kashima/鹿島 (Kantai Collection)





















詳細
ファイルをダウンロード
このバージョンについて
モデル説明
- Civitaiの利用規約により、一部の画像はアップロードできません。完全なプレビュー画像はHUGGINGFACEでご覧ください。
- このモデルには2つのファイルがあります。a1111のWebUI v1.6 またはそれより前のバージョンをご使用の場合、必ず両方を同時に使用してください!!!。WebUI v1.7以降をご使用の場合は、一般的なLoRAと同じようにsafetensorsファイルのみを使用してください。
- 削減されたキャラクタータグは、ツインテール、グレー髪、ウェーブ髪、青い目、胸、長い髪、帽子、大きな胸、ベレー帽です。キャラクターの主な特徴(例:髪の色)が安定しない場合、これらのタグをプロンプトに追加してください。
- ptファイルのおすすめの重みは0.7-1.1、LoRAの重みは0.5-0.85です。
- 画像は一部の固定プロンプトとデータセットに基づくクラスタリングプロンプトを使用して生成されました。ランダムなシードを使用しており、選択的かつ意図的な画像の抽出は行っていません。ここに表示されているものが、実際に得られる結果です。
- 衣装のための特別なトレーニングは行っていません。衣装に対応するプロンプトは、提供されたプレビューポストをご確認ください。
- このモデルは1266枚の画像でトレーニングされています。
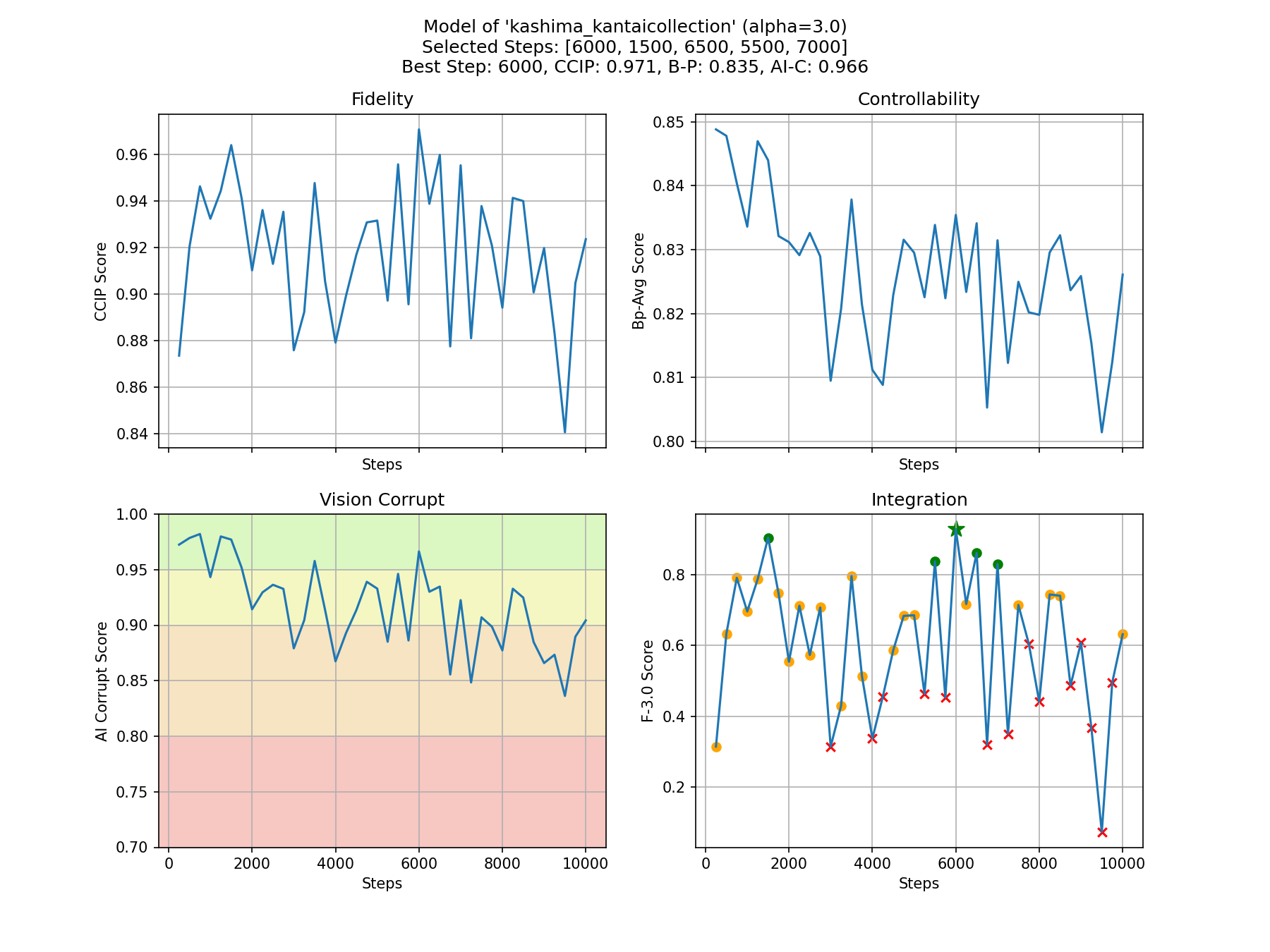
- モデルの忠実度と制御性のバランスを取るために、自動選択されたステップは6000です。すべてのステップの概要は以下の通りです。その他の推奨ステップについてはHuggingFaceリポジトリ - CyberHarem/kashima_kantaicollectionをご覧ください。
このモデルの使い方
このモデルには2つのファイルがあります。WebUI v1.6 またはそれより前のバージョンをご使用の場合は、これらを同時に使用する必要があります!!!。この場合、kashima_kantaicollection.pt と kashima_kantaicollection.safetensors の両方をダウンロードし、kashima_kantaicollection.pt を embeddings フォルダに配置し、同時に kashima_kantaicollection.safetensors をLoRAとして使用してください。WebUI v1.7以降をご使用の場合は、一般的なLoRAと同じようにsafetensorsファイルのみを使用してください。これは、埋め込みバンドルされたLoRA/Lycorisモデルが現在、a1111のWebUIで公式にサポートされているためです。詳細についてはこちらをご覧ください。
このモデルには2つのファイルがあります。WebUI v1.6 またはそれより前のバージョンをご使用の場合は、これらを同時に使用する必要があります!!!。この場合、kashima_kantaicollection.pt と kashima_kantaicollection.safetensors の両方をダウンロードし、kashima_kantaicollection.pt を embeddings フォルダに配置し、同時に kashima_kantaicollection.safetensors をLoRAとして使用してください。WebUI v1.7以降をご使用の場合は、一般的なLoRAと同じようにsafetensorsファイルのみを使用してください。これは、埋め込みバンドルされたLoRA/Lycorisモデルが現在、a1111のWebUIで公式にサポートされているためです。詳細についてはこちらをご覧ください。
トリガー語は kashima_kantaicollection で、削減されたタグは twintails, grey_hair, wavy_hair, blue_eyes, breasts, long_hair, hat, large_breasts, beret です。あるときキャラクターの特徴(例:髪の色)が安定しない場合、これらのタグをプロンプトに追加してください。
このモデルのトレーニング方法
- このモデルはHCP-Diffusionでトレーニングされています。
- 自動トレーニングフレームワークはDeepGHSチームが維持しています。
- トレーニングに使用されたベースモデルはdeepghs/animefull-latestです。
- トレーニングに使用されたデータセットは、CyberHarem/kashima_kantaicollectionの
stage3-p480-800で、1266枚の画像を含みます。 - バッチサイズは4、解像度は720x720、5つのクラスタにクラスタリングしています。
- 正則化データセットのバッチサイズは1、解像度は720x720、20のクラスタにクラスタリングしています。
- 10,000ステップトレーニングし、40のチェックポイントを保存して評価しました。
- モデルの忠実度と制御性のバランスを取るために、自動選択されたステップは6000です。
より詳しいトレーニング情報や推奨ステップについては、HuggingFaceリポジトリ - CyberHarem/kashima_kantaicollectionをご覧ください。
一部のプレビュー画像がキャラクターに似ていない理由
プレビュー画像で使用されたすべてのプロンプトテキスト(画像をクリックすると表示されます)は、トレーニングデータセットから抽出した特徴情報を基に、クラスタリングアルゴリズムによって自動生成されています。画像生成に使用されたシードもランダムに設定されており、画像には選択や修正は一切施されていません。そのため、このような問題が発生する可能性があります。
実際の使用では、内部テストに基づくと、このような問題が発生するモデルの多くは、プレビュー画像よりも実際の使用時に優れた結果を出します。あなたが行う必要があるのは、使用するタグを調整することだけです。
このモデルが過学習または未学習のように感じられる場合、どうすれば良いですか?
ここで表示されているステップは自動選択されたものです。他の推奨ステップも併せてご試用ください。こちらをクリックして、お好みのステップを選んでください。
当モデルはHuggingFaceリポジトリ - CyberHarem/kashima_kantaicollectionに公開されており、すべてのステップのモデルが保存されています。また、トレーニングデータセットはHuggingFaceデータセット - CyberHarem/kashima_kantaicollectionに公開されており、役立つ可能性があります。
なぜより良い画像だけを選んで使わないのですか?
このモデルのデータ収集からトレーニング、プレビュー画像の生成、公開に至るまで、すべてのプロセスは人間の介入なしに100%自動化されています。これは私たちのチームが行っている興味深い実験であり、その目的のためにデータフィルタリング、自動トレーニング、自動公開を含む一連のソフトウェアインフラを構築してきました。そのため、可能な限り、フィードバックやご提案をいただければ幸いです。これらは私たちにとって非常に貴重です。
なぜ希望するキャラクターの衣装が正確に生成できないのですか?
現在のトレーニングデータはさまざまな画像サイトから収集されており、完全な自動パイプラインでは、キャラクターがどの公式画像を持っているかを正確に予測するのが難しいです。そのため、衣装の生成はトレーニングデータセットのラベルに基づくクラスタリングを用いて、可能な限り最適な再現を目指しています。この課題については今後も改善を試みますが、完全に解決するのは困難です。衣装の再現精度は、手動でトレーニングされたモデルと比較して、おそらく劣るでしょう。
実際、このモデルの最大の強みは、キャラクター自身の内在的特徴を再現することと、より大規模なデータセットによる比較的優れた汎化能力です。そのため、このモデルは衣装の変更、ポーズの調整、そしてもちろんキャラクターのNSFW画像の生成に最適です!😉
以下のグループの方々には、このモデルの使用をお勧めできません。ご了承ください:
- キャラクターの元のデザインに対して、わずかな違いも許容できない方々。
- キャラクターの衣装再現に高い精度が求められる用途をお持ちの方々。
- Stable DiffusionアルゴリズムによるAI生成画像の潜在的なランダム性を受け入れられない方々。
- LoRAによるキャラクターモデルの完全自動トレーニングプロセスに不快感を覚える方々、またはキャラクターモデルのトレーニングは手動で行わなければキャラクターを軽視するものであると信じる方々。
- 生成された画像コンテンツが自身の価値観に反すると感じる方々。