IT'S ALIVE! | Ultimate IMAGE to VIDEO suite | LTX/Cog/PyramidFlow



詳細
ファイルをダウンロード
このバージョンについて
モデル説明
バズらないで大丈夫です、私は元気です。💗 フィードバックの方がずっとありがたいです。
より多くの動画例については、以前のバージョンをご確認ください。
クレジットと謝辞は下部に記載しています。
このComfyUIワークフローは、6つの動画モデルを使用してI2V(画像から動画)を生成するさまざまな方法を提供します:
LTX
CogVideoX-5B-1.5-I2V
Pyramid Flow
CogVideoX-Fun-v1.1-InP (2B)
CogVideoX-Fun-v1.1-InP (5B)

⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️
このワークフローは高速かつ使いやすく設計されており、必要なすべての設定がフロントエンドUI(コンソール)に統合されているため、多数のモジュールを頻繁に切り替えなくても、高品質な動画を迅速に作成できます。また、複数のカスタムノードのインストールを必要とする、私が実際の使用中に取り入れたさまざまな実験的メソッドも組み込まれています。
そのため、このワークフローは初心者には推奨されません。
よりシンプルな体験をご希望の場合は、zipファイルに含まれるMINI版をご利用ください。これはフルワークフローの簡易版です。
このワークフローには、さまざまな動画モデルを実際に使用した経験に基づいた設定が含まれており、通常のモデル標準設定とは異なる場合があります。
- - - | IT'S ALIVE | - - -
これは1か月以上、ほぼ毎日取り組んだ結果です。
私は今も改善を続け、実験中に見つけた有用な設定を最適化・追加しています。
このワークフローは、コントロールルーム(コンソール)から一切離れずに操作できるように設計されています。
必要なすべての機能が手の届く場所にあります。
さらに、キーボードショートカットで追加の調整コマンドを利用できます(詳細は以下を参照)。
異なる手法が用意されており、スライダーで選択できます:

Creative(創造的): このモードでは、単一の画像を入力として使用し、モデルが完全な創造的自由で動画を生成し、自らの終わりを決定します。
*この手法は、メニューで利用可能なすべての動画モデルで動作します。Sticky(固定): このモードでは、単一の画像を入力とし、ワークフローは入力画像と似た最終フレームを自動生成します(人物が検出された場合、やや異なる視点や表情・頭部の位置になります)。この入力画像を参照・類似した新しい画像は、「Tweaking(微調整)」セクションで利用可能なスライダーを使って微調整できます。これにより、動画全体を通じて構図を維持できます。
*この手法は(現時点では)COGモデルでのみ動作するため、コンソールで有効化してください。Zoom(ズーム): このモードでは、単一の画像を入力とし、動画の最終フレームは入力画像のズームアップ版になります。ズームレベルは「Tweaking」メニューで調整できます。*この手法は(現時点では)COGモデルでのみ動作します
Img1→Img2(カスタム開始/終了モード):このモードでは、2枚または3枚の画像を入力として使用し、モデルがそれらの間の遷移を生成できます。制御されたアニメーションに特に有用で、5B COGモデルで優れた結果を出します。*この手法は(現時点では)COGモデルでのみ動作します
Img1→Img1:このモードでは、単一の入力画像を開始および終了フレームとして使用し、入力画像の構図を維持することに重点を置きます。*この手法は(現時点では)COGモデルでのみ動作します
ショートカット:
3つのキーボードキーを使用して、必要なセクションのみを素早く移動できます:
1 = CONSOLE
「1」キーを押すと、すべての設定が簡単にアクセスできるコンソールに移動します。

2 = TRAJECTORIES (TORA - COG)
「2」キーを押すとTora Trajectoriesに移動します。
この手法はCOGモデル専用です。
このワークフローでTORAと互換性のある唯一のモデルは「5BInP」であり、以下のように選択する必要があります:

4つの組み合わせ可能なトラジェクトリーが利用可能です。
コンソール内の専用スライダーを使って、1つ、2つ、3つ、またはすべて4つのトラジェクトリーを有効化できます:
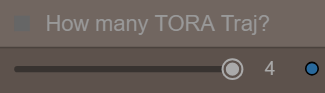
ベース解像度や入力画像を変更するたびに、すべてのトラジェクトリーを再設定する必要があることに注意してください。

3 = TWEAKING
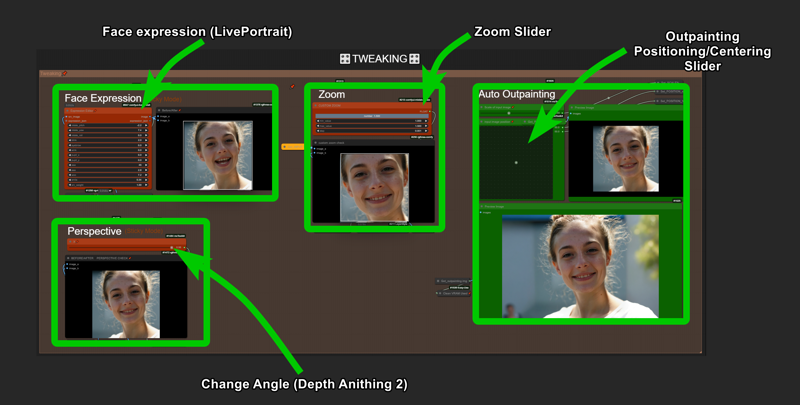
「3」キーを押すとTweakingセクションに移動します。
ここで、Stickyモードの最終フレームを、入力画像とほぼ同じですが、わずかに異なる視点・角度または表情・頭部の位置で調整できます。これにより、最終フレームが初期画像と類似またはほぼ同一のまま、細かい変化を加えることが可能になります。
右側ではAuto Outpaintingが利用可能で、必要に応じて結果をコピーして入力画像として貼り付けることができます(Outpaintingはコンソールで有効化する必要があります)。
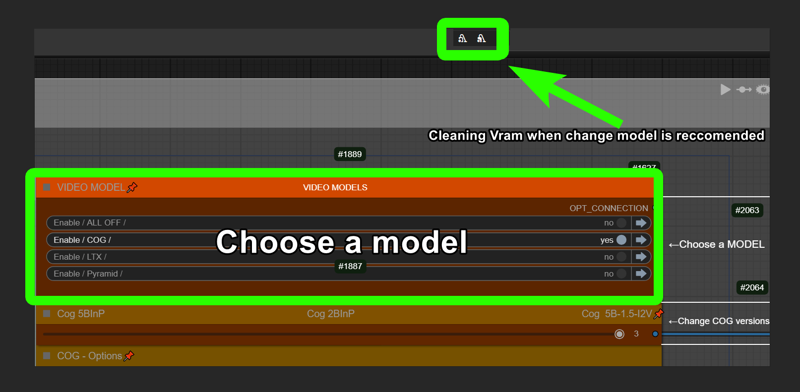
モデルを変更する際にはVRAMのクリアを推奨します:
### トラブルシューティング:
コンソールに表示されるこのエラーメッセージは完全に正常です:

### 最低ハードウェア要件:
低解像度の場合、12GB VRAMが必要です。
### レンダリング時間:
3090では、モデル・解像度・ステップ数に応じて、各動画のレンダリングに5秒から2分以上かかります。
### 重要なCOGの提案と例:
- 良く一貫した結果を得るには、「First/Last」モードを使用する場合、2つの画像は似たもの(同じ場所、同じ人物、ほぼ同じ位置関係)である必要があります。例:どのような画像でも選べますが、最も良い結果を得るには、互いに類似した2つの画像を使用してください。例えば、ランダムなインターネット動画のスクリーンショット2枚、異なるポーズをとった2つの3Dキャラクター、または類似したAI生成画像などです 🙄
- ステップ数は10〜15程度に留めてください。品質を向上させるには、より多くのステップを設定してください。(それ以下では安定しないことが多いですが、5ステップでも良い結果を得たことがあります。)
- 簡単なテストの際は、低いベース解像度(例:320)を使用してください。この解像度では、私の3090では約10秒で処理できます。
- 結果にアーチファクトが多い場合は、「カスタムプロンプトのみ」に切り替え、自動プロンプト生成を無効にして、プロンプトを単純化すると、より安定した一貫性のあるアニメーションが得られます。シンプルな文を書いてください。
(ワークフロー内に記載されたマニュアルを参照してください)
「a person posing, blink, camera shake」のようなシンプルなプロンプト、または単語 wiggle, earthquake, lens flares, blink, camera shake, handheld camera は、ここで既に成功しています。あなたの発見を共有してください!
- 動画が設定に比べて速すぎる場合は、グループ内で補間をオンにし、「追加補間倍率」を上げるか、ワークフロー内に記載されたユーザー手册に従ってCOG設定グループの動画長を調整してください。
### その他の注意点:
COGモデルを多数テストし、標準設定ではなく、私のテストに基づいてより良い・より速い設定に変更しています。
自分で設定を変更してください(より良い設定を見つけた場合は、ぜひ教えてください!)
no need to buzz me, i'm fine. ty💗 feedbacks are much more appreciated.
*ご注意:
複数のCogモデルはそれぞれ異なりますので、混同しないでください。
他のCogモデルがどの程度の機能を持つか、ぜひ調べてみてください。現在、混乱が生じています。
Kijayが作成したこのスプレッドシートで、一部の誤解を解消できます:
https://docs.google.com/spreadsheets/d/16eA6mSL8XkTcu9fSWkPSHfRIqyAKJbR1O99xnuGdCKY/edit?gid=0#gid=0
一般的に、迅速に動画を生成し、最もダイナミックなオプション、解像度、アスペクト比、First/Last、トラジェクトリーをご希望の場合は、このワークフローをそのまま使用するか、少なくともこのワークフローで使用しているモデルを利用することを推奨します。
TORAが現在、このXFUNバージョンのCOGと互換性があるため、このワークフローに追加しました。
変更履歴:
V8.0
変更内容:
ワークフロー全体を完全に再設計し、整理・論理を最適化しました。
3つの動画モデルを追加
自動アウトペイントを追加
LivePortraitを追加
Creativeモードが正常に動作するようになりました(終了画像を指定しなくても動画を生成可能)
ほんとに、完成まで1週間かかりました。
V7.0
変更内容:
- ワークフローの整理とバグ修正
V6.0
変更内容:
4つのToraトラジェクトリーを追加
UIコントロールを強化
設定、改良、ヒントを追加
TORAを使用するには、5Bモデルを使用していることを確認してください(2Bから5Bに切り替えるスイッチがあります)。
その後:
グループで「Let's Cog」を無効化
画像を読み込み、実行
4つのトラジェクトリーを設定(複数の点でスプラインを分割するにはCtrl+クリック)
「Let's Cog」を有効化して実行(「Extend video」は「Let's Cog」を有効化すると自動でオンになりますが、現時点では無効にしてください。TORAモードの拡張方法を私はまだ確立していません)
V5.0
変更内容:
Extra Extend(3枚の画像を使用して動画を生成する機能)を追加
UIコントロールを強化
設定、改良、ヒントを追加
V4.0
変更内容:
Extendがすべてのモード(First/Lastモードを除く)で動作するようになりました
改善されたUI
+ LoRA強度スライダー
+ シード管理
+ プロンプト強度
+ COGフレーム数制御
+ モデルセレクター 2B/5B
+ ネガティブプロンプト
その他の変更:
効率の改善
完全に見直されたチェーンシステム
いくつかの小さな修正
V3.0
|更新履歴|:
改善されたUI:
LoRAローダーと強度スライダーを追加
モデルセレクター 2B/5B
ネガティブプロンプト
いくつかのワークフロー効率の改善
その他の変更:
より高速な補間方法に変更
いくつかの小さな修正
ユーザーマニュアルを更新
V2.0
|更新履歴|:
より洗練されたワークフロー
より多くのオプション
簡単なUI
ユーザーマニュアルを追加
Kijai、Purz、およびRgthree、DreamProject、VideoHelperSuiteのチームに感謝します。彼らが私にとって不可能だと感じていたいくつかのステップの解決に時間を割いてくれました。
ぜひ彼らのページを訪れて、プロジェクトをサポートしてください。