WAN Video YAW Workflow 1.6 V2V T2V I2V, upscale, extend, audio, interpolate, random-lora, preview pause, upscale, multi-res, interpolate,prompt save/load

详情
下载文件 (1)
关于此版本
模型描述
Beta 1.6 - New Experimental Quality/Options. Skip Guidance (quality), CFGZeroSTar(prompt adherance), Enhance-A-Video(quality). Re-Actor (Face restore) added back in. If you have problems, leave it disabled, workflow will still work, disable using instructions at bottom of page.
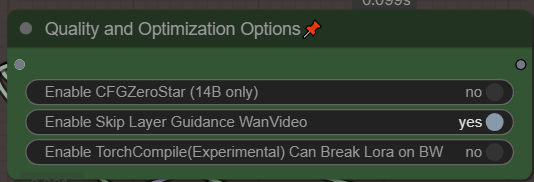
**Torch Compile can break Loras, noticed it on newest torch and blackwell nvidia.
Beta 1.5 - Faster, Many QOL and bugfiles, additional tested resolutions, Nvidia Blackwell 50XX compatible Nodes.
** 5090/5080/5070 50xx series Nvidia GPU fixes in the troubleshooting section.
This is a WAN Video workflow, based on my Hunyuan YAW (Yet another workflow). Its preliminary but works. As WAN development continues, i hope to bring features to parity with the hunyuan equivalent. BETA 1.2 Added V2V, GGUF multi-gpu use system ram as VRAM. More tested resolutions, Teacache Acceleration.
Quick observations:
I noticed that increase steps can increase quality.. and for I2V you get wierd colors and strobing when using non-standard resolutions. Please see some of the tested I2V resolutions in the resolution selector. I was able to fix the color strobing by only changing resolutions. Still working on feature parity with the original workflow.
If you get model errors, and you didn't download all models, go to the "Model Loader" and right click and "Bypass" the models you didn't download. For example if you are not using GGUF models, right click and bypass both the green and light grey #2.
*hunyuan version of the workflow is more feature complete: https://civitai.com/models/1134115/
Read full instructions below for more info.
Workflow highlights:
Audio Generation - via MMaudio - Render Audio with your videos, Stand-alone plug-in available for audio only post processing.
Pause before upscale (optional)
Preview your videos before proceeding with the full length render
Lora Randomizer - 2 stacks of 12 Loras, can be randomized and mixed and matched. Includes wildcards, triggers or prompts. Imagine random characters + random motion/styles, then add in Wildcards and you have the perfect over-night generation system.
Prompt Save/Load/History
Multiple Resolutions
Quickly Select from 6 common resolutions using a selector. Use up to 6 of your own custom resolutions.
Multiple Upscale Methods -
Standard Upscale
Interpolation (double frame-rate)
Multiple Lora Options
Double-Block (works better for multiple combined loras without worrying about weights)
Prompting with Wildcard Capabilities
All Options are toggles and switches no need to manually connect any nodes
Detailed Notes on how to set things up.
Face Restore
Text 2 Video, Image 2 Video
Tested on 3090 with 24GB VRAM
This workflow has a focus on being easy to use for beginner but flexible for advanced users.
This is my first workflow. I personally wanted options for video creations so here is my humble attempt.
Additional Details:
** Troubleshooting nodes, or comfyui manager can be found at the bottom of this document.
Quick Start Guide:
By Default- everything has been tuned for a functional workflow.
There are 2 ways to use this work flow for T2V (which is the primary focus).
#1 - Simple 1-stage render, to upscaler to interpolation.
Enable 1abc, 2,4,5 in the workflow. (skip 3)
Select one of the tested pale blue resolutions in the resolution selector (these are the advertised officially supported WAN resolutions at 480p/720p. These are larger so Stage 1 will take more time.
Set the Stage 1 steps to 25 or higher. This will do a 1-pass render
#2 - 2-Stage render (Recommended)
Enable 1abc, 2,3,4,5 in the workflow.
Select one of the Purple (LQ) resolutions in the resolution selector
Set the Stage 1 steps to 14
Set Stage 2 steps to 25
What this does is create a fast preview render letting you see if your concept and loras are working correctly. (~1 minute on 3090) This should be at a low resolution like 272x368. This allows it to go quickly. Once your quick preview is done it will pause and let you chose if you want to do the full render based on the preview. The Full render will automatically double your output resolution, This is the Stage 2. Then it will go to the upscaler which will double the resolution again, then the interpolator that will double your framerate. This was the main concept behind the hunyuan version of the workflow. Rapid prototype and render the best concepts. So looking at the numbers even a low res render starting at 272x368, goes to 544x 736 in stage 2, then 1088x1472 after upscaling.
Details of how the workflow functions.
Step 0. Setup your models, in the Load Models section, Select your resolution.. (unfortunately i haven't had time to determine a good set of support resolutions for WAN. I do know that 512x512 640x480, 1280x720 all seem to work depending on your VRAM. depending if you want landscape or portait. 16x9 in general is more versitle, 3X4 may be higher quality but limited in video length, all depending on your GPU VRAM. Start with default steps, and video length.
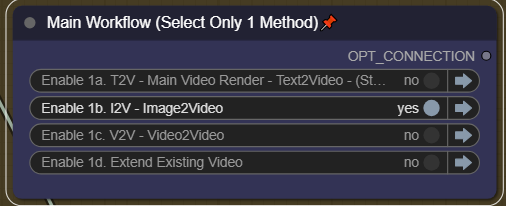
Step 1. Use 1a/1b/1c T2V or I2V
Step 2. Pause and decide based on the preview if you want to continue to the the upscaler
Step 3. uses a frame by frame upscaler that doubles the resolution again.
Step 4. Doubles the frame rate from 16 fps to 32 fps for more smoother motion.
(Optional Step) Enable MMaudio Generation - it will create audio to go along with your video, using both your text prompt and video to determine what sounds to add. Describe the sounds in the scene in your text prompt for better generation. This uses more VRAM so has been disabled by default. You can always add audio generation at the end using the Standalone MMaudio Plugin.
From here you can start to adjust things like # of steps, video length, and resolutions to find the best balance of what your available VRAM can handle.
I2V recommended method 1-stage:
Choose a Pale Blue (I2V) resolution. Resolution is important or you will get artifacts and color blotches
Enable 1b, 2, 4, 5 in the control panel (skipping 3)
Set the Steps to 25 or higher in the I2V section of the workflow.
You have the option to use a scaled resolution of the input video, this often fails but has been left in as an option
1) Stage 1 - It will do a 1-pass full render at your selected steps and selected resolution
2) It will pause and let you decide if you want to continue to the upscaler, or cancel and try again
3) Upscaling - It will now take your Intermediate render and double the resolution.
4) Interpolation - It will double your framerate.
Video Extention:
Choose a Pale Blue (I2V) resolution
Enable 1d, 2,4,5 in the control panel (skipping 3)
Its very important to use a low or mid-resolution input source at this point, or you will run out of memory.
Use an intermediate render from the T2V 2-stage or manually set a low to medium resolution for your video - you can set this manually. Alternatively you can choose to use the original video resolution. If you are using an intermediate source or the intermediate render from the T2V 2-stage method, this will work perfectly.. its designed for this.
Select if you want to just render out the extended part or the full combined video.. Select True if you want the full combined video. This will also pass the entire fully combined video to the next step the upscaler. This is why its important to use an intermediate level video, as it will upscale and interpolate again.
1) Stage 1 - It will do a 1-pass full render at your selected steps and selected resolution
2) It will pause and let you decide if you want to continue to the upscaler, or cancel and try again
3) Upscaling - It will now take your Intermediate render and double the resolution.
4) Interpolation - It will double your framerate.
All toggles and switches:
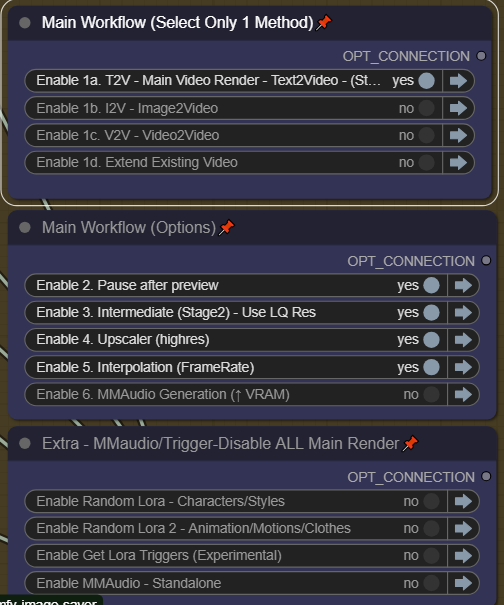 Make sure you only choose 1 Method in Step 1.
Make sure you only choose 1 Method in Step 1.
* These are the default settings.
You should never need to rewire anything in this workflow. Detailed instructions and comments right inside the workflow.
V2V - Video to Video:
Enable it on the Control Panel:
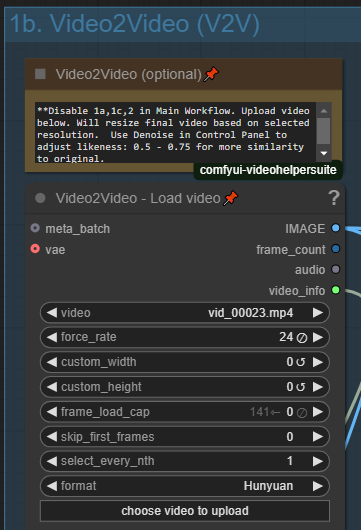 You can use video as an input or guide for your video. Enable this option in Control Panel and click to upload your source input video. Please note that this will use your selected resolution for output.
You can use video as an input or guide for your video. Enable this option in Control Panel and click to upload your source input video. Please note that this will use your selected resolution for output.
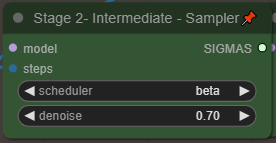 To adjust the similarity to your input video, adjust the Denoise in the main Control Panel. Lower (0.5 - 0.75) will provide closer similarity to your input video, where a higher number will get more creative.
To adjust the similarity to your input video, adjust the Denoise in the main Control Panel. Lower (0.5 - 0.75) will provide closer similarity to your input video, where a higher number will get more creative.
I2V - Image to Video
 Used Load image to load your source image. The image will be appropriately scaled as to not break this plug-in. The output resolution will use your Selected Resolution from the Resolution Selector.
Used Load image to load your source image. The image will be appropriately scaled as to not break this plug-in. The output resolution will use your Selected Resolution from the Resolution Selector.
You have 2 options for Resolution, if you want to use the source resolution simply set use Orig IMG Resolution slider to 1. However this only maintains the aspect ratio without cropping. The next option is the Base Scale (default 384) due to limitations of video engine you will quickly run out of memory trying to render very high resolution photos at native resolution. This will scale the size of your render based on the Base Scale. Start with 384-500 to start and see if your VRAM can handle it. especially if your source image is very high resolution. If you start with a low resolution photo you can increase the slider quite a bit.

I2V Method 1: One-Pass to upscale/interpolation/audio
The primary way to use this method, is to Disable 1a,1b,3 in the Main workflow, it will take your image as input. Set your steps high and then send it to the upscaler or interpolator.
** Remember that I2V is very resolution specific, try to use resolutions that say I2V in the resolution selector (Pale blue). If you get flashing or artifacts and colors, you are on an unsupported resolution for I2V
I2V Method 2: Two-Pass to upscale/interpolation/audio - (Most untested)
Select a LQ purple resolutions. Set steps Stage 1 = 14, then steps Stage 2 = 25. It should use your image as a preview render to make sure its looking the way you want it, then render a full resolution version at double the res. This works well for T2V but still testing I2V
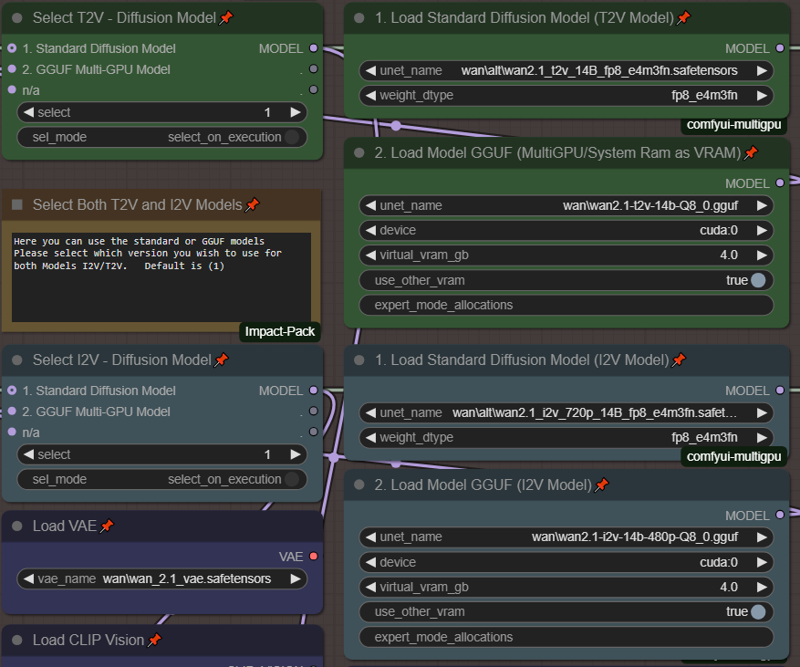
Selecting your Model (LOW VRAM options):
Please setup your models like this.
By default each Model is using model 1. Standard Diffusion Models. If you want to use GGUF select model 2. If you do not want to use either standard models or GGUF, you can right click and bypass those boxes.
If using the GGUF model, can you set "virtual_vram_gb" to a number ie. "4.0" this will allow this amount of use system ram as VRAM and hopefully prevent some of the OOM errors. You can set the amount of virtual VRAM to use above. Please note anytime you are using system ram, the render time will be much slower, but at least your production won't stop.
Get the models from:
https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files
Lora Options:
Traditional Loras and Double Block can be used, Double-Block is default.
Double-block seems to do better with multiple lora's without having to worry about adjusting weights as often.
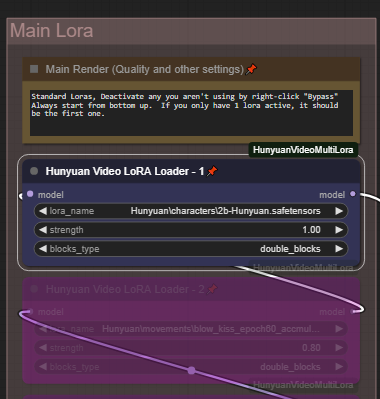 The Main Lora Stack is a standard additive Lora tree. Add or combine up to 5 different Loras, set your all, single_blocks,double_blocks according to the loras you are using. You can run these loras in addition to the random loras. Add a styles in the main lora section, then add randomized character loras, with randomized character animations.
The Main Lora Stack is a standard additive Lora tree. Add or combine up to 5 different Loras, set your all, single_blocks,double_blocks according to the loras you are using. You can run these loras in addition to the random loras. Add a styles in the main lora section, then add randomized character loras, with randomized character animations.
Enable/Disable your lora's by right-clicking and choose "Bypass"
Resolution Options:
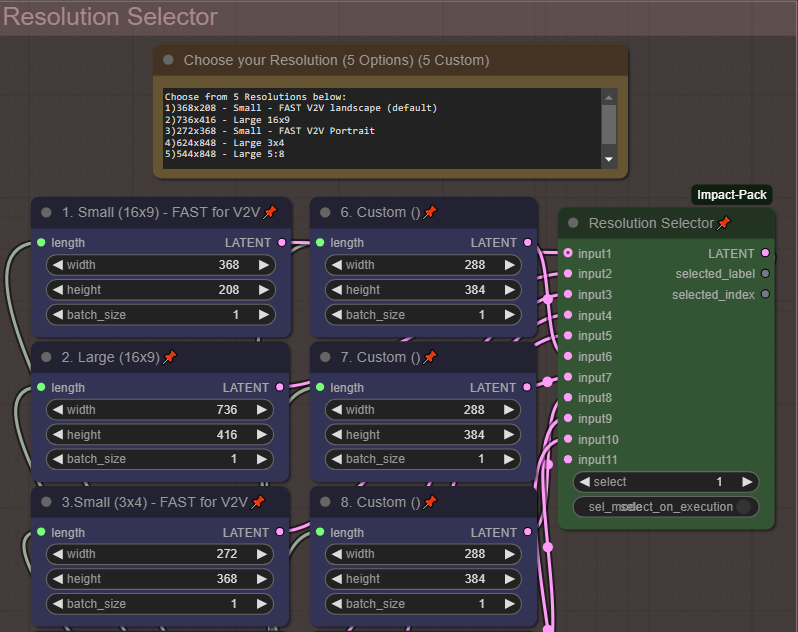 Select from 5 common resolutions - or edit an additional 5 custom resolutions to make them your own. Change resolution with the "Resolution Selector" By Default the fastest smallest resolution is selected intended to go to the next V2V portion of the workflow. As you increase to the larger resolutions your render times will take much longer.
Select from 5 common resolutions - or edit an additional 5 custom resolutions to make them your own. Change resolution with the "Resolution Selector" By Default the fastest smallest resolution is selected intended to go to the next V2V portion of the workflow. As you increase to the larger resolutions your render times will take much longer.
Pause after Preview - (On by default)
Video generation takes too long, experimenting with multiple loras or getting your prompt right takes so long when video render-times are slow. Use this to quickly preview your videos before going through the additional time to upscale process. By Default this is Enabled. After your start the workflow, it will quickly render the fast preview, then you will hear a chime. Make sure you scroll to the middle section beside the video preview for next steps.
Upscale the previews you like, or cancel and try again!
1) Continue the full render/workflow - Select ANY image (It doesn't matter which one) and click "Progress Selected Image"
2) Cancel - click "Cancel current run" then queue for another preview.
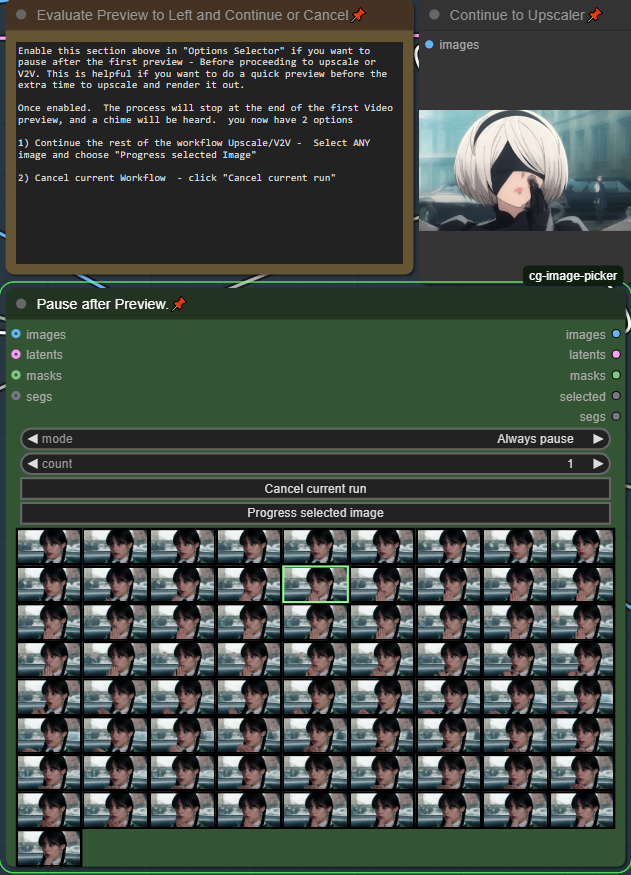 To disable this feature, toggle it off under "Options Selector"
To disable this feature, toggle it off under "Options Selector"

MMaudio - Add audio automatically to your video
By Default it will only add audio to upscaled videos. However there is a switch to enable it for all parts of the render process. Be sure to add any audio details to your prompt for better generation.
** Note MMaudio takes additional VRAM, you may need to balance video length quality when using MMaudio. A Stand-alone plugin is available in v5.2 and you can add your audio after you have finalized your video in the main workflow. This lets you maximize the quality and video length according to your vram, then simply add audio as an additonal step in post-processing. Using Standalone offers additional flexibility for you to generate multple times to get the perfect audio for your video.
Interpolation after Upscaling
This option lets you double the frame-rate of your rendered video, by default "enabled"
you an disable it from the "Options Selector". This can slow down your render if you don't need it.

I feel the need, the need for Speed
Things running too slowly? You can enable teacache for better speeds This is still experimental. Toggle it on/off under Load Models.
T2V - Text to Video - Prompting and Wildcards
Please enter your prompt int he Green "Enter Prompt" Node. *** Please ensure your prompt doesn't have any linefeeds or new lines or it will change the way the system processes the workflow.
Using Wildcards is a feature that can allow you to automatically change your prompt or do overnight generation with variances. To create wildcards. you will need to create a .txt file in the folder /custom_nodes/ComfyUI-Easy-Use/wildcards. Create a wildcard on each line. Pressing enter to separate each wildcard. You can use since words, or phrases. As long as they are separated by a "enter" Do not double space. Here are 2 example wildcard files.
color.txt
red
blue
green
locations.txt
a beautiful green forest, the sunlight shines through the trees, diffusing the lighting creating minor godrays, you can hear the sound of tree's rustle in the background
a nightime cityscape, it is raining out, you can hear the sound of rain pitter patter off of the nearby roofs
a clearing in the forest, there is a small but beautiful waterfall at the edge of a rockycliff, there is a small pond and green trees, the sound of the waterfall can be heard in the distance, birds are chirping in the background
To use these in a prompt you can click the "select to add wildcard" and add them at the appropriate spot in the prompt.

ellapurn3ll is wearing a __color__ jacket ,she is in __locations__.
Full details on this custom node can be found here: https://github.com/ltdrdata/ComfyUI-extension-tutorials/blob/Main/ComfyUI-Impact-Pack/tutorial/ImpactWildcard.md
Randomized Lora and Triggers
Turn up your overnight generations by using both wildcards and Randomized Loras.
Choose up to 12 Random Loras to mix and match. Please note by default only the first 5 are enabled. Change the Maximum in the appropriate setting to set the number of loras you have configured. It will always count from top to bottom. So if you only want to randomize between 3 loras, set the "maximum" to 3. And fill in the information for the top 3 Loras.
** Very important. In order for the trigger words to populate, you must include the text:
(LORA-TRIGGER) or (LORA-TRIGGER2) in your prompt field. It will then automatically fill in the value when generating with random loras. This is case sensitive so please becareful.
Please note you can put full prompts, single triggers, or trigger phrases, and it will be filled in automatically for you.
To add wildcards to this use {} bracets and | separator. for example. She is wearing a {red|green|blue} hat. Or you can do full prompts {she is standing in time square blowing a kiss|she is sitting in a park blowing a kiss}
** If these loras are not working, make sure you set your block types to "all"
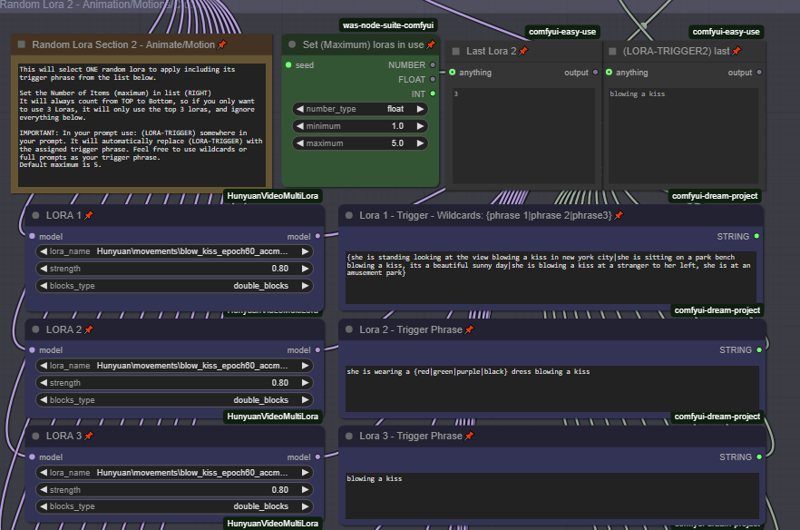 Helper Loras on Random Lora Stack 2 Only.
Helper Loras on Random Lora Stack 2 Only.
Helper lora's are now available. Often Some lora's work better with the addition of a motion or style lora. Enabling a helper lora will only take effect on the 2nd random stack, and only if that Lora # was selected in the randomization.. For example if Lora 1 works better with the addition of a motion or style lora. Enable Lora 1 Helper, and IF lora 1 is selected in the randomization process, it will apply both lora's (primary and the helper).
 This is mostly an advanced feature but some may find it useful.
This is mostly an advanced feature but some may find it useful.
Load and Save your favorite prompts with "Prompt Saver" (*** FEATURE REMOVED temporarily DUE TO INCOMPATIBILITY***)
 As you run your workflow. it will automatically populate your Prompt Saver with the latest prompt. You can then Save it for later use. Please note to Load and use a prompt.. select your previously saved prompt, and click "Load Saved". But its important you must toggle "Use Input" to say "Use Prompt" in order to use your loaded prompt. Don't forget to switch it back to "Use Input" for normal prompt use.
As you run your workflow. it will automatically populate your Prompt Saver with the latest prompt. You can then Save it for later use. Please note to Load and use a prompt.. select your previously saved prompt, and click "Load Saved". But its important you must toggle "Use Input" to say "Use Prompt" in order to use your loaded prompt. Don't forget to switch it back to "Use Input" for normal prompt use.

**Default is "Use Input" This means your prompt will be generated by the normal input wildcard prompt field, and simply show the prompt data in Prompt Saver.
One Seed to Rule them All:
One single seed handles all lora randomization, wildcards and generation. simply copy and reused your favorite seeds with the same sets using random loras and wildcards without a worry.
 * Tip clip the recycle button to re-use your last seed. Did you want to fine-tune or tweak a video you just recreated? did you get an OOM in the 2nd stage, Use the last seed, adjust and try again!
* Tip clip the recycle button to re-use your last seed. Did you want to fine-tune or tweak a video you just recreated? did you get an OOM in the 2nd stage, Use the last seed, adjust and try again!
Standalone MM-Audio:
To maximize your quality and video length you may want to disable MM-audio in the main workflow, then add the audio in later on in post-processing. This plug-in is meant to run as a stand-alone to add audio later.
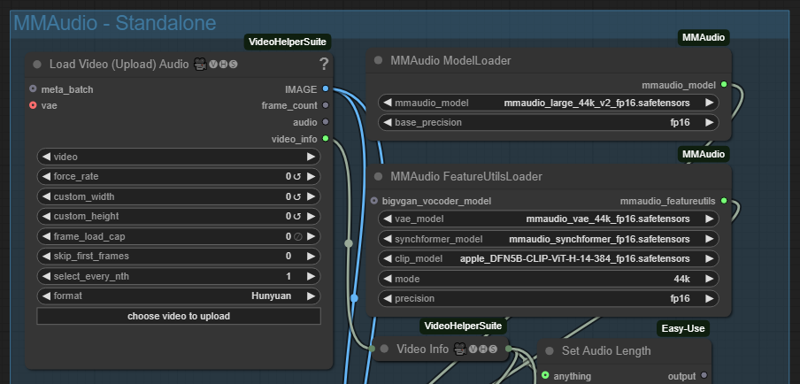 Enable MMAudio - Standalone and disable all other parts of the workflow.
Enable MMAudio - Standalone and disable all other parts of the workflow.
Simply upload the video you want to add audio to. All calulations are done for you. Its recommended to use a blank/empty prompt. But i've included the prompt saver if you want to load your previously saved prompt
(Optionally) you can can enhance your prompt focusing on describing the sounds or the scene as it relates to sound.
Generate as many times as you want until you get the sound just right!
Standalone Upscaler and Interpolation:
Want to just upscale or interpolate your existing video files? Just upload them, Disable all other parts of the workflow except upscaler and interpolation.
The upload box needs to be enabled in the appropriate place.
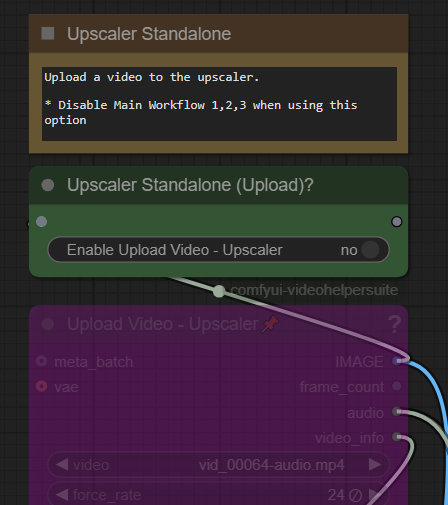 Click on Enable to "Yes" to use this feature. Don't forget to turn this off when using the regular workflows. By default these should both be disabled.
Click on Enable to "Yes" to use this feature. Don't forget to turn this off when using the regular workflows. By default these should both be disabled.
Tips for how to use the workflow
Increase the Quality of your Generations
Increase the number of steps:
For the default Method. 1a/b In the Control Panel (Settings). Increase your steps from 20 to 35 or higher (up to 50). Each step takes more time and memory so find that balance between resolution and steps.
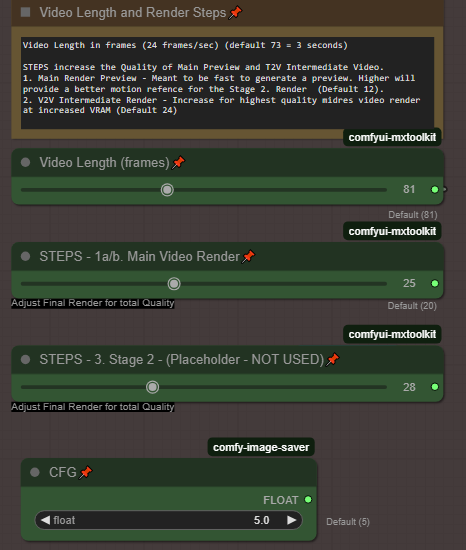
Try higher resolutions:
Change my resolution to one of the Large higher
** more resolution advice as more testing is done.
Balance your video length and quality for that perfect video
Here are a few settings i've used which strike a balance for video length and quality. Tested on 3090 24 GB Vram.
Troubleshooting:
5090/5080/5070 50xx series Nvidia GPU fixes
50xx Nvidia GPU's are still being developed. Here are a few pointers to get things going with the Standard ComfyUI portable that comes bundled with python 3.12.X
Did you just update your GPU to an Nvidia 50xx and find nothing works!?!
Here are a few settings i've used which strike a balance for video length and quality. Tested on 3090 24 GB Vram.
Download the Standard Comfyui Portable. Or use your existing folder.
Install Cuda 12.8
(Install Torch 2.7 dev)
Go to the python_embedded folder
python.exe -s -m pip install --force-reinstall torch==2.7.0.dev20250307+cu128 torchvision==0.22.0.dev20250308+cu128 torchaudio==2.6.0.dev20250308+cu128 --index-url https://download.pytorch.org/whl/nightly/cu128 --extra-index-url https://download.pytorch.org/whl/nightly/cu128
OR: you can also use this command to get the latest.
Python.exe -m pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu128
(Triton 3.3 prerelease)
python.exe -m pip install -U --pre triton-windows
python.exe -m pip install sageattention==1.0.6
(Sage Attention)
SET CUDA_HOME=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8
cd sageattention
..\python.exe setup.py install
If this doesn't work for you. Go to this article, and replace your setup.py with the code from here. https://github.com/thu-ml/SageAttention/issues/107
You should now be able run things as normal. Some previously working nodes stop working for some reason, not sure why. I will be updating both workflows shortly to include fixes for 5090 5080 5070 series cards.
** please note I'm not an expert at this, i can not help you troubleshoot this aspect... even though sage and triton install properly they still seem to have problems with comfyui. I'm sure the bugs will be worked out soon as more developers get access to 50xx cards.
Nodes missing:
MMaudio - If your audio nodes aren't loading. Please go to ComfyUI Manager, and do an "install via Git URL" with this address: https://github.com/kijai/ComfyUI-MMAudio
then restart.
If you get a security error, you will need to go to: ComfyUI/user/default/ComfyUI-Manager and look config.ini open that with notepad and look for "security_level = normal" change this to say "security_level = weak". Then try the install. Once you have installed, you can set the setting back to normal. any additional MMaudio information can be found on their github page.
ReActor or Face Enhanced Nodes Missing:
if you are having trouble with the Re-Actor node. You can easily remove it. In theory the workflow should work without it since its bypassed by default.
1) got to the RED Restore Faces box.. and double click anywhere in the grey space. search reroute and add the node.
2) Drag the input line from the left side of Restore Faces to the left side of the new node.
3) drag a new noodle from right ride side of the reroute node to the Image input of "Upscale Video" then you can just delete the restore faces node completely.
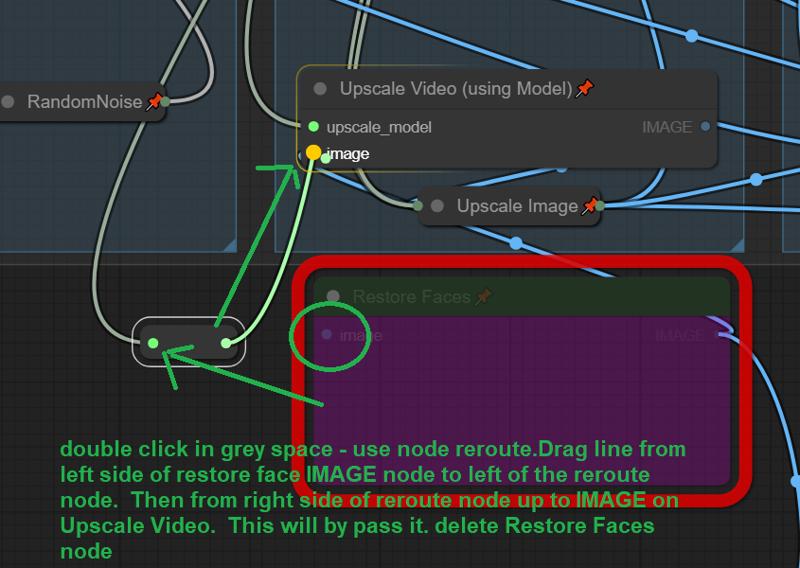
That's all folks. all credits to all of the original authors of all of this.
Hope you enjoy. Great to be part of such an open and sharing community!
Feel free to share your creations, settings with this workfow.