V3 Final! DeJanked Speed Hack Hunyuan T2V Final Boss
详情
下载文件 (1)
关于此版本
模型描述
Major Overhaul. True refiner speed hack.
DeJanked Speed Hack Hunyuan T2V Final Boss:
Are you tired of your AI video workflow crawling slower than a grandma playing Frogger? Do you crave blistering speed without sacrificing jaw-dropping quality? Buckle up, because this isn’t just a workflow—it’s the Final Boss of Hunyuan T2V optimization. Through the fiery trials of placebo hacks, sanity-testing, and daisy-chain wizardry, this setup slashes render times, keeps your GPU breathing, and still pumps out e-girl-quality frames that’ll have you questioning reality. Dare to try it? It’s fast, it’s smooth, and it might just blow your mind (but not your GPU).
TL/DR:
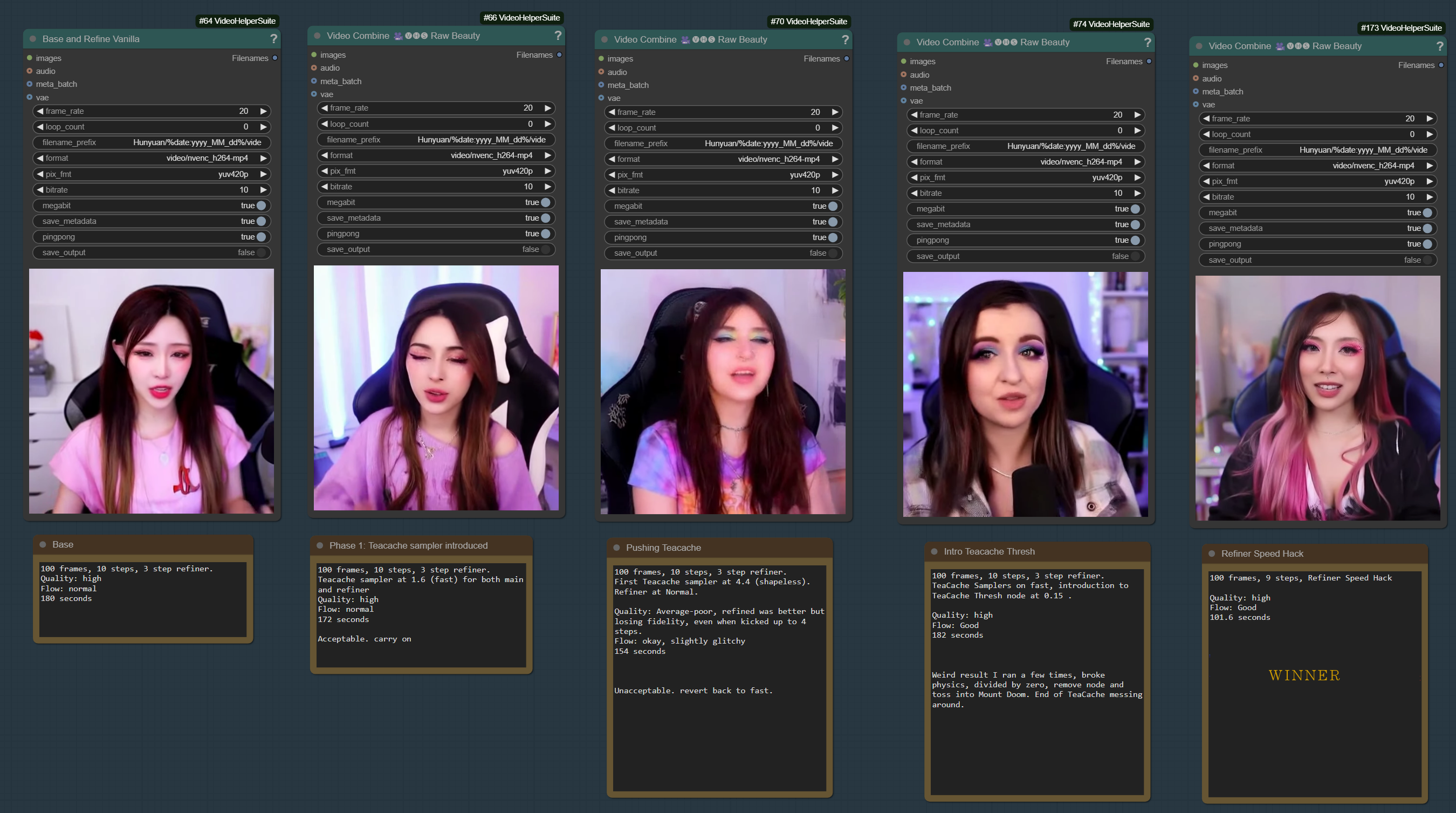
Standard: 180 seconds (Great quality)
After Speed Hack: 100 seconds (great quality)
No descaling/rescaling
No wavespeed and minimal TeaCache.
No XL bs placebo (I feel scammed! See testing below)
This is something else (please post your results)
The testing:
Wavespeed: I will not test it due to it being dependent on Triton, which lots of people have trouble installing on Windows (and can screw up a lot of things with a windows install...those using WSL and Wavespeed can probably figure out how to shove in wavespeed for their own use. this is for maximum availability to the widest amount of users
Hardware I am using: 3090 TI 24g VRAM. 64g Ram, WSL.
100 frames, 10 steps, 3 step refiner 512x512 (no up/downscaling) for base.
Goal:
- find speed without losing quality.
- no use of upscaling or downscaling.
- no tricks, just using standard nodes to their max potential.
Method: 3 generations for each phase.
Vanilla baseline:
Round 1: (basic Vid Gen, no tweaks, just gen and refine)
Flow: normal (no glitchy movements of note)
Quality: high
180 seconds
Pass
Round 2:
Teacache sampler at 1.6 (fast) for both main and refiner
Flow: normal
Quality: high
172-175 seconds
Pass
Round 3:
First Teacache sampler at 4.4 (shapeless). Refiner at Normal
Quality: Average-poor, refined was better but losing fidelity, even when kicked up to 4 steps.
Flow: okay, slightly glitchy (possible exaggerated normal glitchyness)
154 seconds
Fail
Round 4:
TeaCache Samplers on fast, introduction to TeaCache Thresh node at 0.15.
Quality: Good
Flow: good
180 seconds (???)
Fail (pointless to possibly clashing with the sampler)
Result: having samplers in both main and refiner on fast seems to be the happy medium. possible further testing for perhaps faster settings, but will call this enough (a few extra seconds either way isn't the gains I am going for)
On to XL Workaround to kick and see whats what once and for all.
XL hack:
Gone, placebo, nerfed! 185 average. Remove and toss into fires of..etc (I feel I've been scammed!)
next up, Daisy Chain Refiner Speed Hack
results:
1 main and 2 refiner steps without encode/decode:
100 frames, 9 steps
Quality: high
Flow: good
100.34 seconds
Quality can be altered by raising or lowering a step at the beginning if desired, but 5,2,2 is producing stellar results. Recommend starting here
Why does this work?
I don't know, but I assume the first step gives shape. 2nd fleshes out, and 3rd refines. each one working off the less for less overhead and less need to start from scratch, building off the last. Alternatively, simulation universe and pixie dust...obviously.
There you have it. poke holes in it if you can.
Try it, its free, and for me, it is working blazing fast.
Some odd unique occurances come with some renders moving a bit fast (re-render same seed but drop fps down a bit)
From here, see if you can improve it...but before you run this, run your normal non weird workflow without wavespeed for your own vanilla testing to sanity test. make sure to run it 3 times though (need time for cache to warm up. by the 3rd run, you're hitting optimal speeds)
I used the hunyuan 8b 720 (fast) model and the only LoRA I had active was the fastvideo lora (found on civitai) at -0.30 (positive for big model, negative for fast models). Egirl lora added for main video model just for fun but not part of the test.
WARNING: nothing is downscaled. monitor your GPU. best to maybe go smaller. 512x512 to start, then work up (or down) from there. This speeds up your rendering time, but it doesn't lower the GPU overhead.