80's porn centerfold

세부 정보
파일 다운로드 (1)
이 버전에 대해
모델 설명
Just a fun little lora experiment that I spent a bit too much time on. I trained this three times, which is crazy considering it was meant as a one and done dump. But I learned a good amount of information along the way.
Trained on 54 still images of porn centerfold models from the 1980s. Intent was to capture: 1. the general look of the women in that time period, and 2. lighting and feel of the video/photography used for porn magazines then.
For a quick side lora (or what intended to be quick) I think it does well enough.
Because of the still image use only, I've found that this lora does not play well with higher frame counts. 89 frames is the sweet spot. 121 will still have movement, but it will be diminished. 145 frames will almost always result in still images only. Don't waste your time.
Captioning was extremely simple:
A 1980's porn centerfold womanYou can basically prompt the above with some sort of generic pose and location and the lora will do a decent job of producing a woman with big hair (both on her head and down below).
Give it a try and have fun.
And for anyone who doesn't care about training data, then stop here.
V1 - Trained it with an aim of 1600 steps for 8 total epochs at learning rate (LR) of 8e5.
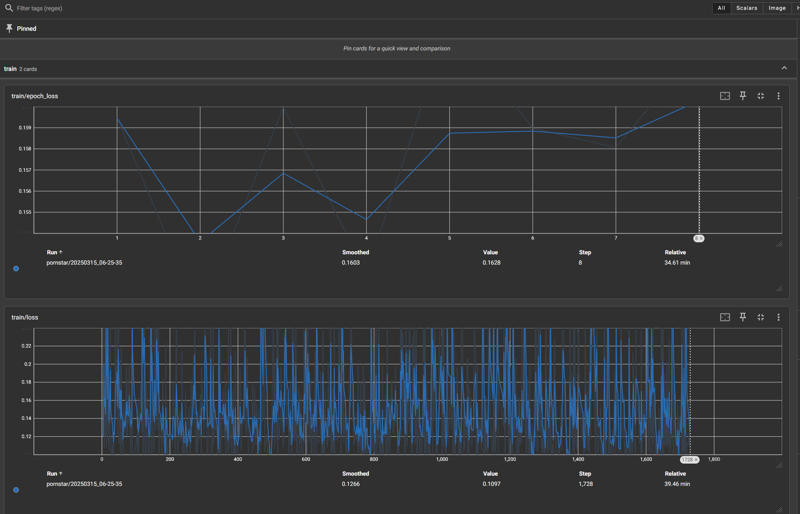
You can see by the loss graph that it hit steep decline by epoch 2 only to rise up and back down more slowly for epoch 4 before taking off and overfitting in epochs 5-8.
V2 - I immediately threw prior results out and trained for 10 Epochs at LR 7e5 instead to try to avoid overfitting the so quickly.
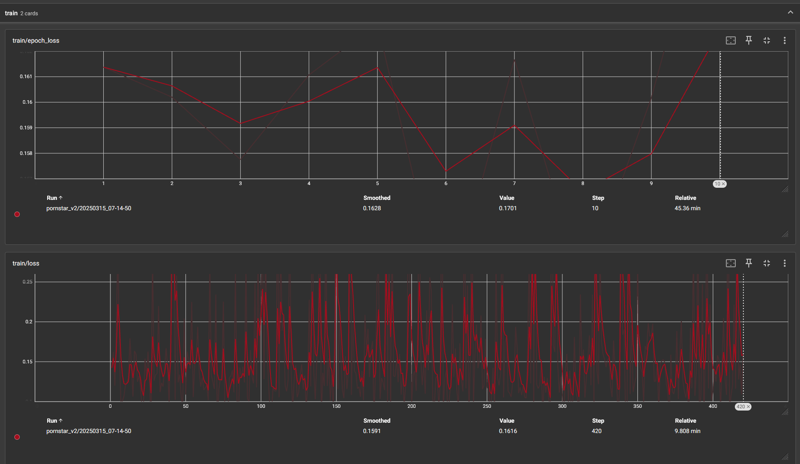 The lower LR seemed to work better, though the ramp down on epoch 6 was rather steep. It too was followed by a spike and then another dip before climbing steadily toward being overfit.
The lower LR seemed to work better, though the ramp down on epoch 6 was rather steep. It too was followed by a spike and then another dip before climbing steadily toward being overfit.
When testing between Epoch 6 and 8, Epoch 8 actually showed more adherence to prompts and general cohesion toward the premise trained without noticeable harm to motion. It was during these test inferences that I noticed the diminished motion at the higher frame counts.
V3 - As an experiment, I tried modifying captions to say "An image of..." at the beginning and then trained it on the exact same settings as before. I read on discord that this can sometimes help the model understand that the concepts are being trained off static images and thus avoid some of the fighting that an inherently overtrained lora can do against motion.
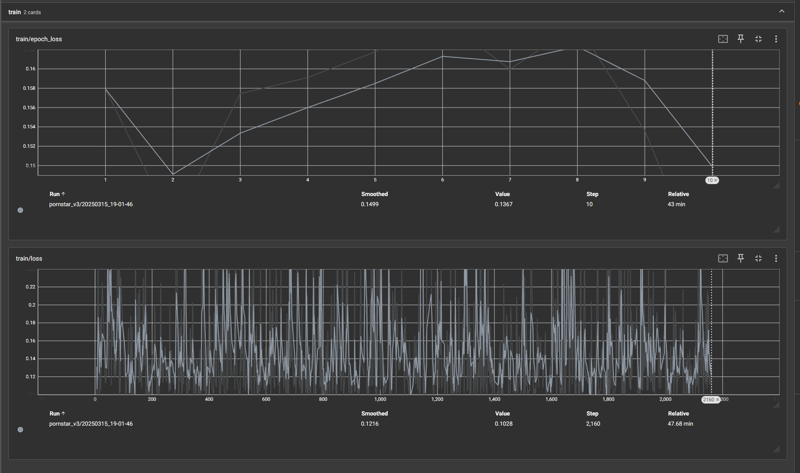 The downward fall was steady and quick for this followed by a slow and steady overtraining that then resulted in another long curve back down. After testing, the Epoch 2 and 10 loras that were trained were not coherent enough and resulted in far more artifacts than Epoch 8 under V2.
The downward fall was steady and quick for this followed by a slow and steady overtraining that then resulted in another long curve back down. After testing, the Epoch 2 and 10 loras that were trained were not coherent enough and resulted in far more artifacts than Epoch 8 under V2.
As a result, I have chosen Epoch 8 of V2 as the winner.
This does show the importance of captioning in lora training though, at least from my perspective. And there is something to be said about the use of "an image of" and "a video of" used in dual image/video datasets. Stand-alone for a single medium, it is probably not very needed.
Another take away for this is to not throw away epochs after a slight climb in the loss. Sometimes the epoch after can still be useful.
Ultimate take away is, if you see mid-training climb in loss, you may want to try lowering the LR to offset and help stabilize a bit.