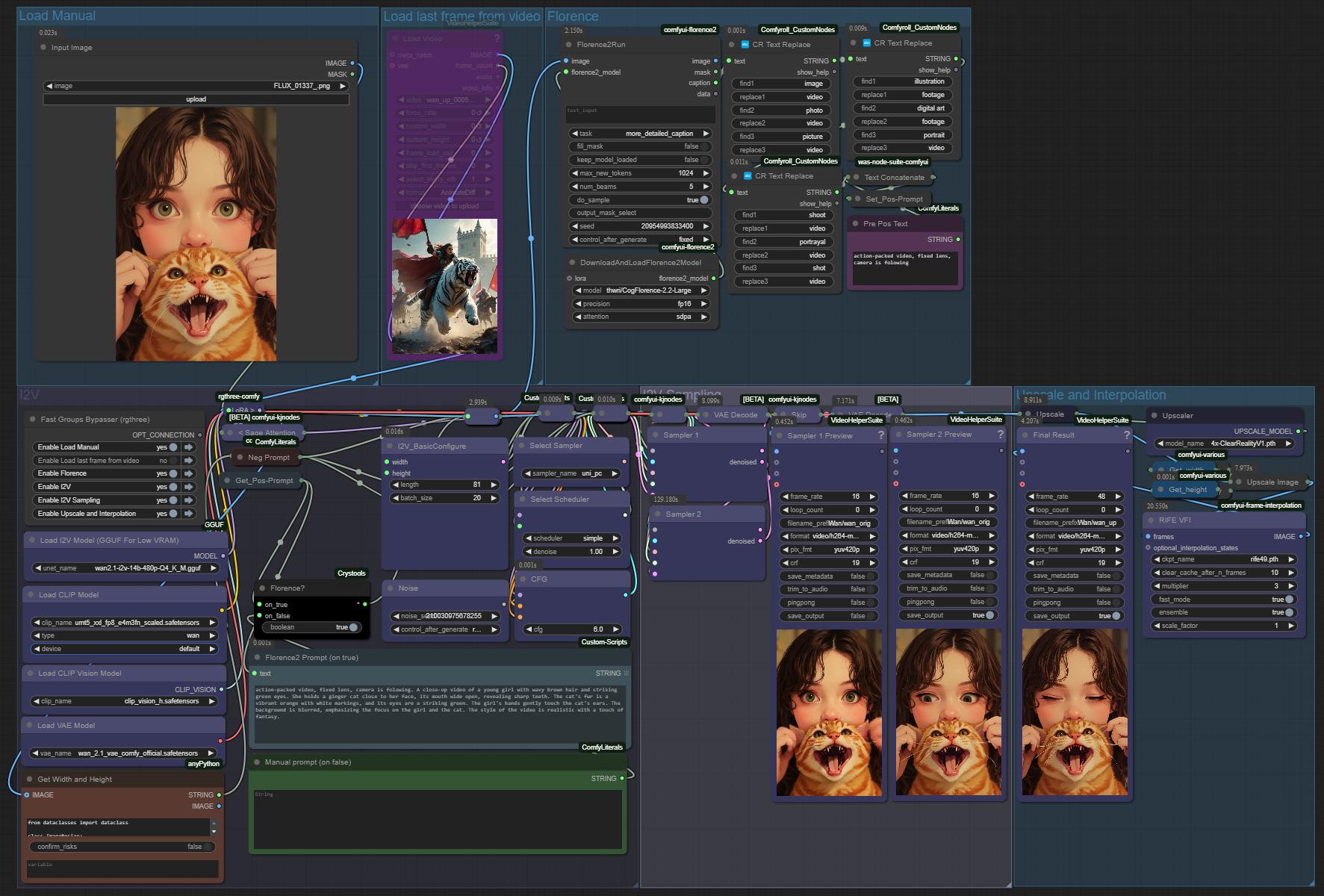
Wan Video Image To Video workflow + upscaler + interpolation + Florence2

詳細
ファイルをダウンロード
このバージョンについて
モデル説明
v1.0用
v2.0用
I2V Quantモデル -> models/diffusion_models
CLIP VISION -> models/clip_vision
VAE -> models/vae
プロンプトはFlorence2 LLMを使用できます(ワークフローにはFlorence2と手動ユーザープロンプトの切り替えオプションがあります)。
4080 16GBでテスト済み
v2.0は開発中です。AnyPythonノードで問題が発生した場合、ComfyUI/Custom_nodes/ComfyUI-Manager/config.json内のチャネルを「recent」に切り替え、またはsecurity_levelを(normal- または weak)に下げてください。
このモデルで生成された画像
画像が見つかりません。