Hunyuan Video T2V/V2V Flexible LoRA Workflow






Details
Download Files (1)
About this version
Model description
[Recent Changes]
I have updated v1.1 beta to v1.11. The nodes have been replaced with new ones to better support multiple LoRAs, and some width and height nodes in the v2v group have been modified to make resolution adjustments easier.
+(v1.11)Fixed an issue with incorrect connections between the output and decode nodes. If you have downloaded a previous version, please download it again.
+There may be issues with the latest version of ComfyUI. If you encounter problems with InstructPixToPixConditioning node, use 'Switch ComfyUI' in the ComfyUI Manager to roll back to version v0.3.13 and then restart ComfyUI.
LoRA can be dynamically applied based on the situation, adjusting to different stages of generation.
This is not a workflow I implemented, but the original author has mentioned that uploading it to Civitai under my account is fine if desired. For convenience, I have modified some nodes and am sharing it here.
Most LoRAs for Hunyuan Video are trained for real-life humans, which can cause various issues when applied to 2D characters. This workflow enables LoRAs to be applied at different stages to mitigate these problems.
I primarily use this for anime-style video generation, but I believe it will also be beneficial for real-life human subjects.
+If any group names or notes seem a bit off, it's probably due to my English skills. I appreciate your understanding!
I have uploaded two versions of the workflow:
Includes Tea Cache and Wavespeed
Uses only ComfyUI core nodes (Tea Cache and Wavespeed removed to avoid potential issues in some environments).
⚠️ The version with Tea Cache and Wavespeed may cause issues in some environments (especially on Windows without Triton). If you experience problems, try using the core-only version.
I do not cherry-pick results, so the explanations are based on images generated after modifying the workflow.
T2V Generation Example:
Same prompt, same seed, and all settings fixed.
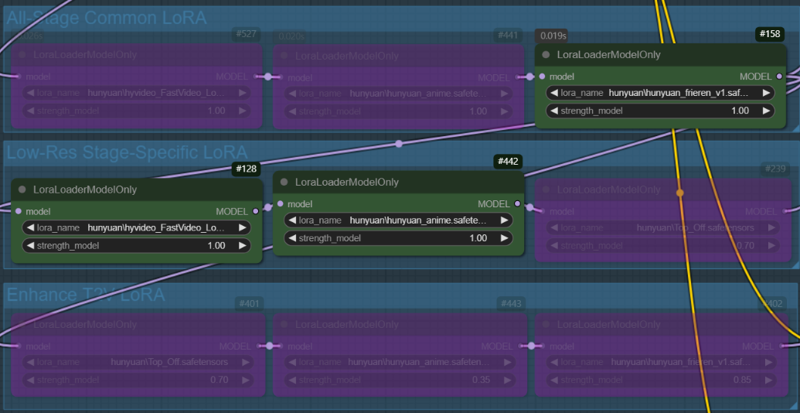
Case 1: A character LoRA is used across all nodes. In the low-res stage, the fast LoRA and style LoRA are applied, while no LoRA is used in the enhance T2V stage(In this stage, only the all-stage LoRA (character LoRA) is applied).

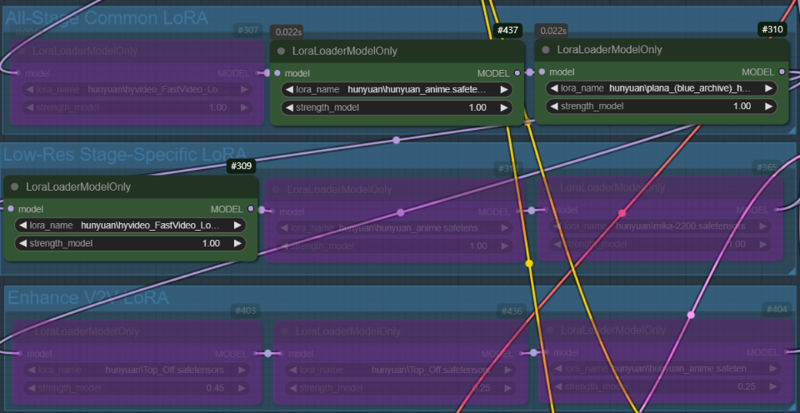
Case 2: All LoRAs used in Case 1 are applied across all nodes
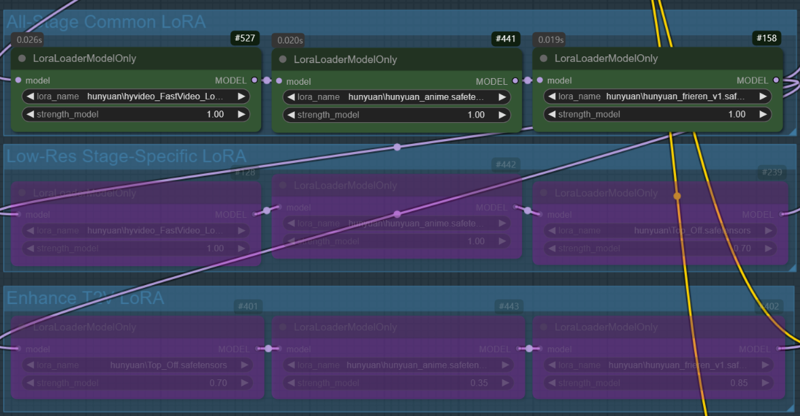

V2V Generation Example:
Same prompt, same seed, and all settings fixed
In the V2V example, the video created in the T2V stage will be used. (case.1)
Case 1: A character LoRA is used across all nodes, while Fast LoRA and style LoRA are applied only in the low-res stage. In the enhance V2V stage, the style LoRA used in low-res are applied with reduced weights(1->0.25).
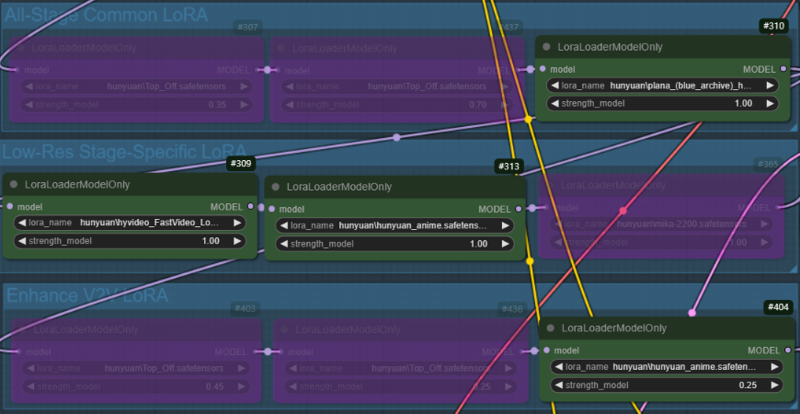

Case 2: Same as Case 1, but the weight of the style LoRA is fixed at 1.0.