Hunyuan Video Workflow for High VRAM Savings
详情
下载文件 (1)
模型描述
This workflow has only been tested on WSL. You'll need Triton, Sage Attention and Bits and Bytes if you want but it doesn't affect memory. If you don't have Bits and Bytes installed, then set the TextEncoder quantization to Disabled. If you don't use Sage Attention, then the memory usage will be higher.
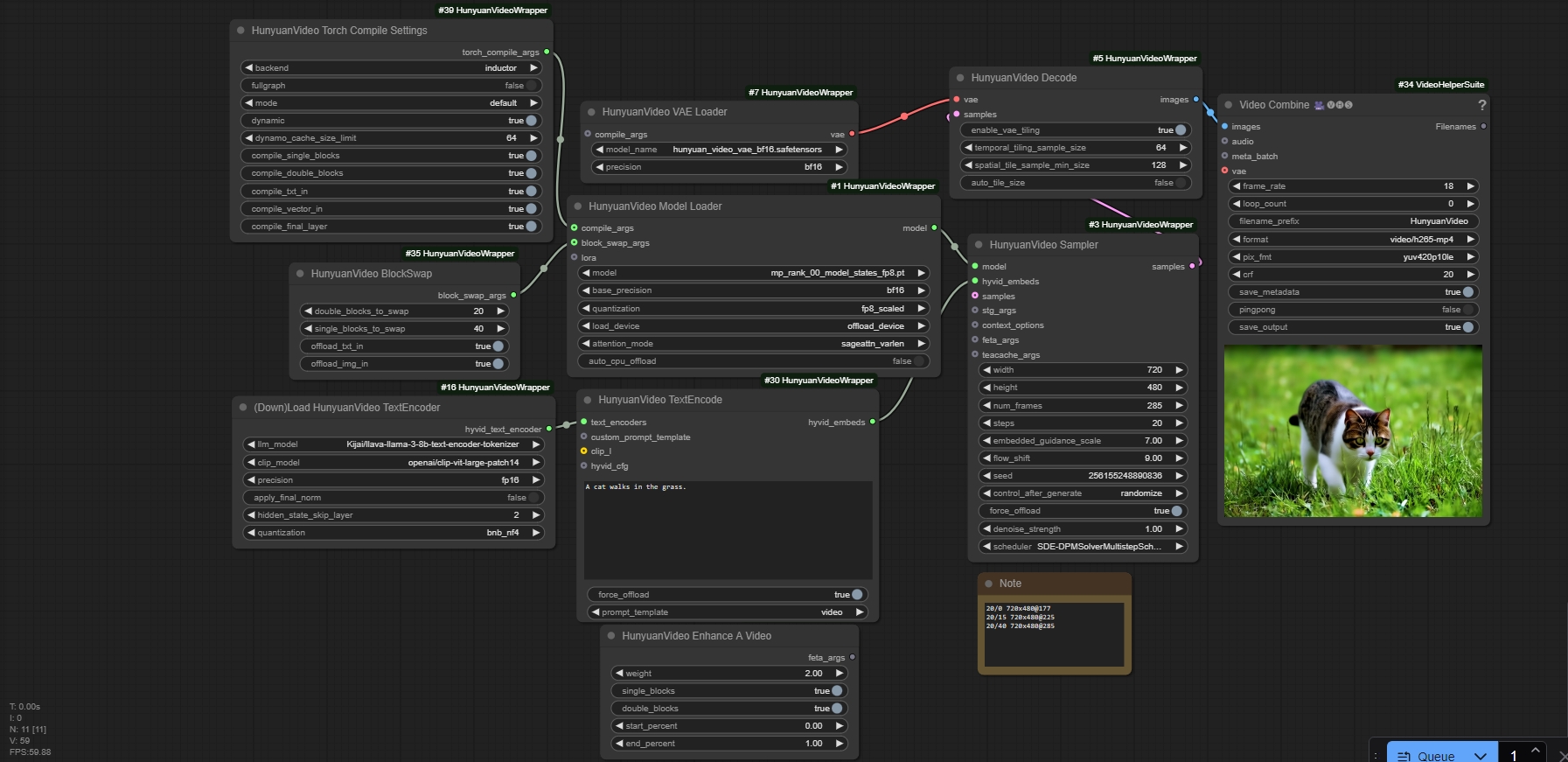
You can connect Enhance-a-Video node to feta_args, but it will slightly impact memory usage depending on the weight used. You can also connect a Lora to the model loader.
The biggest factor that will affect memory usage is the blockswap node. The higher you set this, the more memory is saved and the longer the generation time. Start with double blocks. It maxes at 20. If you need more memory savings, use single blocks which maxes at 40. I have a 4080 and I've been able to do nearly 300 frames at 720x480 which takes about 25 minutes. You can increase resolution while reducing frames. A 24+ GB card will obviously be able to do more.
The goal is to set the blockswaps as low as possible while using most of your VRAM to preserve generation speed. For example, don't set 20/40 for a 2 second video. Only increase if needing more frames or resolution and you are already near your VRAM limit. Use a memory monitor such as GPU-Z. Don't get too close to your max VRAM or it's possible it will work without a OOM error but generate a lot slower than it should. I have 16 GB which is 16384 MB. I try to keep it below 16000 MB for full speed. If I go even slightly higher it could double the generation time or worse.
The note box is for my own reference. You can modify this for your own reference.