Neo-Noir ⛩️ by Huggy







Details
Download Files (1)
About this version
Model description
💡 Search "huggy" to find all my models on site.
💡 Models are updated frequently, so be sure to check back and use the latest version.
⛩️ Version 3
Optimised between stylisation, quality, and generalisation, with double training steps and half training speed,
making it the most costly lora trained so far.
⛩️ Instructions for Version 3
Essential trigger words:
grainy_anime,(soft shadows:1.2),dark backgroundLighting trigger words:
Change the color as you like.
Some colors (like red) can be very sensitive — reduce intensity by using weight, e.g.:
(red primary lighting:0.85)Other lighting triggers you can use:
Change the color as you like.
orange accent details
yellow dramatic lighting
green ambient lighting
pink shadingQuality trigger word:
Version 3 is optimised for 2.5D or realistic style.
Only use this during high-res fix / add detailer step.
Avoid adding it in the first generation, as it will consume too much attention and ruin the style.
realistic⛩️ To be fixed in next version:
Use more training data and more aggressive training (10,000 steps) to fight stubborn red / yellow color bias.
Fix data caption typos:
Add missing word:
"front"Fix typo:
"ambientt"→"ambient"Remove repeats:
"paper coffee cup / soda can""dark cloud""red curtain" / "hairy"
Add new keyword:
"afternoon"Remove redundant:
"simple background"
🧪 V2.5E24 — Experimental trail before version 3
Not neo-noir but definitely pretty funky.
This version significantly improves overall quality thanks to data cleaning by Flux Kontext.
The new training solution, however, couldn’t fully stay true to the exact style of the training data, but surprisingly, it’s fun and easy to play with!
🧪 Instructions for V2.5E24
Best base model:
Hassaku XL (Illustrious) v1.3 - Style A
For anime style:
Use CFG Scale:
5Use Steps:
>36
V2.5E24 is optimized for 2.5D style anime:
First, generate a flat anime image as usual.
Then apply high-res fix or an add detailer pass.
At this stage, add an extra prompt:
"realistic"
Avoid using"realistic"too early (in the first generation), because it consumes too much attention and can ruin the style.
🧪 Advanced trigger words for V2.5E24 (use cautiously — it’s wild)
red dramatic lighting(works with any color)blue shading(any color + shading)use "red skin" as negative prompt to neutralise this effect
These can add dramatic depth and atmosphere, but can also stain the skin unexpectedly intense.
🧪 Gender bias note
Trained equally on 63 male + 63 female images.
Due to bias in most base models, male characters might look androgynous.
To generate truly masculine characters, add extra prompts:
male,manly,bara
📒 What changed in version V2.5E24:
Make this lora less reliant on trigger words and boost its own style instead.
Optimize the training files to get 6 different vivid color themes.
New cleaning & sorting workflow for training files:
Remove distortion, artifacts, borders, distracting objects, and irrelevant backgrounds
Apply color grading, contrast adjustment, and HDR toning
Generate variants with different color themes and outfits
Create both anime-style and realistic-style
📒 Earlier Version:
V02E26 / V02E41 - low fidelity model works easily with other lora.
V02E76 / V02E81 - high fidelity model only use as standalone lora.
⛩️Recommended trigger words (for earlier version):
This lora is highly dependent on trigger words to create a moody and melodramatic atmosphere.
"Essential": hu99y, film grain, dramatic light, rim light, dark,“Color”: “red” and “blue” dramatic light, “yellow” and “green” color scheme,
“Sky”: sunset, sunrise, “golden” sky, dark cloud,
“Scenery”: cityscape, building, field, mountain, trail, beach, ocean,
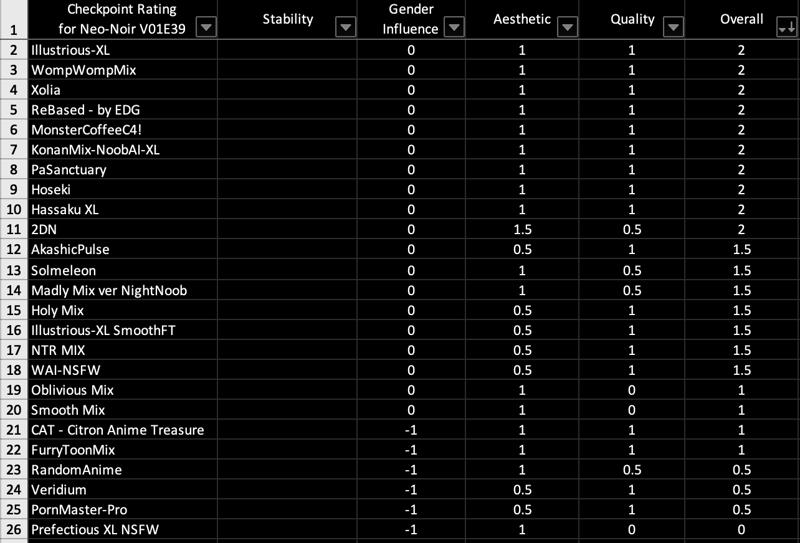
⛩️ Checkpoint Rating (for earlier version):
 🎉 This lora is part of my goal to create 100 lora.
🎉 This lora is part of my goal to create 100 lora.
📒 Mirroring
I’ve noticed a few sites, like Modelslab and yodayo, using bots to mirror my models. SeaArt in particular shows big numbers for downloads and generations.
I don’t mind if you mirror my models — sites like civitaiarchive have always done that.
I do mind if you block users from downloading the models and force them onto a paid online service.
I do mind if you claim copyright or give users ownership of the generations. These are open-source models, trained on open-source bases with limited-ownership data. No one — not even me — should claim copyright. Credit is all that’s needed.