di.FFUSION.ai Text Encoder - SD 2.1 LyCORIS








詳細
ファイルをダウンロード
モデル説明
di.FFUSION.ai-tXe-FXAA
121361枚の画像で訓練済み。

独自に事前トレーニングされたUnetを使用して、モデルの品質とシャープネスを向上させましょう。
テキストエンコーダー(UNetを除く)はLyCORISでラップされています。オプティマイザ:torch.optim.adamw.AdamW(weight_decay=0.01, betas=(0.9, 0.99))
ネットワーク次元/ランク:768.0 Alpha:768.0 モジュール:lycoris.kohya {'conv_dim': '256', 'conv_alpha': '256', 'algo': 'loha'}
Lyco CONV 256のため、容量が大きめです。


a1111用
https://github.com/KohakuBlueleaf/a1111-sd-webui-lycoris をインストール
di.FFUSION.ai-tXe-FXAA を /models/Lycoris にダウンロード
オプション1:
プロンプトに lyco:[di.FFUSION.ai](http://di.FFUSION.ai)\-tXe-FXAA:1.0 を挿入
UNetとテキストエンコーダーを分ける必要はありません。テキストエンコーダーは1つだけです。
重みは最大2倍まで可能
オプション2: 常に有効にしておきたい場合(例:テキストファイルからバッチ実行する場合)は、設定 / クイック設定リストへ移動して
sd_lyco を追加
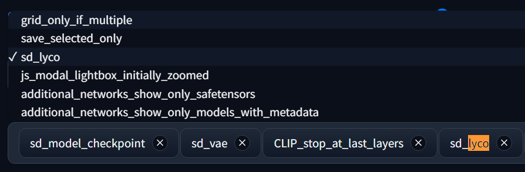
再起動後、ドロップダウンが使えるようになります 🤟 🥃
詳細情報:
"ss_text_encoder_lr": "1e-07",
"ss_keep_tokens": "3",
"ss_network_args": {
"conv_dim": "256",
"conv_alpha": "256",
"algo": "loha"
},
"img_count": 121361
}
"ss_total_batch_size": "100",
"ss_network_dim": "768",
"ss_max_bucket_reso": "1024",
"ss_network_alpha": "768.0",
"ss_steps": "2444",
"sshs_legacy_hash": "539b2745",
"ss_batch_size_per_device": "20",
"ss_max_train_steps": "2444",
"ss_network_module": "lycoris.kohya",
このモデルは、粗雑なキャプション(迅速なWDタグや酷いCLIP)でも試験的に運用可能な、重い実験版です。その結果は満足できるものでした。
注意:これは公式のFFUSION AIモデルで使用されているテキストエンコーダーではありません。