Lab Index









Details
Download Files (1)
Model description
NOTICE
When doing showcase remix, REMEMBER to check :
base model : WAI-NSFW-illustrious-SDXL
base model's version : v11? or v12?
lora : leave only one, and check it's strength 0.7~0.9 (perhaps 0.8?)
In order to be compatible with WAI base mode's current generation version - v11.
Please use the specific lab LoRo 'for WAI v11 ...' for testing in Civit site generation
Introduction (介绍)
This series of LoRa Lab Tests are to compare the effects and differences of LoRa trained under different schemes.
Don't have too high expectations for them, but on the contrary, if you're interested, you can download the attached dataset and try it yourself. With the parameters below, except for the 24 images training, the training is rather easy and quick.
Followed are all the attempts of LoRa Lab ( Latest comes first )
本系列的 LoRa 是用于对比不同方案下训练出来的 LoRa 的效果和差异
不要对它们有太高预期, 但相反的, 如果你感兴趣, 可以下载附录的数据集自己尝试, 按照下面的参数, 除了 24 张的训练, 其他一次训练时间和成本都非常低
How things are organized? ( 本系列的资源如何整理? )
To make the overall structure clearer, we'll adjust it to the following format to organize the content related to this series of LoRa experiments, hoping to provide you with some help 😉
Each single LoRa traing will no longer be placed in a single Civit LoRa model, except for the first Test Suite. They will be organized under the Test Suite.
为了让整体更加清晰, 后续会调整为如下的结构, 对本系列 LoRa 实验的相关内容进行整理, 希望能为你提供一些帮助 😉
除了第一次的训练实验组, 以后各个单个的实验, 不会独立建立一个 Civit LoRa 模型, 而是会组织在某一次实验组 LoRa 模型下面.
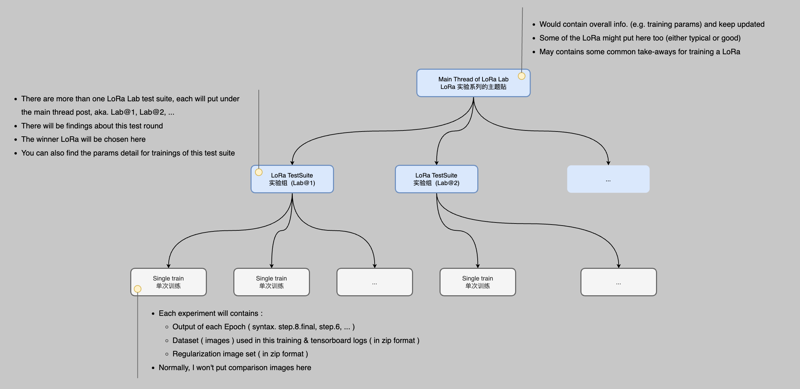
Followings are all the Test Suite so far ( latest comes first ). If you are interested in certain Test Suite, please visit it's page for my findings, dataset, reg images or training logs ( tenserboard ).
下面是所有进行过的 LoRa Lab 尝试 ( 倒序 ). 如果你对某个测试组感兴趣, 欢迎到它的介绍页面, 里面附带了我在训练时的一些想法和发现, 还有相关的数据集, 正则图片集, 还有训练日记 ( tenserboard )
Lab @7 - a tool to benchmarking tags over a ckpt model
link : https://civitai.com/models/1437262/lab-7-sex-position-posture-gesture-tags-benchmark-html-page
Lab @6 - old man girl ( character ? )
link : https://civitai.com/models/1402838?modelVersionId=1585736
Lab @5 - lift and show me ( concept )
link : https://civitai.com/models/1374843/lora-lab-5-concept-bdsm-skirt-lifting
Lab @ 4 - try less image to see if it works
link : https://civitai.com/models/1372924
Goal : as @3 shows, trigger token & tagged reg images did work. So, will it also do the trick on less dataset?
#1 : 8 pics; bad reg images (with lower body images, but tagged); trigger token : nsfwish, golden panyhose
BAD -- it kinda gives me lower body image even +full body is prompted
#2 : 8 pics; better reg images (tagged; but with some strange non-girl reg images -- 1girl, 1boy)
OK -- but images might lose some logical composition at complex prompt
#3 : 12 pics; better reg images (tagged; but with some strange non-girl reg images -- 1girl, 1boy)
OK, better than #2 -- but images still might lose some logical composition at complex prompt
#4 : on WAI v11 !! 12 pics; only full body reg images (tagged);
BETTER than #3 but on WAI v11 -- only problem is "black sheer pantyhose could shows"
#5 : back on WAI v12!! 12 pics; only full body reg images (tagged);
findings :
GOOD on WAI v12 !! but JUST OK on WAI v11
also, #4 is good on v11, but just ok on WAI v12 ( it seems compatibility is a thing )
#6 : 12 pics; full body reg images; trigger token : nsfwish, sheer golden pantyhose
< testing >
Lab @ 4 -- Findings
Interestingly, less dataset still gives promising result
AND trigger token & proper reg images with tags DID help
and this is really great finding, as dataset experiments can really SPEED UP without a full dataset test run !!
HOWEVER, the trigger word
sheer golden pantyhoseseems to also afffect other part of the image, e.g. the tone, the hair, shoes, ...Next time could try some trigger token which is color neutral one
LoRa trained on different base model (v11, v12), works better on their own base model
WAI v12 is actually better than v11, indeed
v11 still tends to give me lower body, when
1girl, solo, pantyhoseis given
Lab @ 3 - try trigger token & tagged reg images
< to be updated >
Goal : try to fix the dataset and reg image set problem and re-train a better LoRa
Try the following approaches in order to fix LoRa Lab @1 's p24 wr problem.
#1 - removes all the lower body image from the reg images and train ( STOP in the middle for tagging and remove some dataset image )
#2 - removes all lower body reg images; tags the reg images; add 5 pics about "2 people" to the dataset and some related reg images. ( Quality seems bad )
#3 - Keep only the girls dataset and reg images, but removes all lower body reg images; tags the reg images; ( Quality seems ok, but the target effects aren't controllable )
#4 - Keep only the girls dataset and reg images, but removes all lower body reg images; tags the reg images; Add trigger token
sheer golden pantyhoseto all the dataset captions; ( Quality improved, the trigger token seems to help AI learn. And this version is acceptable for now )
Conclusion : OK, but there's something to improve and learn.
Lab @ 2 - try train on merged ckpt
< to be updated >
Goal : try to tune an existing LoRa, to make it better ( fixing the image composition problem )
#1 : merge p24 wr to WAI v12; train 8 pics; ( Bad quality )
#2 : merge; train 8 pics (3: 1girl, 5: girl-and-boy) with reg images (all: girls) of no tag; ( Slightly better quality, but still unacceptable )
#3 : merge; train 8 pics (3: 1girl, 5: girl-and-boy) with reg images (all: girls) of auto tags; ( Again slightly better quality, but still, unacceptable )
#4 : merge; train 8 pics (3: 1girl, 5: girl-and-boy) with reg images (girls & girl-and-boys) of auto tags; ( Even better quality, but still, it does not reach my expectation )
Conclusion : FAILED
Lab @ 1 - try different size of dataset & w/wo reg
https://civitai.com/models/1362442
Goal : better pantyhose, see-through, maturity
Try the following approaches to see how the trained "nsfw stylized (pantyhose & see-through)" LoRa feels and what the differences are:
1 image, no regularization (p1_wor) : https://civitai.com/models/1360124
1 image, with regularization (p1_wr) : https://civitai.com/models/1360141
3 images, no regularization (p3_wor) : https://civitai.com/models/1360163
3 images, with regularization (p3_wr) : https://civitai.com/models/1360171
8 images, no regularization (p8_wor) : https://civitai.com/models/1360183
8 images, with regularization (p8_wr) : https://civitai.com/models/1360189
24 images, no regularization (p24_wor) : https://civitai.com/models/1360230
24 images, with regularization (p24_wr) : https://civitai.com/models/1360268
This time captions are directly derived using WD14 Conv v2 tagger, without any additions or deletions
Conclusion : PARTIAL SUCCESS - not that good, but I have done the dataset preparation and some different LoRa to compare with
尝试一下如下的方案, 所训练出来的 "nsfw 风格化 (pantyhose & see-through)" 的 LoRa 感觉如何, 各自有何差别 :
1 张图片, 无正则化 (p1_wor) : https://civitai.com/models/1360124
1 张图片, 有正则化 (p1_wr) : https://civitai.com/models/1360141
3 张图片, 无正则化 (p3_wor) : https://civitai.com/models/1360163
3 张图片, 有正则化 (p3_wr) : https://civitai.com/models/1360171
8 张图片, 无正则化 (p8_wor) : https://civitai.com/models/1360183
8 张图片, 有正则化 (p8_wr) : https://civitai.com/models/1360189
24 张图片, 无正则化 (p24_wor) : https://civitai.com/models/1360230
24 张图片, 有正则化 (p24_wr) : https://civitai.com/models/1360268
本次 captions 尝试直接用 WD14 Conv v2 tagger 推导, 无任何的增删