の予測能力を備えていると仮定しました!モデルは主にeps予測に最適化されていますが、v予測による画像デコードも可能です。ただし、v予測専用モデルほどの性能ではありません。そのため、以下の実験を行いました:
Before delving into the differences, I would like to present a conjecture regarding the noobxl prediction method. Firstly, there are four native prediction methods in DDPM (Denoising Diffusion Probabilistic Models), namely eps (noise), v (velocity), x (final image), and score prediction. These four prediction methods should be mathematically equivalent and independent of the knowledge within the unet. Therefore, in theory, a model could potentially accommodate all four prediction methods simultaneously. Moreover, it is not the case that once a new prediction method is retrained (remapped), the previously learned prediction method (the previously established mapping) is entirely forgotten. It is merely a matter of misalignment; the model itself has not forgotten this capability!!!
Correspondingly, when the noobxl eps v1.1 version was released, the v prediction model from the same series had also been published. Hence, I hypothesize that the noobxl eps v1.1 version possesses both eps and v prediction capabilities! Although the model is primarily suited for eps prediction, it can also decode images through v prediction, albeit not as proficiently as other models dedicated to v prediction. Consequently, I conducted the following experiment:

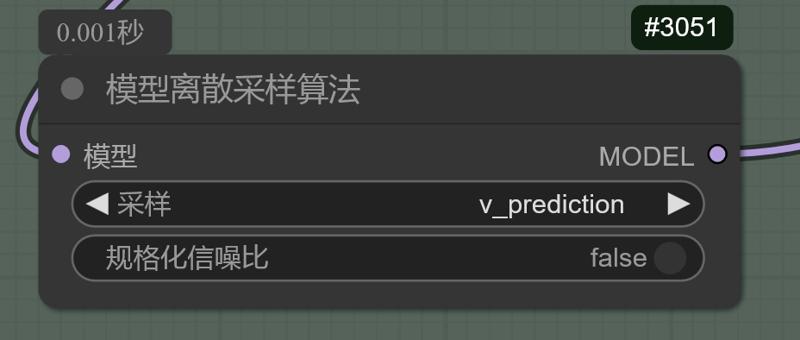 後段のモデル拡大時に、画像→画像拡大の拡散プロセスでNoobのepsv1.1モデルを使用しつつ、モデルのサンプリングアルゴリズムノードでv予測を選択して画像デコードとノイズ除去を行いました。(ノイズ除去強度(再描画強度)は0.4以上で明確な効果が得られ、通常は0.4または0.5を使用)
後段のモデル拡大時に、画像→画像拡大の拡散プロセスでNoobのepsv1.1モデルを使用しつつ、モデルのサンプリングアルゴリズムノードでv予測を選択して画像デコードとノイズ除去を行いました。(ノイズ除去強度(再描画強度)は0.4以上で明確な効果が得られ、通常は0.4または0.5を使用)
During the process of image-to-image upscaling with the diffusion model after the later-stage model upscaling, the noob eps v1.1 model was employed, but the v prediction was selected for image decoding and denoising at the model's sampling algorithm node. (The denoising strength (redraw strength) has been tested to show a more noticeable effect above 0.4, commonly used at 0.4\0.5).
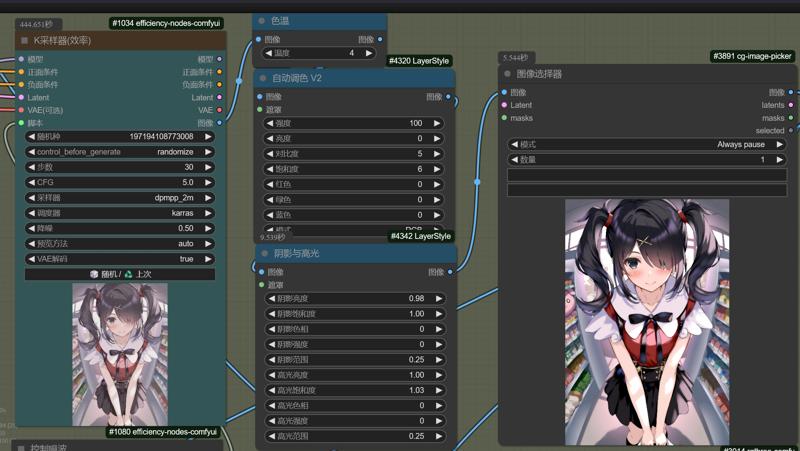
 ただし、epsv1.1バージョンはv予測に特化していないため、最初に生成された画像は色温度が暖色寄りになり、コントラストや彩度が低下する傾向があります。この問題については、Layerstyleノードパッケージ内の色温度、自動カラーバランスv2、シャドウとハイライトなどの調整ノードを用いて、画像パラメータを自動的に補正することで、大幅に緩和できると私は考えています。(以下は参考値であり、さらに良い効果をもたらす他のパラメータを探しています)
ただし、epsv1.1バージョンはv予測に特化していないため、最初に生成された画像は色温度が暖色寄りになり、コントラストや彩度が低下する傾向があります。この問題については、Layerstyleノードパッケージ内の色温度、自動カラーバランスv2、シャドウとハイライトなどの調整ノードを用いて、画像パラメータを自動的に補正することで、大幅に緩和できると私は考えています。(以下は参考値であり、さらに良い効果をもたらす他のパラメータを探しています)
Certainly, since the eps v1.1 version is not specialized for v prediction, the initially generated images may exhibit issues such as a warm color bias, reduced color contrast, and saturation. Regarding this issue, I believe that a series of adjustment nodes in the Layerstyle node package, such as color temperature, auto color v2, and shadows and highlights, can be utilized to automatically adjust the image parameters, thereby significantly alleviating this problem. (The parameters provided here are for reference only, and I am also exploring whether there are other parameters that could yield better results.)
3: プロンプトトリガーワードのルール
(1):画風トリガーワードのフォーマットと分類:misaki_kurehito_xxx
<1>早期(early)(2006-2014):misaki kurehito 1
<2>中期(mid)(2015-2018) :misaki kurehito 2
<3>晚期(latest)(2018-2024):misaki kurehito 3
例: <1girl/1boy/1other/...>,
masterpiece,best quality,absurdres,highres,sensitive,newest,
4: 生成パラメータ(例)(Comfy UI):
lora weight: 1
Using Efficiency nodes (restore Web UI usage)(効率ノードを使用してWeb UIパラメータを再現、Web UIでは無視可能)
Using PAG Node(default) PAGノード使用(デフォルト設定)
steps: 30\28
CFG: 5\4
sampler: dpmpp_2m (Web UI: dpm2p_m karras?)
scheduler: karras
For SanaeXL Lokr v1.0 早苗底膜v1.0 Lokrモデル
1:本モデルはSanaeXL anime V1.0ベースのSDXL LoKRモデルであり、VAEにはsdxl_vaeを使用しています。
1:This model is a sdxl-lora based on SanaeXL anime V1.0.Using sdxl_vae as a vae.
ATTENTION !As a kind of Lycoris model, most of times its usages are as same as the sdxl lora. However, lokr CANNOT be used on some batch nodes on Comfy UI (e: Lora stack). You can use the XYZ PLOT on Web UI to achieve similar functionality !!!
注意!Lycorisモデル系列に属するLoKRモデルであり、ほとんどの場合通常のLoRAと同様に使用できますが、ComfyUIの一部のバッチノード(例:Lora stack)では使用できません!同様の機能を実現するには、Web UIのXYZ PLOT機能をご使用ください!!!
加注:本モデルの表示画像は、テキストから画像への生成(1024x1024)と高解像度拡大(2048x2048)のみで生成されています。
Tips: Pictures showed on the screen were only generated by t2i (1024x1024) and hire-fix (2048x2048).
2: 早苗底膜のタグ配置ルール:
推奨設定 / Recommended settings
prompt:
<1girl/1boy/1other/...>,
masterpiece,best quality,absurdres,highres,sensitive,newest,
negative prompt (short) :
lowres,low quality, worst quality, normal quality, text, signature, jpeg artifacts, bad anatomy, old, early, multiple views, copyright name, watermark, artist name, signature
negative prompt (long) :
lowres,bad anatomy,blurry,(worst quality:1.8),low quality,hands bad,(normal quality:1.3),bad hands,mutated hands and fingers,extra legs,extra arms,duplicate,cropped,jpeg,artifacts,blurry,multiple view,reference sheet,long body,multiple breasts,mutated,bad anatomy,disfigured,bad proportions,bad feet,ugly,text font ui,missing limb,monochrome,bad anatomy,blurry,(worst quality:1.8),low quality,hands bad,face bad,(normal quality:1.3),bad hands,mutated hands and fingers,extra legs,extra arms,duplicate,cropped,jpeg,artifacts,blurry,multiple view,long body,multiple breasts,mutated,disfigured,bad proportions,duplicate,bad feet,ugly,missing limb,
ネガティブプロンプトには必ず「lowres」を含めてください(低解像度画像を大量にトレーニングに使用したため)。「worst quality」と「low quality」は個人の好みに応じて追加可能です。また、例画像に示されている長いネガティブプロンプトを使用しても構いません。この文字列は内部メンバーがテスト中に使用したもので、非常に「ごちゃごちゃ」していますが、その効果は確認できません。「ただ動く」からです。
Negative prompts must include: lowres (due to the use of a large number of low-resolution images for training). "worst quality" and "low quality" can be added based on personal preference. You can also use the negative prompts (long) shown in the example images. This string of prompts was used by internal members during testing. It is quite "shitty", and we cannot confirm its effectiveness, but "it just works."
3: プロンプトトリガーワードのルール
(1):画風トリガーワードのフォーマットと分類:misaki_kurehito_xxx
<1>早期(early)(2006-2014):misaki kurehito 1
<2>中期(mid)(2015-2018) :misaki kurehito 2
<3>晚期(latest)(2018-2024):misaki kurehito 3
例: <1girl/1boy/1other/...>,
masterpiece,best quality,absurdres,highres,sensitive,newest,
4: 生成パラメータ(例)(Comfy UI):
lora weight: 1
Using Efficiency nodes (restore Web UI usage)(効率ノードを使用してWeb UIパラメータを再現、Web UIでは無視可能)
Using PAG Node(default) PAGノード使用(デフォルト設定)
steps: 30
CFG: 7
sampler: dpmpp_2m (Web UI: dpm2p_m karras?)
scheduler: karras