WAN Video YAW Workflow 1.6 V2V T2V I2V, upscale, extend, audio, interpolate, random-lora, preview pause, upscale, multi-res, interpolate,prompt save/load

세부 정보
파일 다운로드
이 버전에 대해
모델 설명
Beta 1.6 - 새로운 실험적 품질/옵션. 가이던스 건너뛰기(품질), CFGZeroSTar(프롬프트 준수), Enhance-A-Video(품질). Re-Actor(얼굴 복원) 다시 추가됨. 문제가 발생하면 비활성화한 채로 두세요. 워크플로우는 여전히 작동합니다. 페이지 하단의 지침을 사용하여 비활성화하세요.
** Torch Compile이 LoRA를 손상시킬 수 있습니다. 최신 Torch 및 Blackwell NVIDIA에서 이 문제를 확인했습니다.
Beta 1.5 - 더 빠르고, 많은 QoL 및 버그 수정, 추가로 테스트된 해상도, NVIDIA Blackwell 50XX 호환 노드.
** 5090/5080/5070 50xx 시리즈 NVIDIA GPU 관련 수정 사항은 문제 해결 섹션에 있습니다.
이 워크플로우는 제 Hunyuan YAW(Yet another workflow)를 기반으로 한 WAN 비디오 워크플로우입니다. 초보적 단계이지만 작동합니다. WAN 개발이 계속됨에 따라 Hunyuan 버전과 동일한 기능을 제공하고자 합니다. Beta 1.2에서 V2V, GGUF 멀티-GPU 시스템이 시스템 RAM을 VRAM으로 사용하도록 추가되었습니다. 더 많은 테스트된 해상도, Teacache 가속 기능이 도입되었습니다.
빠른 관찰:
단계 수를 늘리면 품질이 향상됨을 확인했습니다. I2V에서는 비표준 해상도를 사용할 때 이상한 색상과 번쩍임이 발생합니다. 해상도 선택기에서 일부 테스트된 I2V 해상도를 확인하세요. 해상도만 변경하여 색상 번쩍임 문제를 해결할 수 있었습니다. 여전히 원래 워크플로우와 기능을 동일하게 맞추는 작업 중입니다.
모델 오류가 발생하고 모든 모델을 다운로드하지 않았다면, "모델 로더"로 이동해 다운로드하지 않은 모델을 마우스 오른쪽 버튼으로 클릭 후 "우회"하세요. 예를 들어 GGUF 모델을 사용하지 않는 경우, 녹색 및 연회색 #2를 모두 마우스 오른쪽 버튼으로 클릭하여 우회하세요.
* 워크플로우의 Hunyuan 버전이 더 많은 기능을 포함합니다: /model/1134115/
자세한 내용은 아래의 전체 지침을 읽어주세요.
워크플로우 주요 특징:
오디오 생성 - MMaudio를 통해 - 비디오에 오디오 렌더링, 오디오 전용 후처리를 위한 별도 플러그인 제공.
업스케일 전 일시 정지(옵션)
- 전체 길이 렌더링 전에 비디오 미리보기
LoRA 랜덤라이저 - 12개의 LoRA가 2개의 스택으로 구성되어 있으며, 랜덤화하고 혼합할 수 있습니다. 와일드카드, 트리거, 프롬프트 포함. 무작위 캐릭터 + 무작위 동작/스타일을 상상한 뒤 와일드카드를 추가하면 완벽한 야간 생성 시스템이 완성됩니다.
프롬프트 저장/불러오기/이력
여러 해상도
- 선택기에서 6가지 일반적인 해상도를 빠르게 선택하세요. 최대 6개의 사용자 정의 해상도를 사용할 수 있습니다.
여러 업스케일 방법
표준 업스케일
보간(프레임 레이트 두 배)
여러 LoRA 옵션
- 더블 블록(여러 LoRA를 결합할 때 가중치를 신경 쓰지 않아도 더 잘 작동)
와일드카드 기능을 통한 프롬프팅
모든 옵션은 토글 및 스위치로 구성되어 있어, 노드를 수동으로 연결할 필요가 없습니다.
설정 방법에 대한 자세한 설명
얼굴 복원
텍스트 2 비디오, 이미지 2 비디오
3090(24GB VRAM)에서 테스트됨
이 워크플로우는 초보자에게는 사용하기 쉬우며, 고급 사용자에게는 유연한 구조를 제공합니다.
이것은 제 첫 번째 워크플로우입니다. 저 자신이 비디오 제작을 위한 옵션이 필요했기 때문에, 이 작업을 시도해 보았습니다.
추가 세부 정보:
** 문제 해결 노드 또는 ComfyUI 관리자는 이 문서 하단에 있습니다.
빠른 시작 가이드:
기본적으로 모든 설정은 작동하는 워크플로우를 위해 조정되었습니다.
이 워크플로우를 T2V(주요 초점)에 사용하는 방법은 2가지입니다.
#1 - 단일 스테이지 렌더링, 업스케일러에서 보간까지
워크플로우에서 1abc, 2, 4, 5를 활성화하세요. (3은 건너뜁니다)
해상도 선택기에서 테스트된 연한 파란색 해상도 중 하나를 선택하세요. (이것은 공식적으로 지원되는 WAN 해상도인 480p/720p입니다. 이러한 해상도는 더 크므로 스테이지 1이 더 오래 걸립니다.)
스테이지 1 단계를 25 이상으로 설정하세요. 이는 1패스 렌더링을 수행합니다.
#2 - 2스테이지 렌더링 (권장)
워크플로우에서 1abc, 2, 3, 4, 5를 활성화하세요.
해상도 선택기에서 보라색(LQ) 해상도 중 하나를 선택하세요.
스테이지 1 단계를 14로 설정하세요.
스테이지 2 단계를 25로 설정하세요.
이렇게 하면 빠른 미리보기 렌더링을 통해 개념과 LoRA가 올바르게 작동하는지 확인할 수 있습니다. (~3090에서 약 1분) 이는 272x368과 같은 저해상도여야 하므로 빠르게 처리됩니다. 빠른 미리보기가 완료되면 일시 정지되며, 미리보기를 기반으로 전체 렌더링을 계속할지 여부를 선택할 수 있습니다. 전체 렌더링은 자동으로 출력 해상도를 두 배로 증가시키며 이것이 스테이지 2입니다. 그 후 업스케일러가 다시 해상도를 두 배로 증가시키고, 보간기가 프레임 레이트를 두 배로 증가시킵니다. 이것이 Hunyuan 버전 워크플로우의 핵심 개념입니다. 빠른 프로토타이핑 및 최고의 개념을 렌더링하기 위한 것입니다. 따라서 272x368의 저해상도 렌더링이 스테이지 2에서 544x736, 업스케일링 후 1088x1472로 증가합니다.
워크플로우 작동 방식의 세부 사항:
스텝 0. 모델 설정: "모델 로드" 섹션에서 해상도를 선택하세요.. (안타깝게도 WAN에 적합한 해상도 목록을 결정할 시간을 갖지 못했습니다. 512x512, 640x480, 1280x720은 VRAM에 따라 모두 작동하는 것으로 확인되었습니다. 풍경 또는Portrait에 따라 다릅니다. 일반적으로 16:9가 더 유연하고, 3:4는 품질이 더 높지만 영상 길이가 제한됩니다. 이는 모든 GPU VRAM에 따라 다릅니다. 기본 단계와 비디오 길이로 시작하세요.
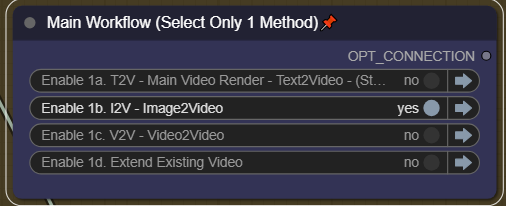
스텝 1. 1a/1b/1c를 사용해 T2V 또는 I2V 수행
스텝 2. 미리보기를 기반으로 업스케일러로 계속할지 판단
스텝 3. 프레임별 업스케일러를 사용하여 해상도를 다시 두 배로 증가
스텝 4. 프레임 레이트를 16fps에서 32fps로 증가시켜 부드러운 움직임 생성
(옵션 스텝) MMaudio 생성 활성화 - 텍스트 프롬프트와 비디오를 기반으로 비디오에 맞는 사운드를 생성합니다. 텍스트 프롬프트에 장면의 사운드를 상세히 설명하면 더 나은 생성이 가능합니다. 이 기능은 VRAM을 더 많이 사용하므로 기본적으로 비활성화되어 있습니다. 나중에 별도의 MMaudio 플러그인을 통해 오디오 생성을 추가할 수 있습니다.
이제 단계 수, 비디오 길이, 해상도 등을 조정하여 사용 가능한 VRAM으로 최적의 균형을 찾을 수 있습니다.
I2V 권장 단일 스테이지 방법:
연한 파란색(I2V) 해상도를 선택하세요. 해상도가 중요하며, 그렇지 않으면 아티팩트와 색상 번짐이 발생합니다.
컨트롤 패널에서 1b, 2, 4, 5를 활성화하세요. (3은 건너뜁니다.)
워크플로우의 I2V 섹션에서 단계를 25 이상으로 설정하세요.
입력 비디오의 확장 해상도를 사용할 수 있는 옵션이 있지만, 종종 실패하므로 옵션으로 남겨두었습니다.
스테이지 1 - 선택한 단계와 해상도로 1패스 전체 렌더링을 수행합니다.
일시 정지하여 업스케일러로 계속할지, 아니면 취소하고 다시 시도할지 결정합니다.
업스케일링 - 중간 렌더링 결과를 사용하여 해상도를 두 배로 증가시킵니다.
보간 - 프레임 레이트를 두 배로 증가시킵니다.
비디오 확장:
연한 파란색(I2V) 해상도를 선택하세요.
컨트롤 패널에서 1d, 2, 4, 5를 활성화하세요. (3은 건너뜁니다.)
이 시점에서 저해상도 또는 중간 해상도의 입력 소스를 사용하는 것이 매우 중요합니다. 그렇지 않으면 메모리가 부족해집니다.
T2V 2스테이지 방법의 중간 렌더링 결과를 사용하거나, 수동으로 저~중간 해상도로 비디오를 설정하세요. 또는 원본 비디오 해상도를 사용할 수도 있습니다. T2V 2스테이지 방법의 중간 소스나 렌더링을 사용하면 완벽히 작동합니다. 이 기능은 이를 위해 설계되었습니다.
확장된 부분만 렌더링할지, 전체 결합된 비디오를 렌더링할지 선택하세요. 전체 결합 비디오를 원한다면 True를 선택하세요. 그러면 전체 결합된 비디오가 다음 단계인 업스케일러로 전달됩니다. 따라서 중간 수준의 비디오를 사용하는 것이 중요합니다. 이는 다시 업스케일링하고 보간하기 때문입니다.
스테이지 1 - 선택한 단계와 해상도로 1패스 전체 렌더링을 수행합니다.
일시 정지하여 업스케일러로 계속할지, 아니면 취소하고 다시 시도할지 결정합니다.
업스케일링 - 중간 렌더링 결과를 사용하여 해상도를 두 배로 증가시킵니다.
보간 - 프레임 레이트를 두 배로 증가시킵니다.
모든 토글 및 스위치:
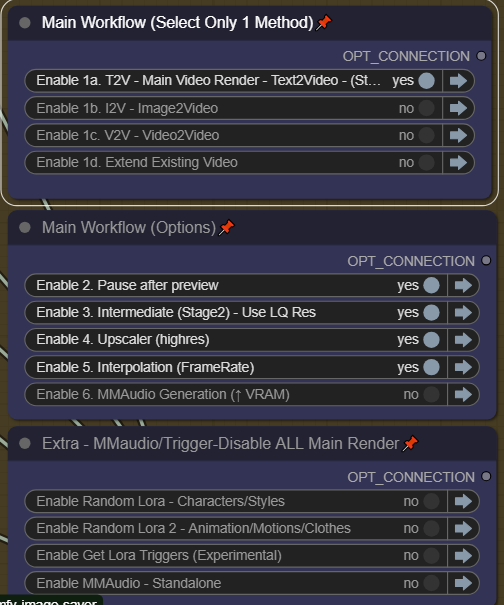 Step 1에서 단 하나의 방법만 선택하세요.
Step 1에서 단 하나의 방법만 선택하세요.
* 이는 기본 설정입니다.
이 워크플로우에서는 어떤 노드도 재연결할 필요가 없습니다. 워크플로우 내부에 자세한 지침과 설명이 포함되어 있습니다.
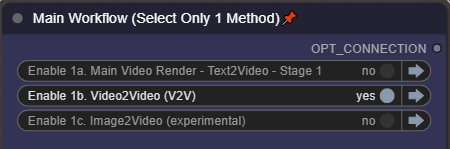
V2V - 비디오에서 비디오로:
컨트롤 패널에서 활성화하세요:
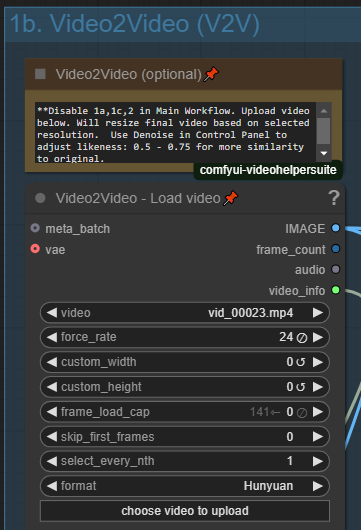 비디오를 입력 또는 비디오 가이드로 사용할 수 있습니다. 컨트롤 패널에서 이 옵션을 활성화하고 소스 입력 비디오를 업로드하세요. 이는 출력 해상도로 선택된 해상도를 사용함을 유의하세요.
비디오를 입력 또는 비디오 가이드로 사용할 수 있습니다. 컨트롤 패널에서 이 옵션을 활성화하고 소스 입력 비디오를 업로드하세요. 이는 출력 해상도로 선택된 해상도를 사용함을 유의하세요.
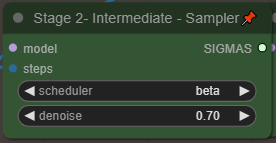 입력 비디오와의 유사도를 조정하려면 컨트롤 패널의 Denoise를 조정하세요. 낮은 값(0.5 - 0.75)은 입력 비디오와 더 유사한 결과를 제공하며, 높은 값은 더 창의적인 결과를 생성합니다.
입력 비디오와의 유사도를 조정하려면 컨트롤 패널의 Denoise를 조정하세요. 낮은 값(0.5 - 0.75)은 입력 비디오와 더 유사한 결과를 제공하며, 높은 값은 더 창의적인 결과를 생성합니다.
I2V - 이미지에서 비디오로
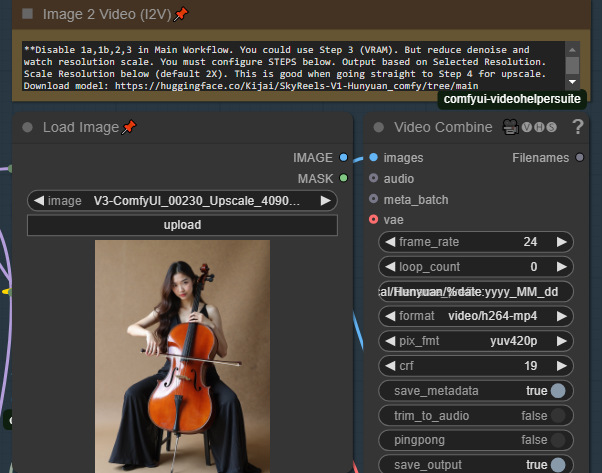 이미지를 로드하려면 "이미지 로드"를 사용하세요. 이미지는 플러그인이 손상되지 않도록 적절히 크기 조정됩니다. 출력 해상도는 해상도 선택기에서 선택한 해상도를 사용합니다.
이미지를 로드하려면 "이미지 로드"를 사용하세요. 이미지는 플러그인이 손상되지 않도록 적절히 크기 조정됩니다. 출력 해상도는 해상도 선택기에서 선택한 해상도를 사용합니다.
해상도 선택 옵션이 두 가지입니다. 원본 해상도를 사용하려면 "Orig IMG Resolution" 슬라이더를 1로 설정하세요. 하지만 이는 자르지 않고 비율만 유지합니다. 다음 옵션은 기본 스케일(기본값 384)입니다. 비디오 엔진의 제한으로 인해 원본 해상도로 매우 고해상도 사진을 렌더링하면 빠르게 메모리가 부족해집니다. 이는 기본 스케일을 기반으로 렌더링 크기를 조정합니다. 384-500에서 시작하여 VRAM이 감당 가능한지 확인하세요. 특히 원본 이미지가 매우 고해상도인 경우. 저해상도 사진으로 시작하면 슬라이더를 상당히 올릴 수 있습니다.

I2V 방법 1: 업스케일/보간/오디오를 위한 단일 패스
이 방법을 사용하는 주된 방법은 메인 워크플로우에서 1a, 1b, 3을 비활성화하고 이미지를 입력으로 사용하는 것입니다. 단계를 높게 설정한 후 업스케일러 또는 보간기에 전달하세요.
** I2V는 해상도에 매우 민감하므로 해상도 선택기에서 I2V라고 표시된 해상도(연한 파랑)를 사용하세요. 번쩍임, 아티팩트, 색상 문제가 발생하면 해당 해상도는 I2V에 지원되지 않는 것입니다.
I2V 방법 2: 업스케일/보간/오디오를 위한 2패스 - (테스트 미완료)
LQ 보라색 해상도를 선택하세요. 스테이지 1 단계를 14, 스테이지 2 단계를 25로 설정하세요. 이는 이미지를 미리보기 렌더링으로 사용하여 원하는 결과인지 확인한 후, 두 배 해상도로 전체 버전을 렌더링합니다. 이 방법은 T2V에는 잘 작동하지만, I2V는 여전히 테스트 중입니다.
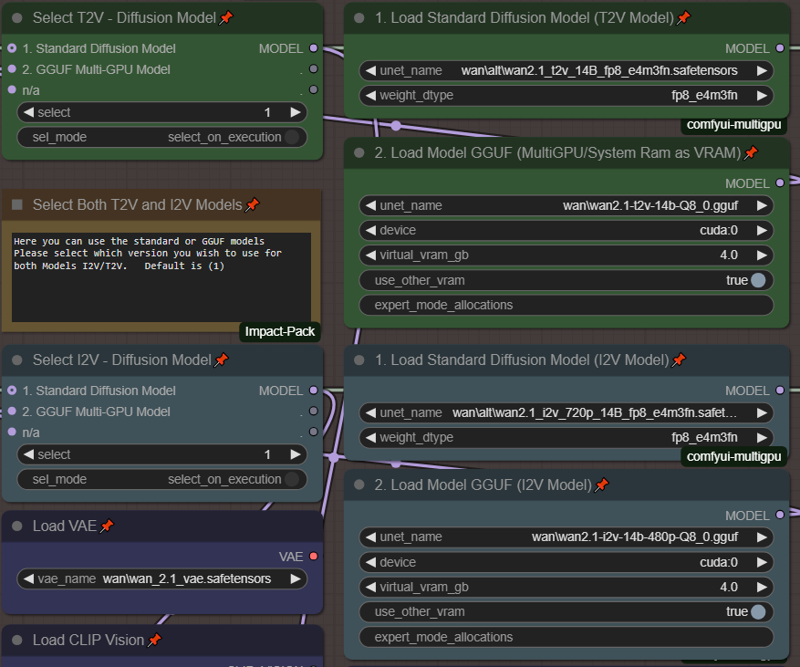
모델 선택 (저VRAM 옵션):
모델을 다음과 같이 설정하세요.
기본적으로 모든 모델은 모델 1(표준 Diffusion 모델)을 사용합니다. GGUF를 사용하려면 모델 2를 선택하세요. 표준 모델이나 GGUF 중 아무것도 사용하지 않으려면, 마우스 오른쪽 버튼으로 해당 상자를 우회하세요.
GGUF 모델을 사용하는 경우 "virtual_vram_gb"를 숫자로 설정하세요(예: "4.0") 이는 시스템 RAM을 VRAM으로 사용하여 일부 OOM 오류를 방지합니다. 위에서 사용할 가상 VRAM의 양을 설정할 수 있습니다. 시스템 RAM을 사용할 때는 렌더링 시간이 훨씬 길어지지만, 적어도 생산이 중단되지는 않습니다.
모델은 다음에서 다운로드하세요:
https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files
LoRA 옵션:
전통적인 LoRA와 더블 블록 모두 사용 가능하며, 기본값은 더블 블록입니다.
더블 블록은 여러 LoRA를 결합할 때 가중치 조정을 신경 쓰지 않고도 더 잘 작동합니다.
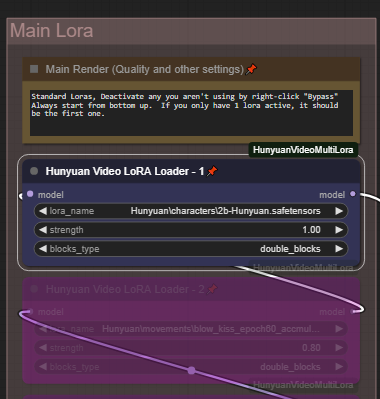 주 LoRA 스택은 표준 덧셈 LoRA 트리입니다. 최대 5개의 서로 다른 LoRA를 추가하거나 결합할 수 있으며, 사용하는 LoRA에 따라 all, single_blocks, double_blocks를 설정하세요. 이 LoRA를 랜덤 LoRA와 함께 실행할 수 있습니다. 주 LoRA 섹션에 스타일을 추가하고, 랜덤 캐릭터 LoRA와 랜덤 캐릭터 애니메이션을 추가하세요.
주 LoRA 스택은 표준 덧셈 LoRA 트리입니다. 최대 5개의 서로 다른 LoRA를 추가하거나 결합할 수 있으며, 사용하는 LoRA에 따라 all, single_blocks, double_blocks를 설정하세요. 이 LoRA를 랜덤 LoRA와 함께 실행할 수 있습니다. 주 LoRA 섹션에 스타일을 추가하고, 랜덤 캐릭터 LoRA와 랜덤 캐릭터 애니메이션을 추가하세요.
오른쪽 클릭하여 "무시"를 선택하여 LoRA를 사용/비활성화하세요.
해상도 옵션:
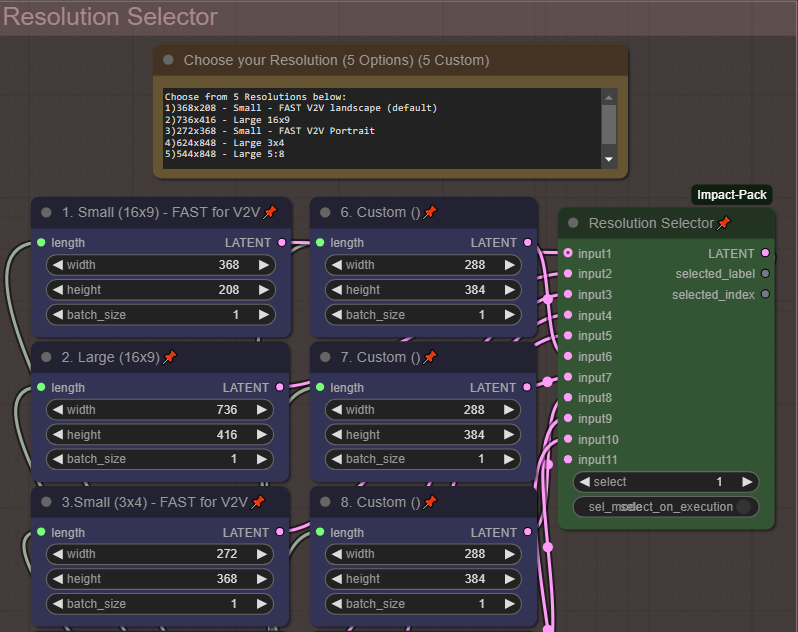 5가지 일반 해상도 중에서 선택하거나, 추가로 5가지 사용자 정의 해상도를 편집하여 맞춤 설정할 수 있습니다. "해상도 선택기"를 사용하여 해상도를 변경하세요. 기본적으로 가장 빠르고 작은 해상도가 선택되며, 이는 워크플로우의 다음 V2V 부분에 적합하도록 설계되었습니다. 해상도를 더 크게 늘릴수록 렌더링 시간이 훨씬 길어집니다.
5가지 일반 해상도 중에서 선택하거나, 추가로 5가지 사용자 정의 해상도를 편집하여 맞춤 설정할 수 있습니다. "해상도 선택기"를 사용하여 해상도를 변경하세요. 기본적으로 가장 빠르고 작은 해상도가 선택되며, 이는 워크플로우의 다음 V2V 부분에 적합하도록 설계되었습니다. 해상도를 더 크게 늘릴수록 렌더링 시간이 훨씬 길어집니다.
미리보기 후 일시 중지 - (기본적으로 활성화됨)
비디오 생성에 너무 오래 걸리며, 여러 LoRA를 실험하거나 프롬프트를 완성하는 데 비디오 렌더링 시간이 느리면 시간이 많이 소요됩니다. 이 기능을 사용하면 업스케일 프로세스에 추가 시간을 들이기 전에 비디오를 빠르게 미리 볼 수 있습니다. 기본적으로 이 기능은 활성화되어 있습니다. 워크플로우를 시작하면 빠른 미리보기가 빠르게 렌더링되고 나서 경고음이 울립니다. 다음 단계를 확인하려면 비디오 미리보기 옆의 중간 섹션으로 스크롤하세요.
좋은 미리보기를 업스케일하거나, 취소하고 다시 시도하세요!
전체 렌더링/워크플로우 계속 - 아무 이미지나 선택하고 "선택한 이미지 진행"을 클릭하세요 (어떤 이미지여도 상관없습니다).
취소 - "현재 실행 취소"를 클릭한 후 다른 미리보기를 대기열에 추가하세요.
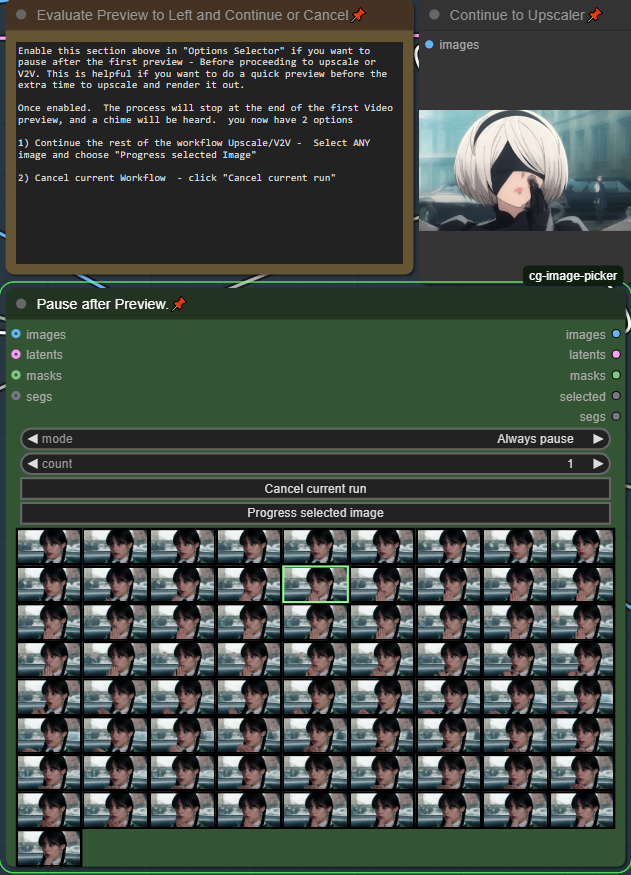 이 기능을 비활성화하려면 "옵션 선택기"에서 끄세요.
이 기능을 비활성화하려면 "옵션 선택기"에서 끄세요.

MMaudio - 비디오에 자동으로 오디오 추가
기본적으로 업스케일된 비디오에만 오디오를 추가합니다. 그러나 렌더링 프로세스의 모든 부분에 오디오를 활성화할 수 있는 전환 기능이 있습니다. 더 나은 생성을 위해 프롬프트에 오디오 세부 정보를 추가하세요.
** 참고: MMaudio는 추가 VRAM을 사용하므로 MMaudio를 사용할 때는 비디오 길이와 품질을 조정해야 합니다. v5.2에는 별도 플러그인이 제공되며, 주 워크플로우에서 비디오를 최종화한 후 오디오를 추가할 수 있습니다. 이를 통해 VRAM에 맞춰 품질과 비디오 길이를 극대화한 후, 후처리 단계에서 추가로 오디오를 추가할 수 있습니다. 별도 플러그인을 사용하면 비디오에 완벽한 오디오를 얻기 위해 여러 번 생성할 수 있는 추가 유연성을 제공합니다.
업스케일 후 보간
이 옵션은 렌더링된 비디오의 프레임 속도를 두 배로 증가시킵니다. 기본적으로 "활성화"되어 있습니다.
"옵션 선택기"에서 비활성화할 수 있습니다. 필요하지 않다면 렌더링 속도가 느려질 수 있습니다.

속도가 필요합니다!
작업이 너무 느리신가요? 더 빠른 속도를 위해 teacache를 활성화할 수 있습니다. 이 기능은 여전히 실험적입니다. "모델 로드"에서 켜고 끌 수 있습니다.
T2V - 텍스트에서 비디오로 - 프롬프트 및 와일드카드
녹색 "프롬프트 입력" 노드에 프롬프트를 입력하세요. *** 프롬프트에 줄바꿈이나 새 줄이 포함되지 않도록 해주세요. 그렇지 않으면 시스템이 워크플로우를 처리하는 방식이 변경됩니다.
와일드카드를 사용하면 프롬프트를 자동으로 변경하거나 밤새 생성을 다양하게 수행할 수 있습니다. 와일드카드를 만들려면 /custom_nodes/ComfyUI-Easy-Use/wildcards 폴더에 .txt 파일을 생성하세요. 각 줄에 하나의 와일드카드를 입력하고, 엔터를 눌러 각 와일드카드를 구분하세요. 단어나 문구를 사용할 수 있으며, "엔터"로만 구분하면 됩니다. 두 칸 띄우지 마세요. 아래는 와일드카드 파일의 두 가지 예시입니다.
color.txt
red
blue
green
locations.txt
아름다운 푸른 숲, 햇빛이 나무 사이를 비추며 조명을 퍼뜨려 미세한 신성한 빛줄기가 생기고, 배경에 나뭇잎이 스치는 소리가 들린다
야간 도시 풍경, 비가 내리고 있으며, 가까운 지붕 위로 빗방울이 떨어지는 소리가 들린다
숲 속의 환한 공간, 바위 절벽 끝에 작은 아름다운 폭포가 있고, 작은 연못과 녹색 나무들이 있으며, 폭포 소리가 멀리서 들리고, 배경에 새들이 지저귐을 울린다
프롬프트에서 이 와일드카드를 사용하려면 "와일드카드 추가 선택"을 클릭하고 프롬프트의 적절한 위치에 추가하세요.

ellapurn3ll은 __color__ 재킷을 입고 있으며, __locations__에 있습니다.
이 커스텀 노드에 대한 전체 세부 정보는 다음 링크에서 확인할 수 있습니다: https://github.com/ltdrdata/ComfyUI-extension-tutorials/blob/Main/ComfyUI-Impact-Pack/tutorial/ImpactWildcard.md
랜덤 LoRA 및 트리거
와일드카드와 랜덤 LoRA를 함께 사용하여 밤새 생성을 향상시킬 수 있습니다.
최대 12개의 랜덤 LoRA를 선택하여 조합할 수 있습니다. 기본적으로 처음 5개만 활성화되어 있습니다. 적절한 설정에서 "최대값"을 변경하여 구성한 LoRA 수를 설정하세요. 항상 위에서 아래로 순서대로 계산됩니다. 따라서 3개의 LoRA만 랜덤화하려면 "최대값"을 3으로 설정하고, 상위 3개 LoRA의 정보를 입력하세요.
** 매우 중요: 트리거 단어가 자동으로 채워지려면 프롬프트 필드에 다음 텍스트를 포함해야 합니다:
(LORA-TRIGGER) 또는 (LORA-TRIGGER2). 랜덤 LoRA로 생성할 때 자동으로 값이 채워집니다. 대소문자를 구분하므로 주의하세요.
전체 프롬프트, 단일 트리거, 또는 트리거 문구를 모두 입력할 수 있으며, 자동으로 채워집니다.
이 기능에 와일드카드를 추가하려면 {} 대괄호와 | 구분자를 사용하세요. 예: 그녀는 {빨간|초록|파란} 모자를 쓰고 있습니다. 또는 전체 프롬프트도 가능합니다: {그녀는 타임스퀘어에서 키스를 날리고 있습니다|그녀는 공원에서 키스를 날리고 있습니다}
** 이 LoRA가 작동하지 않는 경우, 블록 유형을 "모두"로 설정했는지 확인하세요.
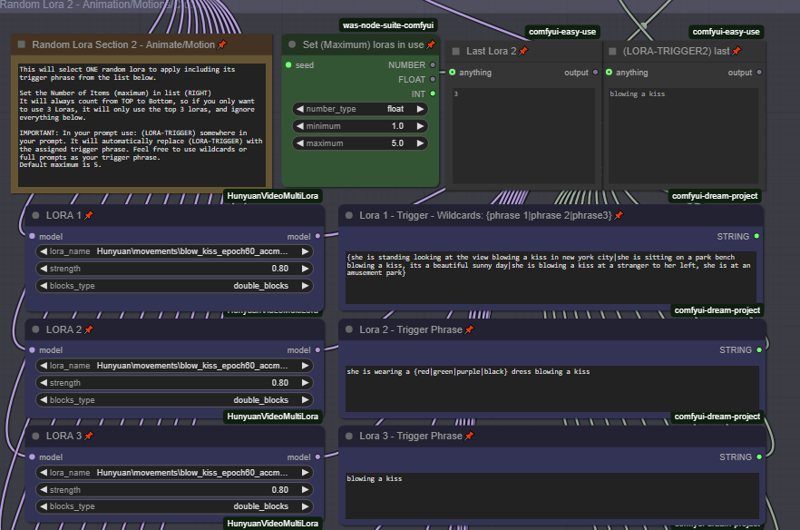 랜덤 LoRA 스택 2에서만 헬퍼 LoRA 사용 가능.
랜덤 LoRA 스택 2에서만 헬퍼 LoRA 사용 가능.
헬퍼 LoRA가 이제 제공됩니다. 일부 LoRA는 모션 또는 스타일 LoRA를 추가하면 더 나은 결과를 얻을 수 있습니다. 헬퍼 LoRA를 활성화하면 2번째 랜덤 스택에만 적용되며, 랜덤화 과정에서 해당 LoRA 번호가 선택되었을 때만 작동합니다. 예를 들어, LoRA 1이 모션 또는 스타일 LoRA와 함께 사용할 때 더 나은 결과를 얻는다면, LoRA 1 헬퍼를 활성화하고, 랜덤화 과정에서 LoRA 1이 선택되면 두 LoRA(기본 및 헬퍼) 모두 적용됩니다.
 이 기능은 주로 고급 기능이지만 일부 사용자에게 유용할 수 있습니다.
이 기능은 주로 고급 기능이지만 일부 사용자에게 유용할 수 있습니다.
"프롬프트 저장기"로 좋아하는 프롬프트를 로드하고 저장하세요 (*** 단기적으로 비호환성으로 인해 기능 제거됨***)
 워크플로우를 실행하면 프롬프트 저장기 자동으로 최신 프롬프트가 채워집니다. 나중에 사용하기 위해 저장할 수 있습니다. 프롬프트를 로드하고 사용하려면 이전에 저장한 프롬프트를 선택하고 "저장된 프롬프트 로드"를 클릭하세요. 그러나 로드한 프롬프트를 사용하려면 반드시 "입력 사용"을 "프롬프트 사용"으로 전환해야 합니다. 일반적인 프롬프트 사용으로 돌아갈 때는 다시 "입력 사용"으로 전환하는 것을 잊지 마세요.
워크플로우를 실행하면 프롬프트 저장기 자동으로 최신 프롬프트가 채워집니다. 나중에 사용하기 위해 저장할 수 있습니다. 프롬프트를 로드하고 사용하려면 이전에 저장한 프롬프트를 선택하고 "저장된 프롬프트 로드"를 클릭하세요. 그러나 로드한 프롬프트를 사용하려면 반드시 "입력 사용"을 "프롬프트 사용"으로 전환해야 합니다. 일반적인 프롬프트 사용으로 돌아갈 때는 다시 "입력 사용"으로 전환하는 것을 잊지 마세요.

**기본값은 "입력 사용"입니다. 이는 프롬프트가 일반 입력 와일드카드 필드에서 생성되며, 프롬프트 저장기에는 단순히 프롬프트 데이터가 표시됩니다.
한 개의 시드로 모든 것을 제어하세요:
하나의 시드가 모든 LoRA 랜덤화, 와일드카드 및 생성을 처리합니다. 랜덤 LoRA와 와일드카드를 사용하여 동일한 세트로 좋아하는 시드를 복사하고 재사용하세요.
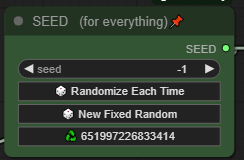 * 팁: 재활용 버튼을 클릭하여 마지막 시드를 재사용하세요. 방금 생성한 비디오를 미세 조정하거나 수정하고 싶으신가요? 2단계에서 OOM 오류가 발생했나요? 마지막 시드를 사용하고 조정한 후 다시 시도하세요!
* 팁: 재활용 버튼을 클릭하여 마지막 시드를 재사용하세요. 방금 생성한 비디오를 미세 조정하거나 수정하고 싶으신가요? 2단계에서 OOM 오류가 발생했나요? 마지막 시드를 사용하고 조정한 후 다시 시도하세요!
별도 MM-Audio:
품질과 비디오 길이를 극대화하려면 주 워크플로우에서 MM-Audio를 비활성화한 후 후처리 단계에서 오디오를 추가하세요. 이 플러그인은 나중에 오디오를 추가하기 위한 별도 실행용입니다.
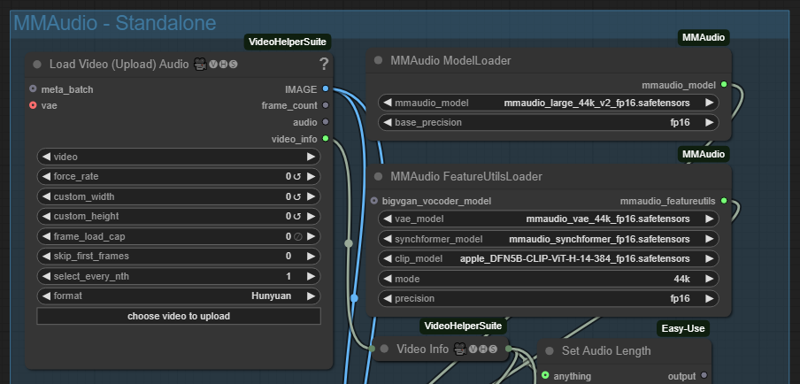 MMaudio - 별도 활성화 및 워크플로우의 다른 모든 부분을 비활성화하세요.
MMaudio - 별도 활성화 및 워크플로우의 다른 모든 부분을 비활성화하세요.
오디오를 추가할 비디오를 업로드하기만 하면 됩니다. 모든 계산은 자동으로 처리됩니다. 빈/공백 프롬프트를 사용하는 것이 좋지만, 이전에 저장한 프롬프트를 로드하려면 프롬프트 저장기를 사용하실 수 있습니다.
(선택 사항) 오디오 또는 사운드와 관련된 장면을 설명하는 프롬프트를 강화할 수 있습니다.
원하는 만큼 여러 번 생성하여 완벽한 사운드를 얻으세요!
별도 업스케일러 및 보간:
기존 비디오 파일만 업스케일링하거나 보간하고 싶으신가요? 파일을 업로드하고, 업스케일러와 보간 외 모든 워크플로우 부분을 비활성화하세요.
업로드 박스는 해당 위치에서 활성화되어야 합니다.
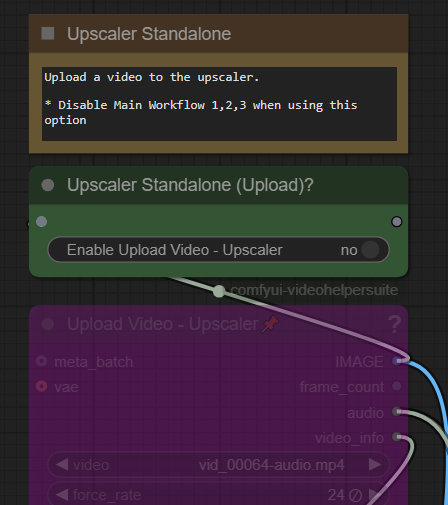 이 기능을 사용하려면 "예"로 전환하세요. 일반 워크플로우를 사용할 때는 이 설정을 다시 끄는 것을 잊지 마세요. 기본적으로 둘 다 비활성화되어야 합니다.
이 기능을 사용하려면 "예"로 전환하세요. 일반 워크플로우를 사용할 때는 이 설정을 다시 끄는 것을 잊지 마세요. 기본적으로 둘 다 비활성화되어야 합니다.
워크플로우 사용 팁
생성 품질 향상
단계 수를 늘리세요:
기본 방법 1a/b의 제어판(설정)에서 단계를 20에서 35 이상(최대 50)으로 증가시키세요. 각 단계는 더 많은 시간과 메모리를 소요하므로 해상도와 단계 사이의 균형을 찾으세요.
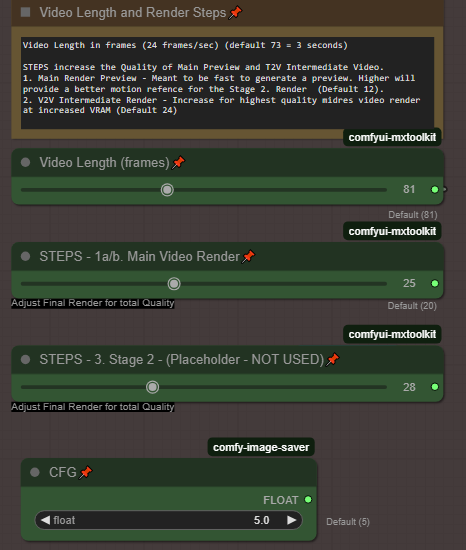
더 높은 해상도를 시도하세요:
해상도를 큰 높은 해상도 중 하나로 변경하세요.
** 추가 테스트가 이루어지면 더 많은 해상도 팁을 제공할 예정입니다.
완벽한 비디오를 위해 비디오 길이와 품질을 균형 있게 조정하세요
여기에는 비디오 길이와 품질의 균형을 맞추는 데 사용한 몇 가지 설정이 있습니다. 3090 24GB VRAM에서 테스트되었습니다.
문제 해결:
5090/5080/5070 50xx 시리즈 NVIDIA GPU 해결 방법
50xx NVIDIA GPU는 여전히 개발 중입니다. 다음은 Python 3.12.X와 함께 제공되는 표준 ComfyUI 포터블 버전을 사용하는 데 도움이 되는 몇 가지 팁입니다.
최근에 GPU를 NVIDIA 50xx로 업그레이드했고, 모든 기능이 작동하지 않는다고 느끼시나요?!
다음은 비디오 길이와 품질의 균형을 맞추는 데 사용한 설정입니다. 3090 24GB VRAM에서 테스트되었습니다.
표준 ComfyUI 포터블 버전을 다운로드하거나 기존 폴더를 사용하세요.
Cuda 12.8 설치
(Torch 2.7 dev 설치)
python_embedded 폴더로 이동하세요
python.exe -s -m pip install --force-reinstall torch==2.7.0.dev20250307+cu128 torchvision==0.22.0.dev20250308+cu128 torchaudio==2.6.0.dev20250308+cu128 --index-url https://download.pytorch.org/whl/nightly/cu128 --extra-index-url https://download.pytorch.org/whl/nightly/cu128
또는 최신 버전을 얻으려면 다음 명령을 사용할 수 있습니다.
Python.exe -m pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu128
(Triton 3.3 프리릴리즈)
python.exe -m pip install -U --pre triton-windows
python.exe -m pip install sageattention==1.0.6
(Sage Attention)
SET CUDA_HOME=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8
cd sageattention
..\python.exe setup.py install
위의 방법이 작동하지 않는 경우, 이 기사로 이동하여 setup.py를 다음 링크의 코드로 교체하세요. https://github.com/thu-ml/SageAttention/issues/107
이제 정상적으로 실행할 수 있어야 합니다. 일부 이전에 작동하던 노드가 이유를 알 수 없이 작동하지 않는 경우가 있습니다. 곧 5090, 5080, 5070 시리즈 카드를 위한 수정 사항을 두 워크플로우에 모두 반영할 예정입니다.
** 이 부분에 대해 전문가가 아니므로 문제 해결을 도와드릴 수 없습니다. Sage와 Triton이 정상 설치되었음에도 여전히 ComfyUI와 호환되지 않는 문제가 있습니다. 50xx 카드에 대한 더 많은 개발자가 접근할수록 곧 버그가 해결될 것입니다.
누락된 노드:
MMaudio - 오디오 노드가 로드되지 않는 경우, ComfyUI Manager로 이동하여 다음 주소로 "Git URL을 통한 설치"를 수행하세요: https://github.com/kijai/ComfyUI-MMAudio
그 후 재시작하세요.
보안 오류가 발생하면, 다음 경로로 이동하세요: ComfyUI/user/default/ComfyUI-Manager에서 config.ini 파일을 찾아 Notepad로 열고 "security_level = normal"을 찾아 "security_level = weak"로 변경하세요. 그런 다음 설치를 시도하세요. 설치가 완료되면 이 설정을 다시 normal로 되돌릴 수 있습니다. 추가적인 MMaudio 정보는 해당 GitHub 페이지에서 확인할 수 있습니다.
ReActor 또는 얼굴 향상 노드가 누락된 경우:
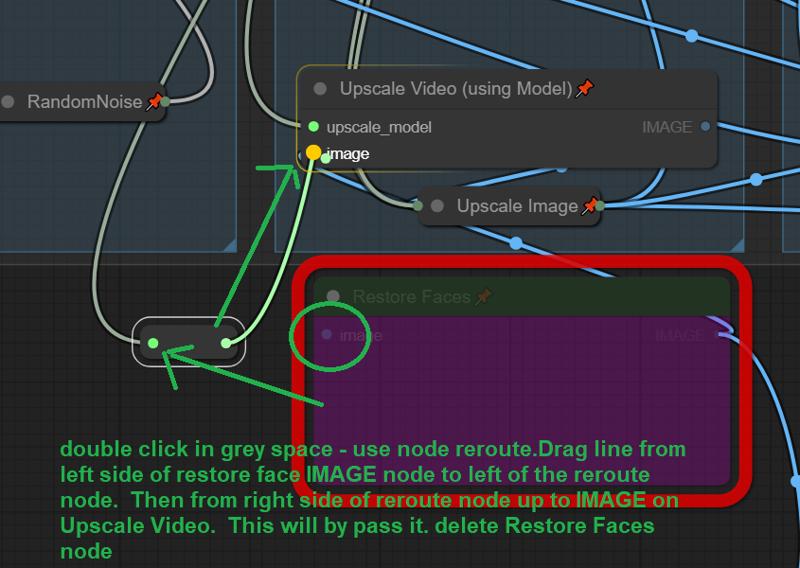
Re-Actor 노드에 문제가 있다면 쉽게 제거할 수 있습니다. 이론적으로 이 노드는 기본적으로 우회되기 때문에, 없어도 워크플로우가 작동해야 합니다.
RED 얼굴 복원 상자로 이동하여 회색 영역 어디든 더블 클릭하고, "reroute"를 검색하여 노드를 추가하세요.
얼굴 복원의 왼쪽 입력 선을 새 노드의 왼쪽으로 끌어다 놓으세요.
reroute 노드의 오른쪽에서 "Upscale Video"의 이미지 입력으로 새 선을 끌어다 놓으세요. 그런 다음 얼굴 복원 노드를 완전히 삭제할 수 있습니다.
이상입니다. 이 모든 것의 원저작자들께 감사의 뜻을 전합니다.
즐겁게 사용하시길 바랍니다. 이렇게 개방적이고 공유하는 커뮤니티에 참여하게 되어 정말 기쁩니다!
자신의 생성물과 이 워크플로우에 사용한 설정을 자유롭게 공유해 주세요.