Anime Illust Diffusion XL



















詳細
ファイルをダウンロード
このバージョンについて
モデル説明
モデル紹介(英語部分)
I 目次
この紹介では、以下について学びます:
モデル情報(第II節をご覧ください);
使用方法(第III節をご覧ください);
学習パラメータ(第IV節をご覧ください);
トリガー単語一覧(付録Aをご覧ください)。
II AIDXL
Anime Illustration Diffusion XL、または**AIDXL**は、スタイル化されたアニメイラストを生成することを目的としたモデルです。このモデルには、800種類以上(更新とともにさらに増加中)の組み込みイラストスタイルが搭載されており、特定のトリガー単語(付録Aをご覧ください)によってトリガーされます。
利点:
伝統的なAIポージングではなく、柔軟な構図。
ごちゃごちゃした混沌ではなく、熟練したディテール。
アニメキャラクターをよりよく理解しています。
III ユーザーガイド
1 基本的な使い方
1.1 プロンプト
トリガー単語:付録Aに記載されたトリガー単語を追加して画像をスタイル化してください。適切なトリガー単語は大幅に品質を向上させます。
アーティストスタイルのトリガー単語には重みを減らすことを推奨します。例:(by xxx:0.6)。
意味的ソート:プロンプトのタグや文を並べ替えることで、モデルが意味をよりよく理解できるようになります。
推奨タグ順序:トリガー単語(by xxx)→ キャラクター(『霜降り明星』シリーズの『フリーレン』という名前の少女)→ 種族(エルフ)→ 構図(カウボーイショット)→ スタイル(インパストスタイル)→ テーマ(ファンタジー)→ 主な環境(森の中、昼間)→ 背景(グラデーション背景)→ アクション(床に座っている)→ 表情(無表情)→ 主な特徴(白髪)→ 体の特徴(ツインテール、緑の目、開いた唇)→ 衣装(白いドレスを着ている)→ 衣装のアクセサリー(フリル)→ その他のアイテム(猫)→ 次の環境(草、日差し)→ 美学(美しい色、詳細、審美的)→ 品質((best quality:1.3))
否定的プロンプト:(worst quality:1.3)、low quality、lowres、messy、abstract、ugly、disfigured、bad anatomy、draft、deformed hands、fused fingers、signature、text、multi views
1.2 生成パラメータ
解像度:合計ピクセル数(=幅×高さ)が約1024×1024となり、幅と高さが32の倍数であることを確認してください。その場合、AIDXLは最良の結果を生成します。例:832x1216(2:3)、1216x832(3:2)、1024x1024(1:1)など。
サンプラーとステップ数:「Euler Ancester」サンプラー(WebUIではEuler Aと呼ばれます)を使用し、CFGスケールを7〜9に設定し、約28ステップでサンプリングしてください。
「リファイン」:テキストから画像を生成した結果がぼやける場合、画像2画像(image2image)やインペインティングなどを使用して「リファイン」する必要があります。
単純な拡大については、以下のリンクを参照してください:Upscale to huge sizes and add detail with SD Upscale, it's easy! : r/StableDiffusion (reddit.com)
その他のコンポーネント:リファイナーモデルは不要です。モデル自体のVAEまたは
sdxl-vae.を使用してください。
Q:モデルのカバー画像を再現するにはどうすればよいですか?同じ生成パラメータを使っても、カバー画像と同じ画像を再現できないのはなぜですか?
A:カバーに表示されている生成パラメータは、テキスト2画像のパラメータではなく、画像2画像(拡大用)のパラメータです。ベース画像は、DPMサンプラーではなく、主にEuler Ancesterサンプラーで生成されています。
2 特殊な使い方
2.1 汎用スタイル
バージョン0.7から、AIDXLはいくつかの類似スタイルをまとめ、汎用スタイルトリガー単語を導入しました。これらのトリガー単語はそれぞれ一般的なアニメイラストスタイルカテゴリを表しています。ただし、汎用スタイルトリガー単語は、その語義が示す芸術的意味に必ずしも従うわけではなく、再定義された特別なトリガー単語であることにご注意ください。
2.2 キャラクター
バージョン0.7から、AIDXLはキャラクターの学習を強化しました。一部のキャラクタートリガー単語の効果は、LoRAと同等の効果を発揮し、キャラクターの概念とその衣装を明確に分離できます。
キャラクターのトリガー方法は:{キャラクター} \({著作権}\) です。たとえば、アニメ『サイバーパンク:エッジランナーズ』のヒロイン「ルーシー」をトリガーするにはlucy \(cyberpunk\)、ゲーム『原神』のキャラクター「甘雨」をトリガーするにはganyu \(genshin impact\)と入力します。ここで、「lucy」と「ganyu」はキャラクター名、「(cyberpunk)"と"(genshin impact)"はそれぞれのキャラクターの元ネタであり、括弧は重みタグとして解釈されないようにスラッシュ「\」でエスケープしています。一部のキャラクターでは著作権部分は不要です。
バージョンv0.8からは、さらに簡単なトリガー方法が追加されました:a {girl/boy} named {character} from {copyright} series。
キャラクタートリガー単語の一覧については、こちらをご覧ください:selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 at main (huggingface.co). また、この文書に記載されていない追加のトリガー単語も含まれている可能性があります。
一部のキャラクターには追加のトリガー手順が必要です。使用中に1つのキャラクタートリガー単語だけではキャラクターが完全に再現されない場合、キャラクターの主要な特徴をプロンプトに追加する必要があります。
AIDXLはキャラクターの衣装着せ替えをサポートしています。キャラクタートリガー単語は通常、キャラクター自身の衣装特性を含まないため、キャラクターの衣装を追加するには、プロンプトに衣装タグを追加する必要があります。たとえば、silver evening gown, plunging necklineと入力すると、ゲーム『Azur Lane』のキャラクター「聖ルイ(Luxurious Wheels)」のドレスを表現できます。同様に、他のキャラクターにも任意のキャラクターの衣装タグを追加できます。
2.3 品質タグ
_品質_および_美学_タグは公式に学習されています。プロンプトにこれらのタグを追加することで、生成画像の品質に影響を与えます。
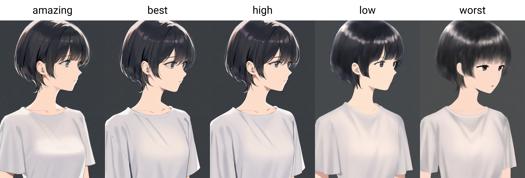
バージョン0.7から、AIDXLは公式に品質タグを学習・導入しました。品質は、最上位から下位へと6段階に分類されています:amazing quality、best quality、high quality、normal quality、low quality、worst quality。
品質タグには追加の重みを付けることを推奨します。例:(amazing quality:1.5)。
2.4 美学タグ
バージョン0.7から、画像の特殊な美学的特徴を記述するために美学タグが導入されました。
2.5 スタイルのマージ
複数のスタイルをマージして、オリジナルのスタイルを作成できます。「マージ」とは、複数のスタイルトリガー単語を同時に使用することを意味します。例:chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
ヒント:
スタイルの重みと順序を調整してスタイルを制御してください。
プロンプトに追加する(先頭に追加しない)ようにしてください。
IV 学習戦略とパラメータ
AIDXLv0.1
SDXL1.0をベースモデルとし、約22,000枚のラベル付き画像を使って、学習率5e-6、サイクル数=1のコサインスケジューラで約100エポック学習し、モデルAを取得します。その後、学習率2e-7で同じ他のパラメータを使用してモデルBを取得します。AIDXLv0.1モデルはモデルAとBをマージして得られます。
AIDXLv0.51
学習戦略
AIDXLv0.5からの再開学習で、3つの学習フェーズを連続して実行します:
長文キャプション学習:全データセットを使用し、一部の画像は手動でキャプションを追加します。U-Netとテキストエンコーダーの両方をAdamW8bit最適化器、高学習率(約1.5e-6)、コサインスケジューラで学習します。学習率がしきい値(約5e-7)以下に低下したら学習を停止します。
短文キャプション学習:ステップ1の出力を初期値として、同じパラメータと戦略を用いますが、キャプション長が短いデータセットで再学習します。
微調整ステップ:ステップ1のデータセットから、手動で選定された高品質画像のサブセットを準備します。ステップ2の出力を初期値として、低学習率(約7.5e-7)、再起動回数5〜10回のコサインスケジューラで再学習します。結果が美学的に良いときに学習を停止します。
固定学習パラメータ
ノイズオフセットなどの追加ノイズは使用しない。
Min snr gamma = 5:学習速度を向上させる。
全bf16精度。
AdamW8bit最適化器:効率と性能のバランス。
データセット
解像度:1024x1024の合計解像度(=高さ×幅)で、SDXL公式のバケット戦略を適用。
キャプション付け:WD14-Swinv2モデルを使用し、しきい値0.35でキャプション付け。
クローズアップ切り抜き:画像を複数のクローズアップに切り抜きます。トレーニング画像が大きかったり希少な場合に非常に有効です。
トリガー単語:画像の最初のタグをそのトリガー単語として保持します。
AIDXLv0.6
学習戦略
AIDXLv0.52からの再開学習ですが、適応的な繰り返し戦略を導入します。データセット内の各キャプション付き画像について、以下のルールに基づいてトレーニング中の繰り返し回数を増加させます:
ルール1:画像の_品質_が高ければ高いほど、繰り返し回数を増やす。
ルール2:画像がスタイルクラスに属する場合:
クラスがまだ適合していない、または_不足適合_の場合は、手動でそのクラスの繰り返し回数を増やす、または自動的に増やして、そのクラスのデータ合計繰り返し回数が特定の事前設定値(約100)に達するようにする。
クラスがすでに適合している、または_過適合_の場合は、手動でそのクラスの繰り返し回数を1に強制し、品質が低い場合は削除する。
ルール3:繰り返し回数は、最終的な繰り返し回数が特定のしきい値(約10)を超えないように制限する。
この戦略には次のような利点があります:
新しい学習からモデルの元の情報を保護し、正則化画像と同様の考えに基づいている。
学習データの影響をより制御しやすくなる。
各クラス間の学習バランスを保ち、適合していないクラスを促進し、すでに適合しているクラスの過適合を防ぐ。
計算リソースを大幅に節約でき、モデルに新規スタイルを追加しやすくなる。
固定学習パラメータ
AIDXLv0.51と同一。
データセット
AIDXLv0.6のデータセットはAIDXLv0.51をベースとし、以下の最適化戦略を適用しています:
キャプションの意味的ソート:意味の順序でキャプションタグを並べ替える。例:"gun, 1boy, holding, short hair" → "1boy, short hair, holding, gun"。
キャプションの重複除去:重複タグを削除し、最も情報を保持するタグを残す。重複タグとは、意味が類似しているタグ(例:"long hair" と "very long hair")のこと。
追加タグ:すべての画像に手動で追加タグを付加(例:"high quality"、"impasto" など)。これはいくつかのツールを使用して迅速に行えます。
V 特別な謝辞
計算資源の支援:@NieTaコミュニティ(捏Ta (nieta.art))に計算資源の提供に感謝します。
データ提供:@KirinTea_Aki(KirinTea_Aki Creator Profile | Civitai)と@Chenkin(Civitai | Share your models)に膨大なデータ提供に感謝します。
彼らがいなければバージョン0.7は存在しませんでした。
VI AIDXL と AID の比較
2023/08/08。AIDXLはAIDv2.10と同じトレーニングセットで学習されていますが、AIDv2.10を上回る性能を発揮します。AIDXLはより賢く、SD1.5ベースのモデルではできない多くのことを実行できます。また、概念の違いを明確に区別し、画像の細部を学習し、SD1.5やAIDでは困難または不可能な構図を処理する能力も優れています。全体的に、その可能性は絶大です。今後もAIDXLを継続的に更新していきます。
VII サポート
私たちの作業にご賛同いただけましたら、Ko-fi(https://ko-fi.com/eugeai)を通じて支援していただけると、研究開発の継続に大きく貢献します。ご支援ありがとうございます!
- ネガティブプロンプト:worst quality, low quality, lowres, messy, abstract, ugly, disfigured, bad anatomy, deformed hands, fused fingers, signature, text, multi views
1.2 生成パラメータ
解像度:画像の合計解像度(合計解像度=高さ×幅)が1024×1024付近にあり、幅と高さがいずれも32の倍数であることを確認してください。例:832x1216 (3:2)、1216x832 (3:2)、および1024x1024 (1:1)。
「Clip Skip」操作を行わず、Clip Skip = 1とします。
サンプラーとステップ数:「euler_ancester」サンプラー(sampler)を使用します。この組み合わせはwebuiではEuler Aと呼ばれます。CFG Scaleを7に設定し、28ステップでサンプリングします。
精錬器(Refiner)は使用せず、モデル本体のみを使用します。
ベースモデルのVAEまたはsdxl-vaeを使用します。
2 特殊な使用法
2.1 泛スタイル化
0.7版では、いくつかの類似したアニメイラストスタイルを整理し、汎用スタイルトリガー語を導入しました。汎用スタイルトリガー語は、一般的なアニメイラストスタイルのカテゴリをそれぞれ代表します。
ただし、汎用スタイルトリガー語はその語義が指す美術的意味に必ずしも合致するわけではなく、再定義された特殊なトリガー語です。
2.2 キャラクター
0.7版ではキャラクターの強化トレーニングを行いました。一部のキャラクタートリガー語の再現度はLoRAと同等のレベルに達し、キャラクターの概念とその服装を明確に分離して扱うことができます。
キャラクタートリガーの形式は キャラクター名 \(作品\) です。たとえば、アニメ『サイバーパンク:エッジランナーズ』のヒロインルーシーをトリガーする場合は lucy \(cyberpunk\)、ゲーム『原神』のキャラクター甘雨をトリガーする場合は ganyu \(genshin impact\) とします。ここで、「lucy」と「ganyu」はキャラクター名、「\(cyberpunk\)」と「\(genshin impact\)」はそれぞれ対応する作品名であり、括弧は「\」でエスケープしてプロンプトの重み付けと誤解されないようにしています。一部のキャラクターについては作品名は必須ではありません。
キャラクタートリガー語については、selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 at main (huggingface.co) を参照してください。
使用中に単一のキャラクタートリガー語だけで完全にキャラクターを再現できない場合は、プロンプトにそのキャラクターの主な特徴を追加する必要があります。
キャラクタートリガー語は通常、キャラクターの服装特性を含まないため、服装を追加するにはプロンプトに衣装名を明記する必要があります。たとえば、ゲーム『碧藍航線』のキャラクター聖ルイーズ(st. louis \(luxurious wheels\) \(azur lane\))の服装をトリガーするには、silver evening gown, plunging neckline を使用します。同様に、任意のキャラクターに他のキャラクターの衣装タグを追加することも可能です。
2.3 クオリティタグ
0.7版のクオリティおよび美学タグは正式にトレーニング済みであり、プロンプトの末尾にこれらを追加することで生成画像のクオリティに影響を与えます。
0.7版では、クオリティタグが正式にトレーニング・導入され、6段階に分かれています。良から悪へ:amazing quality, best quality, high quality, normal quality, low quality、および**worst quality**。
2.4 美学タグ
0.7版から美学タグが導入され、画像の特異な美学的特徴を記述します。
2.5 スタイル融合
複数のスタイルをカスタムスタイルに組み合わせることができます。「融合」とは、複数のスタイルトリガー語を一度に使用することを意味します。例:chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
いくつかのコツ:
スタイルの重みと順序を調整することで、最終的なスタイルを制御します。
プロンプトの末尾に追加し、先頭に置かないでください。
3 注意事項
SDXLに対応するVAEモデル、テキスト埋め込み(embeddings)モデル、LoRAモデルを使用してください。注意:sd-vae-ft-mse-originalはSDXLに対応していないVAEです。EasyNegative、badhandv4などのネガティブテキスト埋め込みもSDXLに対応していないembeddingsです。
0.61以下バージョンの場合:画像生成時は、モデル専用のネガティブテキスト埋め込み(Suggested Resources欄からダウンロード可能)を強く推奨します。モデル専用のため、ほぼすべてのケースで正の効果をもたらします。
各バージョンで新たに追加されたトリガー語は、そのバージョンでは相対的に効果が弱かったり不安定であることがあります。
IV トレーニングパラメータ
SDXL1.0をベースモデルとし、約2万枚の自己ラベル付け画像を用いて、学習率5e-6、エポック数1のコサインスケジューラで約100エポックトレーニングし、モデルAを取得しました。その後、学習率2e-7、その他のパラメータを同じくしてトレーニングし、モデルBを取得しました。モデルAとBを混合してAIDXLv0.1モデルを生成しました。
その他のトレーニングパラメータについては英語版の説明を参照してください。
V 特別感謝
計算資源提供:@捏Taコミュニティ(捏Ta (nieta.art))の計算リソース提供に感謝します。
データ提供:@秋麒麟熱茶(KirinTea_Aki Creator Profile | Civitai)および@風吟(Chenkin Creator Profile | Civitai)の膨大なデータ提供に感謝します。
これらがなければ、0.7版は存在しませんでした。
VI 更新ログ
2023/08/08:AIDXLはAIDv2.10と同じトレーニングデータセットを使用してトレーニングされましたが、AIDv2.10より優れた性能を発揮します。AIDXLはより賢く、SD1.5ベースモデルでは不可能な多くのことを実現できます。異なる概念を正確に区別し、画像の細部を学習し、SD1.5にとって極めて困難な構図を処理し、旧版AIDが完全に習得できなかったスタイルをほぼ完璧に学習できます。総じて、SD1.5よりもはるかに高い上限を持ち、今後もAIDXLを継続して更新していく予定です。
2024/01/27:0.7版では大量の新機能が追加され、データセットの規模は前バージョンの2倍以上です。
満足のいくラベル付けを得るために、ラベルの並び替え、ラベルの階層的ランダマイズ、キャラクター特徴の分離など、複数の新しいラベル処理アルゴリズムを試行しました。プロジェクトページ:Eugeoter/sd-dataset-manager (github.com);
トレーニングをより制御可能かつ自分の意図に従わせるために、Kohya-ssを基に独自のトレーニングスクリプトを作成しました;
異なる世代のモデルの融合プロセスを制御するために、いくつかのヒューリスティックなモデル融合アルゴリズムを開発しました。モデルのスタイルを十分に高めるために、テキストエンコーダーとUNetのOUT層を融合させてモデルの安定性と美学を向上させる手法を放棄しました。なぜなら、それがモデルのスタイルを損なう可能性があるからです。
データの選別とフィルタリングのために、ウォーターマーク検出モデル、画像分類モデル、美学スコアリングモデルをトレーニングし、データのクリーニングを支援しました。
VII サポートをお願いします
私たちの活動を気に入っていただけたら、Ko-fi(https://ko-fi.com/eugeai)を通じてご支援をお願いします。研究と開発の継続にご協力いただき、ありがとうございます!
Appendix / 付録
A. 特殊トリガー語一覧 / Special Trigger Words List
アートスタイルトリガー語:こちらをクリック
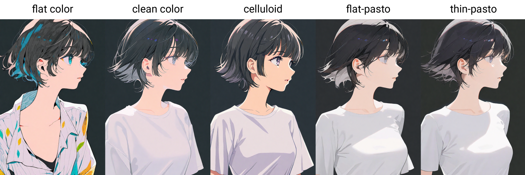
ペインティングスタイルトリガー語:flat color, clean color, celluloid, flat-pasto, thin-pasto, pseudo-impasto, impasto, realistic, photorealistic, cel shading, 3d
flat color: 平面色を使用し、線で明暗を表現する
平塗:平面色を用い、線と色塊で光と影、階調を表現する
clean color: flat colorとflat-pastoの間のスタイル。シンプルで整理された色彩
簡潔な色調の平塗。flat colorとflat-pastoの中間
celluloid: アニメ色調
平塗セル:アニメの着色スタイル
flat-pasto: ほぼ平面色で、グラデーションを用いて光と影を表現
ほぼ平面色で、グラデーションを用いて光と影、階調を表現
thin-pasto: 細い輪郭線を用い、グラデーションと塗料の厚みで光、影、階調を表現
細い輪郭線で、グラデーションと塗料の厚みを用いて光と影、階調を表現
pseudo-impasto:グラデーションと塗料の厚みを用いて光、影、階調を表現
仮想厚塗り/半厚塗り:グラデーションと塗料の厚みで光と影、階調を表現
impasto:塗料の厚みを用いて光、影、階調を表現
厚塗り:塗料の厚みで光と影、階調を表現
realistic
写実的
photorealistic:現実世界に近いスタイルに再定義
写真的リアリズム:現実世界に近いスタイルとして再定義
cel shading: アニメ3Dモデリングスタイル
セルシャドウ:二次元3Dモデリングスタイル
3d

美学トリガー語:
beautiful
美しい
aesthetic: 少し抽象的な芸術的感覚
唯美的:やや抽象的な芸術的な感覚
detailed
細部まで描かれた
beautiful color: 色彩の繊細な使用
調和の取れた色:洗練された色彩の使い方
lowres
messy: 絵の構図や細部がごちゃごちゃしている
雑多:構図や細部が散らかっている
クオリティトリガー語:amazing quality, best quality, high quality, low quality, worst quality