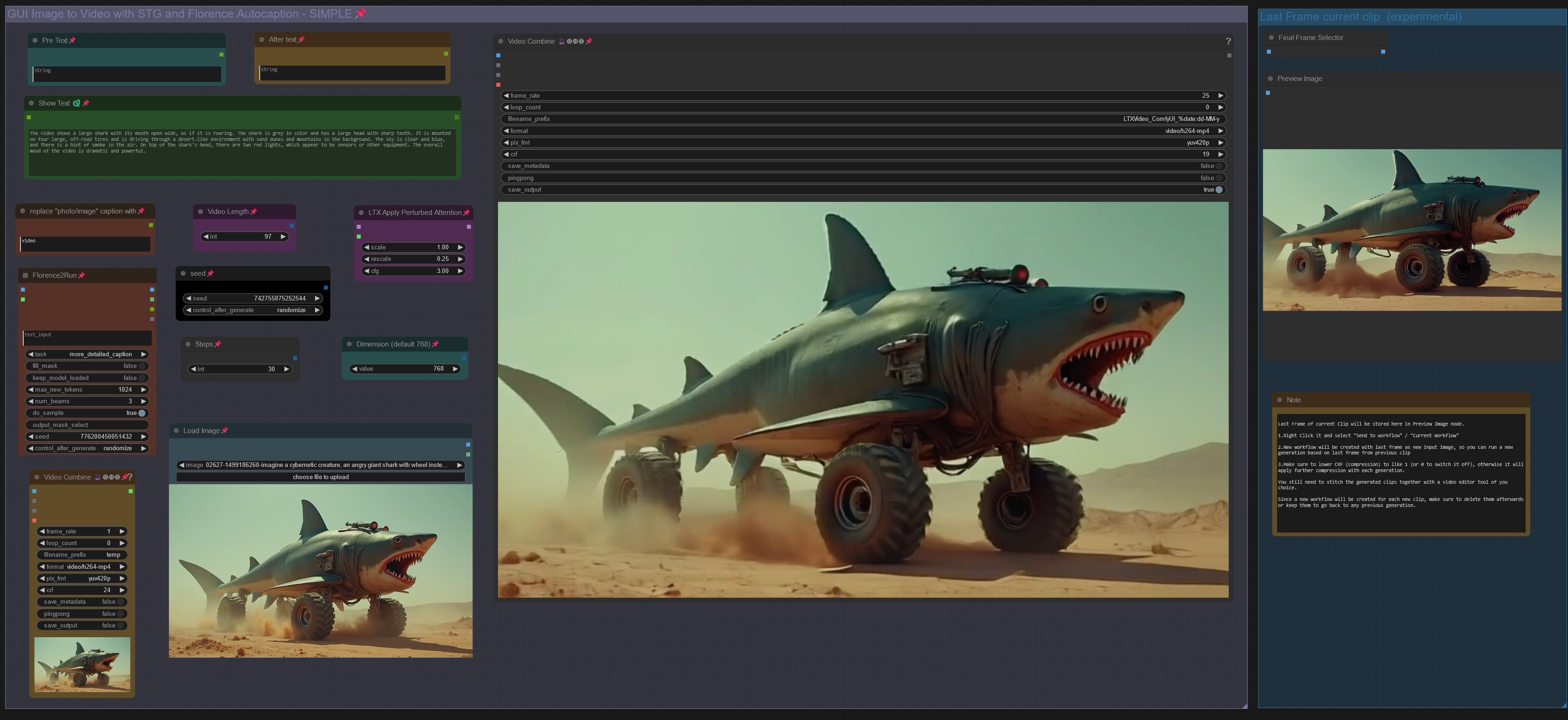
LTX IMAGE to VIDEO with STG, CAPTION & CLIP EXTEND workflow

詳細
ファイルをダウンロード
このバージョンについて
モデル説明
ワークフロー:画像 -> 自動キャプション(プロンプト)-> LTX 画像から動画へ
2025年7月20日更新: LTX 0.9.8 のための GGUF モデル:
蒸留モデル(V9.5 互換):https://huggingface.co/QuantStack/LTXV-13B-0.9.8-distilled-GGUF/tree/main
開発モデル(V9.0 互換):https://huggingface.co/QuantStack/LTXV-13B-0.9.8-dev-GGUF/tree/main
(上記リンクの「Model Card」で LTX 0.9.8 の VAE とテキストエンコーダーのダウンロード情報をご確認ください)
V9.5:LTX 0.9.7 蒸留ワークフロー(LTX 0.9.7 蒸留 GGUF モデル対応)
Florence を使用したワークフローと、LTX プロンプト強化器(LTXPE)を使用したワークフローの2つがあります。
GGUF モデルのダウンロードはこちら:
https://huggingface.co/wsbagnsv1/ltxv-13b-0.9.7-distilled-GGUF/tree/main
VAE および テキストエンコーダー は、以前の LTX 0.9.6 モデルと同一です(下記 V8.0 を参照)。
LTX 0.9.7 蒸留版は8ステップのみで動作し、非常に高速です。
V9.0:LTX 0.9.7 ワークフロー(LTX 0.9.7 GGUF モデル対応)
Florence を使用したワークフローと、LTX プロンプト強化器(LTXPE)を使用したワークフローの2つがあります。
GGUF モデルのダウンロードはこちら:
https://huggingface.co/wsbagnsv1/ltxv-13b-0.9.7-dev-GGUF/tree/main
VAE および テキストエンコーダー は、以前の LTX 0.9.6 モデルと同一です(下記 V8.0 を参照)。
LTX 0.9.7 は130億パラメータのモデルであり、以前のバージョンは20億パラメータのみでした。そのためVRAM使用量が多く、処理時間が長くなります。非常に高速なレンダリングが必要な場合は、下記の V8.0(0.9.6モデル)または V9.5 をお試しください。
V8.0:LTX 0.9.6 ワークフロー(開発版と蒸留版のGGUFモデルを同じワークフローでサポート)
Florence2 キャプション版と、LTX プロンプト強化器(LTXPE)版の2つのバージョンがあります。
GGUF モデル(開発版および蒸留版)のダウンロードはこちら:
https://huggingface.co/calcuis/ltxv0.9.6-gguf/tree/main
VAE: pig_video_enhanced_vae_fp32-f16.gguf
テキストエンコーダー: t5xxl_fp32-q4_0.gguf
V7.0:LTX 0.9.5 モデル版(Wavespeed/Teacache 対応 GGUF)
LTX 0.9.5 GGUF モデルおよび VAE:https://huggingface.co/calcuis/ltxv-gguf/tree/main
(vae_ltxv0.9.5_fp8_e4m3fn.safetensors)
Clip テキストエンコーダー:https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf/tree/main
2つのワークフローがあります:Florence キャプションのみを使用するメインワークフローと、Florence と LTX プロンプト強化器を併用する追加ワークフロー。Wavespeed で設定(デフォルトでは無効、Strg+B で有効化)
このワークフローはすべての GGUF モデル(0.9 / 0.9.1 / 0.9.5)で動作します。
プロンプト強化用の無修正 LLM:https://huggingface.co/skshmjn/unsloth_llama-3.2-3B-instruct-uncenssored
- 2025年3月時点旧バージョン - V6.0:GGUF/TiledVAE版 および マスク付きモーションブラー版
ワークフローを GGUF モデルで更新し、VRAMを節約し、高速化しました。
スタンダード版(GGUF モデルのみ使用)と、GGUF+TiledVae+Clear Vram版(さらにVRAM使用量を削減)の2つがあります。1024解像度、161フレーム、32ステップで大きな GGUF モデル(Q8)をテストしたところ、GGUF版ではVRAM使用量が最大14GB、TiledVae+ClearVram版では最大7GBに抑えられました。より小さな GGUF モデルを使えば、さらにVRAM使用量を削減できます。
GGUF モデル、VAE、テキストエンコーダーのダウンロードはこちら:
(モデル&VAE):https://huggingface.co/calcuis/ltxv-gguf/tree/main
(アンチチェッカーボードVAE):https://huggingface.co/spacepxl/ltx-video-0.9-vae-finetune/tree/main
(Clip テキストエンコーダー):https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf/tree/main
VRAMが16GB以上の場合は GGUF 版、16GB未満の場合は TiledVae+ClearVram 版をお使いください。
マスク付きモーションブラー版:LTXはモーションブラーが発生しやすいため、入力画像にマスクを設定し、マスク部分にモーションブラーを適用することで特定の動きを誘発する追加グループを追加しました(実際の効果は説明ほどではありませんが、一部のケースでは有用です)。GGUF版およびGGUF+TiledVAE+ClearVram版を含みます。
V5.0:新しい LTX モデル 0.9.1 のサポート
- LowVRAM版(VAE前にVRAMを解放)の追加ワークフローを含みます。
- LTX モデル 0.9.1 と 0.9 の比較用ワークフローを追加しました。
(V4はモデルリリース当時は0.9.1と互換性がなく、そのためにV5が作成されました。その後、ComfyUIとノードが更新され、現在ではV4でも0.9および0.9.1の両モデルを使用できます。V5でも同様です。両方ともモデル管理用のカスタムノードが異なりますが、その他は同じです。メモリや処理時間の問題が発生した場合は、最後のヒントをご覧ください)
- 2025年3月時点旧バージョン - V4.0: 動画/クリップ拡張機能の導入
前のクリップの最終フレームを基に、クリップを拡張できます。品質が劣化し始める前に約2〜3回まで拡張可能です。詳細はワークフローの説明をご覧ください。
Florenceキャプションをバイパスし、独自のプロンプトを使用する機能を追加しました。
V3.0:STG(Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling)の導入
シンプル版と強化版の2つのワークフローを含みます。強化版は入力画像のアップスケール機能を追加しており、一部のケースで役立ちます。シンプル版の使用をお勧めします。
高さ/幅ノードを「Dimension」ノードに置き換え、動画サイズを制御します(デフォルト = 768。1024に増やすと解像度が向上しますが、動きが減少し、VRAMと処理時間が増加する可能性があります)。以前のバージョンと異なり、画像は切り抜かれません。
「LTX Apply Perturbed Attention」ノードを追加(STG設定を表します。値/制限についてはワークフロー内の説明を参照)。
強化版には、入力画像をアップスケールするか否か(true/false)を設定するスイッチと、画像の拡大倍率(1または2)を設定する値が含まれます。これはスーパーサンプリングのように機能しますが、ほとんどの場合不要です。
プロのヒント:動きを誘発するには、CRF値を約24に設定するだけでなく、黄色い「Video Combine」ノードのフレームレートを1から4以上に上げることで、出力が静的すぎる場合にさらに動きを引き出せます。
「Modify LTX Model」ノードはセッション中にモデルを変更します。別のワークフローに切り替える際は、ComfyUIで「Free model and node cache」をクリックして干渉を避けてください。このノードをバイパス(Strg+B)すると、テキストから動画への変換(Text2Video)が可能です。
V2.0:Florence2 自動キャプション対応の画像→動画 ComfyUI ワークフロー(v2.0)
この更新されたワークフローは、バージョン1.0で使用していたBLIPに代わってFlorence2を自動キャプションに統合し、動画生成向けにプロンプトを調整するための改善されたコントロールを備えています。
v2.0の新機能
Florence2 ノードの統合
キャプションのカスタマイズ
- 新しいテキストノードにより、キャプション内の「photo」や「image」といった用語を「video」に置き換えることができ、プロンプトを動画生成に適した形に整形できます。
V1.0:圧縮による動きの強化
LTX 動画モデルにおける「動きなし」アーティファクトを軽減するため:
入力画像を FFmpeg を使用し、CRF値20~30でH.264圧縮します。
このステップにより、微細なアーティファクトが発生し、モデルが入力を映像のように認識する助けになります。
CRF値は黄色い「Video Combine」ノード(GUI左下)で調整可能です。
高い値(25~30)は動きを強調し、低い値(約20)は視覚的忠実度を維持します。
自動キャプションの強化
Pre-Text と After-Text のテキストノードにより、キャプションに手動で追加が可能です。
- カメラの動きなどの望ましい効果を記述するのに使用してください。
調整可能な入力設定
- 幅/高さおよびスケール:サンプラーの画像解像度を定義します(例:768×512)。スケール係数2を使用すると、スーパーサンプリングで高品質な出力が可能になります。スケール値は1または2を使用してください。(V3ではDimensionノードに変更)
プロのヒント
動きの最適化:出力が静的だと感じる場合は、CRF値とフレームレートを段階的に上げるか、Pre-/After-Textノードを調整して動きに関連するプロンプトを強調してください。
キャプションの微調整:Florence2のキャプション詳細レベルを試して、繊細な動画プロンプトを生成してください。
メモリ問題(OOMまたは処理時間の極端な長さ)が発生した場合は、以下の対策をお試しください:
V5のLowVRAM版を使用する
GGUF版を使用する
ComfyUIで「Free model and node cache」をクリックする
ComfyUIの起動引数に --lowvram --disable-smart-memory を追加する
- ComfyUIフォルダ内のファイル「run_nvidia_gpu.bat」を編集し、次の行を変更してください:
python.exe -s ComfyUI\main.py --lowvram --disable-smart-memory
- ComfyUIフォルダ内のファイル「run_nvidia_gpu.bat」を編集し、次の行を変更してください:
ブラウザのハードウェアアクセラレーションを無効にする
クレジット:Lightricks 社の素晴らしいモデルとノードへ: