Hunyuan I2V (Image to Video) - Simplest / 12Gb VRAM - Full HD

詳細
ファイルをダウンロード
このバージョンについて
モデル説明
以下に、Hunyuan I2V(画像から動画)のComfyUIワークフローの最もシンプルなバージョンを紹介します。初心者でも非常に理解しやすく学習しやすいです。
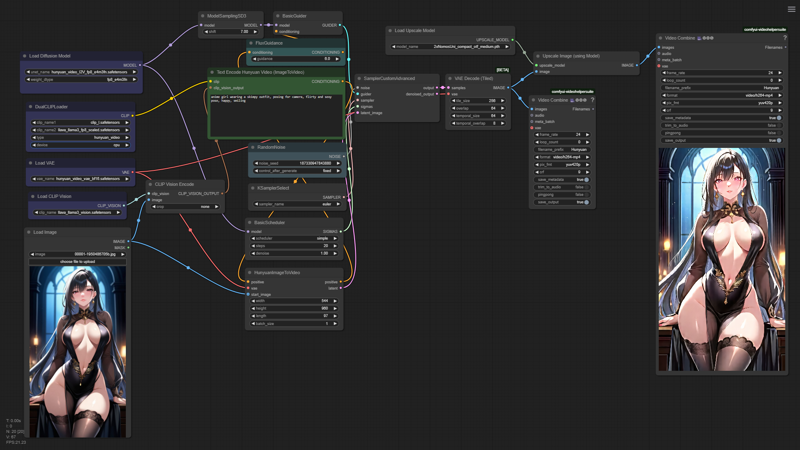 このワークフローは、オートプロンプティングやフレーム補間などの追加機能で拡張できますが、簡潔さと理解のしやすさを優先して、ここではそれらのノードは追加していません。
このワークフローは、オートプロンプティングやフレーム補間などの追加機能で拡張できますが、簡潔さと理解のしやすさを優先して、ここではそれらのノードは追加していません。
私の低VRAM(わずか12GB...)のテクニックは、生成される動画の初期解像度に隠されています(フルHDのちょうど半分:(1920/1088)/2 = 960/544)で、その後、低解像度の画像/動画を復元するように学習された2倍アップスケーリングモデルで拡大します。
これらのモデルの1つは以下で入手できます:https://openmodeldb.info/users/helaman — 私の場合は、これを利用しています:https://openmodeldb.info/models/2x-NomosUni-compact-otf-medium
また、ワークフローの一部をfp8_e4m3fn形式で実行しています。Kijaiが提供するHunyuan Videoの量子化バージョン(https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_I2V_fp8_e4m3fn.safetensors)を使用し、ComfyUIのコマンドラインに次の2つの追加スイッチを設定しています:--fp8_e4m3fn-unet --fp8_e4m3fn-text-enc。さらに、拡散モデルローダーの重みタイプをfp8_e4m3fnに設定し、DualClipLoaderノードの「高度なオプション」を有効にしてCPUに送信しています(GPUメモリではなく)。
出力ファイルについては、1088ピクセルから1080ピクセルへ切り抜いて、純粋な9:16アスペクト比にすると良いでしょう。横向きの動画が必要な場合は、対応するノードで数値を反転させるだけです ;)
免責事項:このワークフローは、以下の公式ComfyUIの例を改変したものです:https://comfyanonymous.github.io/ComfyUI_examples/hunyuan_video/
素晴らしい動画を作成するのに、よいLuckを!