NAI-XL vpred1.0 2d accelerated

















详情
下载文件 (1)
关于此版本
模型描述
NAI-XL vpred1.0 2d accelerated - colorized
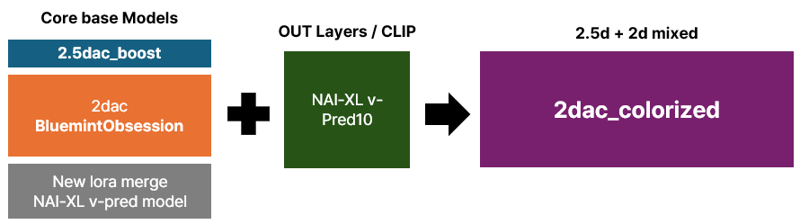 Colorized model solve some of issues in NAI-XL 2dac models where object-background boundaries become blurred and colors appear washed out.
Colorized model solve some of issues in NAI-XL 2dac models where object-background boundaries become blurred and colors appear washed out.
Conversely, mixing artist tags (has very bright color) from 2.5dac and 2.5dac_boost_18 which used to cause overly vivid colors has also been corrected in this version.
The model no longer relies excessively on the CFG Rescale function (though using it around 0.3 is still recommended) and flexibly adapts to various schedulers and samplers.
When compared to this model, users of the 2.5d (Huggingface) model should note that flat color rendering has been reported in realistic styles, so exercise caution when using it.
2D Recommended Settings:
Euler + SGM Uniform
CFG Scale 4.5
Steps 28
CFG Rescale value : 0.6
Quality Prompt (End of prompts):
masterpiece, best quality, absurdres, highres2D Recommended Negative Prompt:
worst quality, blurry, old, early, low quality, lowres, signature, username, logo, bad hands, mutated hands, ambiguous form, (realistic, 3d), black rectangles, (censor bar, bar censor:1.15), colored skin, unfinished, anthro, furry, detailed backgroundNAI-XL vpred1.0 2d accelerated - 2.5d boost
 This 2.5d boost model provides a model that deviates from flat 2D to a slightly 2.5D orientation. It specifically focuses on improved textures for skin and stockings, and by merging with the BluemintObsession model, it ensures that the emphasis on 2D is not lost.
This 2.5d boost model provides a model that deviates from flat 2D to a slightly 2.5D orientation. It specifically focuses on improved textures for skin and stockings, and by merging with the BluemintObsession model, it ensures that the emphasis on 2D is not lost.
However, if you want a more powerful 2.5D-based model, you can download the original model from the following link (d1fb80aa22): NAI-XL_vpred1.0_2.5dac.safetensors · baqu2213/PoemForSmallFThings at main.
 Well, I hope that you and I share a similar taste in textures.
Well, I hope that you and I share a similar taste in textures.
 ‼️ IMPORTANT ‼️ The model’s constraints remain the same as before models. If you choose not to use an artist tag or LoRA, consistent output from the model will not be an appealing feature.
‼️ IMPORTANT ‼️ The model’s constraints remain the same as before models. If you choose not to use an artist tag or LoRA, consistent output from the model will not be an appealing feature.
2d boost model recommended setting (In Reforge):
Euler A
28 Steps
CFG Rescale : 0.5
NAI-XL vpred1.0 2d accelerated - BluemintObsession
 The NAI-XL_vpred1.0_2dac_BO model offers a more aesthetically excellent experience in the 2D illustration area compared to previous models (final, custom). This model partially merges various merged variations of existing NAI-XL_vpred1.0_2dac models along with Obsession (Illustrious-XL) v-pred 1.1, and the vpred_Bluemint2.5D model from the other community. It is especially optimized for KL Optimal scheduler and CFG++ series samplers.
The NAI-XL_vpred1.0_2dac_BO model offers a more aesthetically excellent experience in the 2D illustration area compared to previous models (final, custom). This model partially merges various merged variations of existing NAI-XL_vpred1.0_2dac models along with Obsession (Illustrious-XL) v-pred 1.1, and the vpred_Bluemint2.5D model from the other community. It is especially optimized for KL Optimal scheduler and CFG++ series samplers.
And I attempted to provide a maximally balanced feeling with basic NAI-XL quality/negative prompts. So, you don't have to be overly obsessed with quality prompts and negative prompts. Of course, artist name tags still work well.
NAI-XL vpred1.0 2d accelerated Legacy models
 The custom version is a another model based on the previous model of the final50 version, where the weight ratio of the NAI-XL original model was increased to 65, followed by further adjustments. It is not guaranteed that the model will produce more aesthetic images.
The custom version is a another model based on the previous model of the final50 version, where the weight ratio of the NAI-XL original model was increased to 65, followed by further adjustments. It is not guaranteed that the model will produce more aesthetic images.


Final version: In the previous two merged models, I'm demonstrated that users can generate images with their desired direction by using artist name tags and LoRA merged models.
However, the provided two models were insufficient to satisfy everyone, and some artist tags could not be generated properly even though they were adequately trained. The solution to this problem actually lay within the NAI-XL (Noob v-pred) model itself. The merged model's underperformance is due to excessively trimming the base model's IN/OUT layers.
After uploading the second model, I repeatedly merged the model I created with a popular v-pred-based model and the original NAI-XL model. As a result, I was able to produce a model that, although its basic generated images remain somewhat raw, is capable of correctly reproducing almost all artist tags.
Now, this model can once again restore a wide range of styles as originally intended by the developers of the NAI-XL model. While it may not be aesthetically perfect, it is more than sufficient for you to enjoy and experiment with various artist tags.
Lastly, if you still find the provided model unsatisfactory, try using your preferred LoRA at a very low weight (0.1 ~ 0.3). Enjoy!
** Do not use this model if you not using artist tags. It will be return low-quality images.
Easy Prompting Guide
Positive example
1girl, _artist tag_, _prompts_, _character tags_, (traditional media, watercolor \(medium\), graphite \(medium\):0.8), no lineart, very awa, masterpiece, best quality, amazing quality, absurd res, hi res, highres
Negative example
worst quality, blurry, old, early, low quality, lowres, signature, username, logo, bad hands, mutated hands, ambiguous form, (censored, bar censor:1.1), mature female, colored skin, censored genitalia, censorship, unfinished, anthro, furry, 1990s \(style\), (3d, realistic), black outline, thick outlines, lineart, flat color, bkub
NAI-XL_vpred1.0_2dac_final50 Recommend Parameters (reforge)
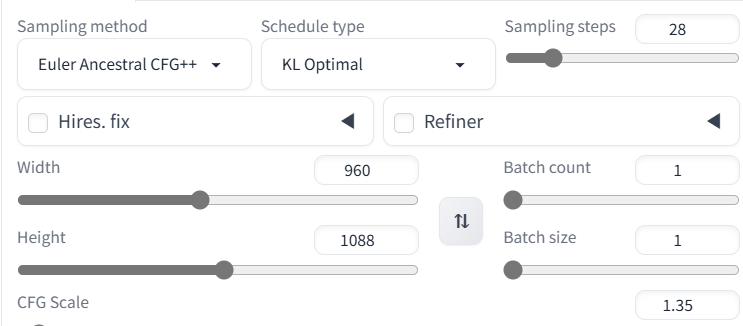
Recommend steps:
28~32
Samplers:
KL Optimal, SGM Uniform
if use non-cfg++ methods; which like Euler
CFG Scale : 3.5
Using CFG++ methods (which like Euler A CFG++)
CFG Scale : 1.15 ~ 1.55 ?
The Scheduler and Sampler should be adjusted appropriately based on the artist name tags used.
Model Description
This model has been uploaded to demonstrate the potential of NAI-XL (specifically noob v-pred 1.0) to model merging experts and community users. Additionally, it serves as a simple, experimental model for those who prefer generating 2D-style images using artist tag combinations, similar to NAI.
[ v1.0 / style2 / style2_heavy (not release) ]
 * Please refer to the Gallery below for the model's recommended prompts.
* Please refer to the Gallery below for the model's recommended prompts.
Noob, the most powerful Illustrious-based open-source SDXL model, includes over 40,000 artist tags that can control image output. However, despite developers’ various efforts to improve aesthetics—such as adding aesthetic tags like "very awa" and "very aesthetic"—it remains quite challenging to modify the image output to individual user preferences prompting only. This is why most uploaders choose to perform fine-tuning through additional training or precise block merging.
However, just as we experienced during the long days of SD 1.5, Noob-based models appear to be fully capable of adjusting the aesthetic range of generated images even with a simple LoRA merge on a checkpoint.
On this page, I'm offer a simple LoRA merged model intended to give users an experience akin to a minor copy version of NAI Diffusion 2 or 3.
I look forward to more community members attempting these merges and sharing their feedback.
style2 (Feb 5)
Offer a style2 model that is similar to the original but provides a slightly different experience.


Is this version better?
-> It's hard to say that it's explicitly better. I believe the sample images should give you a sense of the overall differences between the two models.
In some artist tag combinations, v1 might perform better, while in others the new style2 model may feel superior. However, you'll notice a slight improvement in the background and a reduction of the strong noise typically seen in 2D-flat images. More noticeable changes will emerge as you gradually add your preferred LoRAs at lower weights.
If you have some time, please scroll down and read the TL; DR section.
Merge Recipe of style2
Current Model :: Add Difference NoobAI-XL (NAI-XL) V-Pred 1.0 * 0.5 + (Model C - NoobAI-XL (NAI-XL) V-Pred 1.0) * 0.5 -> 173ef090a1
after merge, additionally merging this loras:
customUdonXL_il_lokr_V5311P:0.1 https://civitai.com/models/1179146?modelVersionId=1326916
szcb911-il:0.24 https://civitai.com/models/1205063/or-szcb911-style?modelVersionId=1357045
nyalia:0.14 https://civitai.com/models/834822?modelVersionId=934002
Model C :: LoRA Merged (from 384df0d35c)
TS**おじさんの冒険NoobAI-XLVPred10_DoRA_V1:0.3, morin:0.13, jhon:0.15, chwinta_nai3:0.1 - personal trainned or restricting reuploads from external community
nyaliaXL_NBVP1_lokr_V6311P:0.15 https://civitai.com/models/940505/sdxl-artist-style-nyalia?modelVersionId=1357202
szcb911-il:0.2 https://civitai.com/models/1205063/or-szcb911-style?modelVersionId=1357045
kazutake_hazano:0.2 https://civitai.com/models/1209290/kazutake-hazano-artist-artstyle-or-noobai-xl?modelVersionId=1362000
Note: Each individual LoRA model used in the merge has excellent quality. Please show your support to their uploaders.
How to use v-pred model
For basic guidelines on model usage, please refer to: https://civitai.com/models/833294?modelVersionId=1190596
Recommended Settings
Parameters
Recommended Scheduler: KL Optimal
Sampling Method: Euler Ancestral CFG++, Euler DY CFG++, Euler SMEA DY CFG++
Important Notice: The recommendation for a low CFG scale value (1.15) is based on incorrect information. You should determine the appropriate CFG value that best suits your merged style.
Recommend use 1.25x upscale with denoise 0.25, hires 10 steps if you use Euler DY or SMEA DY, else only recommend using ADetailer or Face Detailers
Merge Recipe
0.55 Model A + 0.45 Model B simply merged by weight sum method
Model A: LoRA Merged
cactusman:0.2, https://civitai.com/models/1034691/cactusman-style-or-nai-style-for-illustrious
customUdonXL_il_lokr_V5311P:0.3, https://civitai.com/models/1179146?modelVersionId=1326916
Cutesexyrobutts_IL:0.45, https://civitai.com/models/914164/cutesexyrobutts-artist-style-pony-xl-illustrious
kanzarinXL_il_lokr_V5311P:0.25, https://civitai.com/models/1082037?modelVersionId=1214943
kedamaaXL_il_lokr_V5311P:0.2, https://civitai.com/models/453742/sdxl-artist-style-kedamaa
Nekoblow_Style_for_Illustrious-000015:0.4, https://civitai.com/models/1194096?modelVersionId=1344453
null1040:0.55 https://civitai.com/models/1103697?modelVersionId=1239850
Model B: LoRA Merged
null1040:0.3 https://civitai.com/models/1103697?modelVersionId=1239850
customUdonXL_il_lokr_V5311P:0.14, https://civitai.com/models/1179146?modelVersionId=1326916
Cutesexyrobutts_IL:0.45, https://civitai.com/models/914164/cutesexyrobutts-artist-style-pony-xl-illustrious
cactusman:0.1, https://civitai.com/models/1034691/cactusman-style-or-nai-style-for-illustrious
kanzarinXL_il_lokr_V5311P:0.11, https://civitai.com/models/1082037?modelVersionId=1214943
Nekoblow_Style_for_Illustrious-000015:0.14, https://civitai.com/models/1194096?modelVersionId=1344453
kedamaaXL_il_lokr_V5311P:0.08, https://civitai.com/models/453742/sdxl-artist-style-kedamaa
deal360acv:0.3, https://civitai.com/models/824674?modelVersionId=1003884
nyalia:0.2, https://civitai.com/models/834822?modelVersionId=934002
arcain-2411:0.11, https://civitai.com/models/1136669?modelVersionId=1278028
noobai_sora72iro_sdxl_lora:0.1, (Deleted)
nekojiraXL_il_lokr_V5311P:-0.15 https://civitai.com/models/470878/sdxl-artist-style-nekojira?modelVersionId=1207384
Note: Each individual LoRA model used in the merge has excellent quality. Please show your support to their uploaders.
This model follows all restrictions and licenses of NoobAI-XL (NAI-XL), and the uploader claims no rights to this model. For detailed information, please refer to: https://civitai.com/models/833294/noobai-xl-nai-xl
TL; DR with My Dogshit Philosophy
Well, for users who think "I have understand Noob to some extent", there's no need to search and tour Civitai for download heavy models which haven't extensive additionally trainined.
Instead, you can simply use the original Noob v-pred model and adjust its output by suitable LoRAs. There isn't any magical model that optimizes everything from 2D to 3D full-range.
What you likely need right now isn’t a casual journey through the Checkpoint category, but rather a treasure hunt in the LoRA category.
 * ac5a09ddd6 is model A, 697047f3c4 is model B. and 384df0d35c is 0.55*A + 0.45*B merged model.
* ac5a09ddd6 is model A, 697047f3c4 is model B. and 384df0d35c is 0.55*A + 0.45*B merged model.
The three models used in this merge might look nearly identical at first glance, but once their artist tags are mixed to some degree, the resulting outputs can be completely different. In particular, when you push the style to the extreme 2D or semi-realistic end, the results can turn out either very appealing or not so much.
 * 7405ac0382 is dropped model. It consumed the most time during the merging process. While it looked good without any artist tags, a dramatic decline in quality was observed once the artist tags were applied.
* 7405ac0382 is dropped model. It consumed the most time during the merging process. While it looked good without any artist tags, a dramatic decline in quality was observed once the artist tags were applied.
Most merged models—like the one provided on this page—are tuned to a moderate degree based on the creator’s taste, so in practice, the actual outputs tend to be more or less the same. Ultimately, the best approach is for you to find and combine your own LoRAs.
Merged model is simply a means to optimize generation speed.
** Note: This is not meant to undermine the efforts of model merging experts. In fact, if you don’t use any artist tag combinations or only use one or two you can still generate relatively high-quality images. However, since everyone’s taste differs, it ultimately falls on the user to create a model that suits their own preferences. Alternatively, you can try learning LoRA yourself. Civitai has a simple and excellent Lora Training service, although it has some limitations. Have a good time !