Animagine XL 4.0


세부 정보
파일 다운로드 (1)
이 버전에 대해
모델 설명
Please read our in-depth Guideline for prompting at Cagliostrolab Blog
Overview
Animagine XL 4.0, also stylized as Anim4gine, is the ultimate anime-themed finetuned SDXL model and the latest installment of Animagine XL series. Despite being a continuation, the model was retrained from Stable Diffusion XL 1.0 with a massive dataset of 8.4M diverse anime-style images from various sources with the knowledge cut-off of January 7th 2025 and finetuned for approximately 2650 GPU hours. Similar to the previous version, this model was trained using tag ordering method for the identity and style training.
With the release of Animagine XL 4.0 Opt (Optimized), the model has been further refined with an additional dataset, improving stability, anatomy accuracy, noise reduction, color saturation, and overall color accuracy. These enhancements make Animagine XL 4.0 Opt more consistent and visually appealing while maintaining the signature quality of the series.
Changelog
- 2025-02-13 – Added Animagine XL 4.0 Opt and Animagine XL 4.0 Zero
Better stability for more consistent outputs
Enhanced anatomy with more accurate proportions
Reduced noise and artifacts in generations
Fixed low saturation issues, resulting in richer colors
Improved color accuracy for more visually appealing results
- 2025-01-24 – Initial release
Model Details
Developed by: Cagliostro Research Lab
Model type: Diffusion-based text-to-image generative model
License: CreativeML Open RAIL++-M
Model Description: This is a model that can be used to generate and modify specifically anime-themed images based on text prompt
Fine-tuned from: Stable Diffusion XL 1.0
Usage Guidelines
The summary can be seen in the image for the prompt guideline.

1. Prompt Structure
The model was trained with tag-based captions and the tag-ordering method. Use this structured template:
1girl/1boy/1other, character name, from which series, rating, everything else in any order and end with quality enhancement
2. Quality Enhancement Tags
Add these tags at the end of your prompt:
masterpiece, high score, great score, absurdres
3. Recommended Negative Prompt
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
4. Optimal Settings
CFG Scale: 4-7 (5 Recommended)
Sampling Steps: 25-28 (28 Recommended)
Preferred Sampler: Euler Ancestral (Euler a)
5. Recommended Resolutions
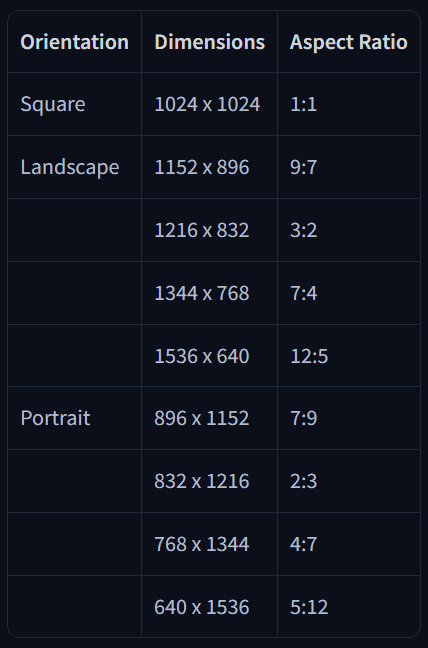
6. Final Prompt Structure Example
1girl, firefly \(honkai: star rail\), honkai \(series\), honkai: star rail, safe, casual, solo, looking at viewer, outdoors, smile, reaching towards viewer, night, masterpiece, high score, great score, absurdres
Special Tags
The model supports various special tags that can be used to control different aspects of the image generation process. These tags are carefully weighted and tested to provide consistent results across different prompts.
Quality Tags
Quality tags are fundamental controls that directly influence the overall image quality and detail level. Available quality tags:
masterpiecebest qualitylow qualityworst quality
Score Tags
Score tags provide a more nuanced control over image quality compared to basic quality tags. They have a stronger impact on steering output quality in this model. Available score tags:
high scoregreat scoregood scoreaverage scorebad scorelow score
Temporal Tags
Temporal tags allow you to influence the artistic style based on specific time periods or years. This can be useful for generating images with era-specific artistic characteristics. Supported year tags:
year 2005year {n}year 2025
Rating Tags
Rating tags help control the content safety level of generated images. These tags should be used responsibly and in accordance with applicable laws and platform policies. Supported ratings:
safesensitivensfwexplicit
Training Information
The model was trained using state-of-the-art hardware and optimized hyperparameters to ensure the highest quality output. Below are the detailed technical specifications and parameters used during the training process:

Acknowledgement
This long-term project would not have been possible without the groundbreaking work, innovative contributions, and comprehensive documentation provided by Stability AI, Novel AI, and Waifu Diffusion Team. We are especially grateful for the kickstarter grant from Main that enabled us to progress beyond V2. For this iteration, we would like to express our sincere gratitude to everyone in the community for their continuous support, particularly:
Moescape AI: Our invaluable collaboration partner in model distribution and testing
Lesser Rabbit: For providing essential computing and research grants
Kohya SS: For developing the comprehensive open-source training framework
discus0434: For creating the industry-leading open-source Aesthetic Predictor 2.5
Early testers: For their dedication in providing critical feedback and thorough quality assurance
Contributors
We extend our heartfelt appreciation to our dedicated team members who have contributed significantly to this project, including but not limited to:
Model
Gradio
Relations, finance, and quality assurance
Data
Fundraising Are Now Open Again!
We're excited to introduce new fundraising methods through GitHub Sponsors to support training, research, and model development. Your support helps us push the boundaries of what's possible with AI.
You can help us with:
Donate: Contribute via ETH or USDT to the address below.
Share: Spread the word about our models and share your creations!
Feedback: Let us know how we can improve.
Donation Address:
ETH/USDT/USDC(e): 0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C
Github Sponsor: https://github.com/sponsors/cagliostrolab/
Why do we use Cryptocurrency?:
When we initially opened fundraising through Ko-fi and using PayPal as withdrawal methods, our PayPal account was flagged and eventually banned, despite our efforts to explain the purpose of our project. Unfortunately, this forced us to refund all donations and left us without a reliable way to receive support. To avoid such issues and ensure transparency, we have now switched to cryptocurrency as the way to raise the fund.
Want to Donate in Non-Crypto Currency?
Although we had a bad experience with Paypal, and you’d like to support us but prefer not to use cryptocurrency, feel free to contact us via Discord Server for alternative donation methods.
Join Our Discord Server
Feel free to join our discord server: https://discord.gg/cqh9tZgbGc
Limitations
Prompt Format: Limited to tag-based text prompts; natural language input may not be effective
Anatomy: May struggle with complex anatomical details, particularly hand poses and finger counting
Text Generation: Text rendering in images is currently not supported and not recommended
New Characters: Recent characters may have lower accuracy due to limited training data availability
Multiple Characters: Scenes with multiple characters may require careful prompt engineering
Resolution: Higher resolutions (e.g., 1536x1536) may show degradation as training used original SDXL resolution
Style Consistency: May require specific style tags as training focused more on identity preservation than style consistency
License
This model adopts the original CreativeML Open RAIL++-M License from Stability AI without any modifications or additional restrictions. The license terms remain exactly as specified in the original SDXL license, which includes:
✅ Permitted: Commercial use, modifications, distributions, private use
❌ Prohibited: Illegal activities, harmful content generation, discrimination, exploitation
⚠️ Requirements: Include license copy, state changes, preserve notices
📝 Warranty: Provided "AS IS" without warranties
Please refer to the original SDXL license for the complete and authoritative terms and conditions.