WAN 2.1 IMAGE to VIDEO with Caption and Postprocessing

Details
Download Files (1)
About this version
Model description
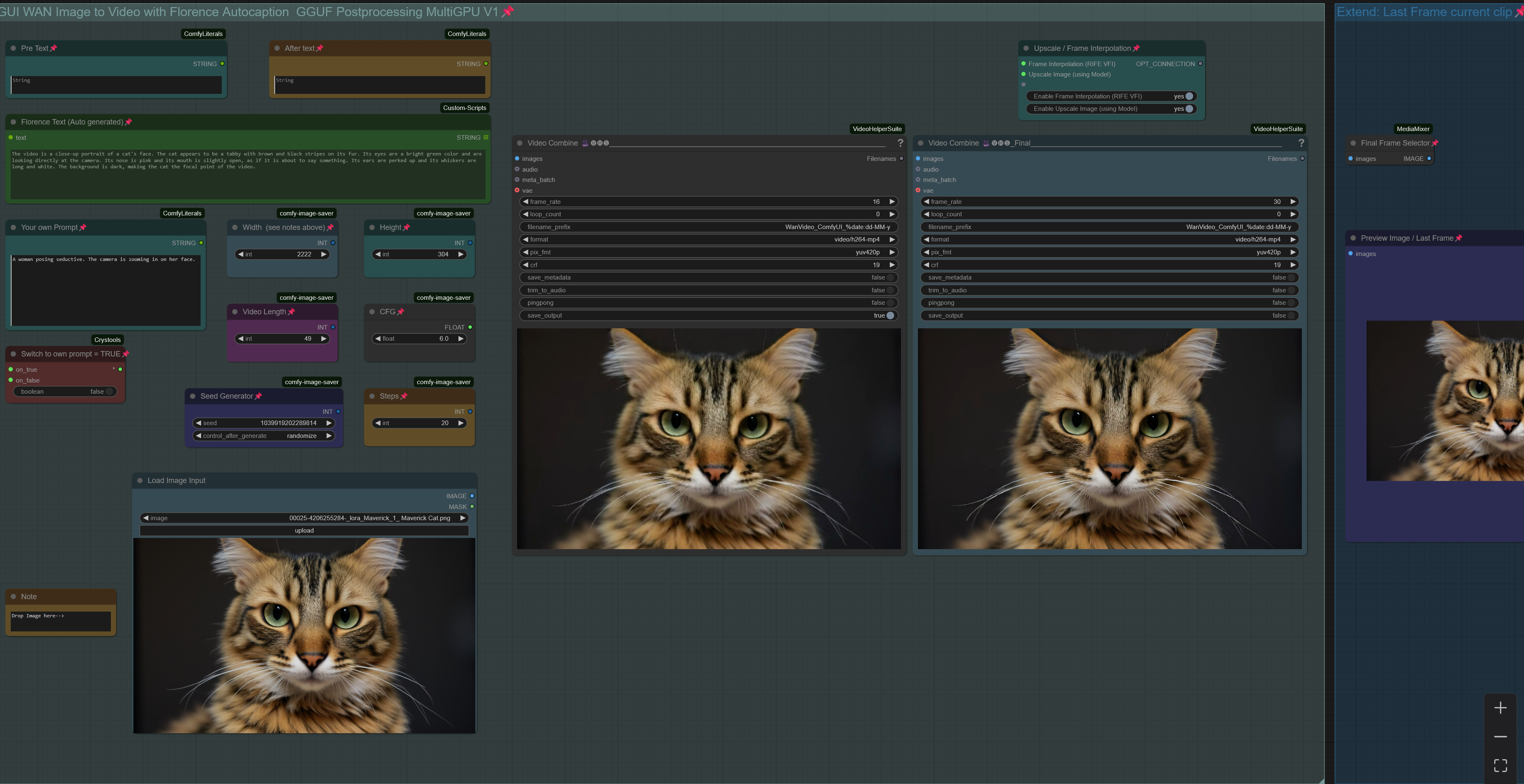
Workflow: Image -> Autocaption (Prompt) -> WAN I2V with Upscale and Frame Interpolation and Video Extension
Creates Video Clips with up to 480p resoltion (720p with corresponding model)
There is a Florence Caption Version and a LTX Prompt Enhancer (LTXPE) version. LTXPE is more heavy on VRAM
LTX Prompt Enhancer (LTXPE) might have issues with latest Comfy and Lightricks update
MultiClip: Wan 2.1. I2V Version supporting Fusion X Lora to create clips with 8 steps and extend up to 3 times, see examples posted with 15-20sec of length.
Workflow will create a clip on Input Image and extends it with up to 3 clips/sequences. It uses a colormatch feature to ensure consistency in color and light in most cases. See the notes in worflow with full details.
There is a normal version which allows to use own prompts and a version using LTXPE for autoprompting. Normal version works well for specific or NSFW clips with Loras and the LTXPE is made to just drop an image, set width/height and hit run. The clips are combined to one full video at the end.
update 16th of July 2025: A new Lora "LightX2v"has been released as an alternative to Fusion X Lora. To use, switch Lora in black "Lora Loader" node. It can create great motion with only 4-6 steps. : https://huggingface.co/lightx2v/Wan2.1-I2V-14B-480P-StepDistill-CfgDistill-Lightx2v/tree/main/loras
More info/tips & help: https://civitai.com/models/1309065/wan-21-image-to-video-with-caption-and-postprocessing?dialog=commentThread&commentId=869306
V3.1: Wan 2.1. I2V Version supporting Fusion X Lora for fast processing
Fusion X Lora: process the video with just 8 Steps (or lower, see notes in workflow). It does not have the issues like the CausVid Lora from V3.0 and does not require a color match correction.
Fusion X Lora can be downloaded here: https://civitai.com/models/1678575?modelVersionId=1900322 (i2V)
V3.0: Wan 2.1. I2V Version supporting Optimal Steps Scheduler (OSS) and CausVid Lora
OSS is a newer comfy core node to allow lower no. of steps with a boost in quality. Instead of using 50+ steps you can receive same result with like 24 steps. https://github.com/bebebe666/OptimalSteps
CausVid uses a Lora to process the video with just 8-10 steps, it is fast at a lower quality. It contains a Color Match option in postprocessing to cope with the increased saturation, the lora is introducing. Lora can be downloaded here: https://huggingface.co/Kijai/WanVideo_comfy/tree/main
(Wan21_CausVid_14B_T2V_lora_rank32.safetensors)
Both have a version with FLorence or LTX Prompt Enhancer (LTXPE) for Caption, can use Loras and have Teacache included.
V2.5: Wan 2.1. Image to Video with Lora Support and Skip Layer Guidance (improves motion)
There are 2 version, Standard with Teacache, Florence caption, upscale, frame interp. etc. plus a version with LTX Prompt Enhancer as an additional captioning tool (see notes for more info, requires custom nodes: https://github.com/Lightricks/ComfyUI-LTXVideo).
For Lora use, recommend to switch to own prompt with Lora trigger phrase, complex prompts might confuse some Loras.
V2.0: Wan 2.1. Image to Video with Teacache support for GGUF model, speeds up generation by 30-40%
It will render the first steps with normal speed, remaining steps with higher speed. There is a minor impact on quality with more complex motion. You can bypass the Teacache node with Strg-B
Example clips with workflow in Metadata: https://civitai.com/posts/13777557
Info and help with Teacache: https://civitai.com/models/1309065/wan-21-image-to-video-with-caption-and-postprocessing?dialog=commentThread&commentId=724665
V1.0: WAN 2.1. Image to Video with Florence caption or own prompt plus upscale, frame interpolation and clip extend.
Workflow is setup to use a GGUF model.
When generating a Clip you can chose to apply upscaling and/or frame interpolation. Upscale factor depends on upscale model used (2x or 4x, see "load upscale model" node). Frame Interpolation is set to increase frame rate from 16fps (model standard) to 32fps. Result will be shown in "Video Combine Final" node on the right, while the left node shows the unprocessed clip.
Recommend to "Toggle Link visibility" to hide the cables.
Models can be downloaded here:
Wan 2.1. I2V (480p): https://huggingface.co/city96/Wan2.1-I2V-14B-480P-gguf/tree/main
Clip (fp8): https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/text_encoders
Clip Vision: https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/clip_vision
VAE: https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/vae
Wan 2.1. I2V (720p): https://huggingface.co/city96/Wan2.1-I2V-14B-720P-gguf/tree/main
Wan2.1. Text to Video (works): https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main
location to save those files within your Comfyui folder:
Wan GGUF Model -> models/unet
Textencoder -> models/clip
Clipvision -> models/clip_vision
Vae -> models/vae
Tips:
lower framerate in "Video combine Final" node from 30 to 24 to have a slow motion effect
You can use the Text to Video GGUF Model, it will work as well.
If video output shows strange artifacts on the very right side of a frame, try changing the parameter "divisible_by" in node "Define Width and Height" from 8 to 16, this might better latch on to the standard Wan resolution and avoid the artifacts.
see this thread if you face issues with LTX Prompt Enhancer: https://civitai.com/models/1823416?dialog=commentThread&commentId=955337
Last Frame: If you face issues finding the pack for that node: https://github.com/DoctorDiffusion/ComfyUI-MediaMixer
Full Video with Audio example: