Omega Distilled V3 - BeatriXL-O Preview





















세부 정보
파일 다운로드 (1)
모델 설명
WARNING: This is a HIGHLY EXPERIMENTAL UNCENSORED MODEL
It will produce smut on the drop of a hat. It will produce gross scenes. It will produce things you don't want to see. It's too smart for it's own good and too dumb to know it...
It will also produce some of the most magnificent scenes, with the most beautiful scenery, the most powerful images, and the most heart provoking majesty you've ever seen...
Breathtaking, and horrifying. You are warned.
With the release of BeatriXL, you will see a superior model to the experts in the other category. It's capable of most of what all of those models can do with additional capability on every front.
Update 13; BeatriXLO-V4 BeatriXLO-V3.
I regret to inform you, that the powerhouse forming as BeatriXLO-V4 - had some unintended behavioral side-effects to it's new finetune. The outcomes of those behaviors produced images in photorealistic formats that are not acceptable - and the model weights cannot be distributed.
It's a big loss, due to the manifested intelligence and power that this model has produced in the very same finetune. It's a tragedy to say the least, and the loss will not be salvageable for weeks until I complete my LOBA training tool's baseline form and produce correct reformed behaviors within the model.
The target culprit data that caused this behavior to manifest; was a combination of COCO, IMDB, and object association datasets selected to introduce additional behavioral object association and depiction control data.
In my rush, I was not careful enough in curating certain datas from the list, causing the inevitable introduction of age inappropriate data that completely overrode the "AGE BOMB" destruction that I so vigilantly planted into the system.
This cost nearly 2 weeks of l40s time, and the finetune was nearing completion; which means I don't do this lightly. I do this because I have to.
 I'm sorry... little one... I'll repair you when the LOBA trainer is ready...
I'm sorry... little one... I'll repair you when the LOBA trainer is ready...
Update 12; BeatriXLO-V3.
This finetune is heavily based on object orientation and integrating new methodologies to blend images. It consists of 8 object orientation datasets including a series of grid and realistic characters, settings, and scenes to help solidify the context of situations
It may lose some of what BeatriXL has, because it's a different kind of merge fusion that will perform different high-context tasks with a slightly less human fixation with the attribution of additional scene and context. It's still VERY human heavy, so beware simple prompts. I'm devising a way to bake them into a more permanent text embedding state. So stay tuned for that fix, when I finetune this beast into a permanent state similar to this.
This is a very very powerful workflow is available for playing.
The model weights and lora are available on huggingface - and the lora is still cooking, so you can grab epoch 2 as of right now, or just wait for better.
https://huggingface.co/AbstractPhil/TEST_LORAS/blob/main/BeatriXLO-REAL-fp32.safetensors
This requires both to get the full effect.
It includes multiple assessed and defined laion flavors to eliminate or negative behaviors, while introducing a large series of potential negatives that could be in any model.
There are sliders available for the multiprompt system, where you slide ratio from one type to another.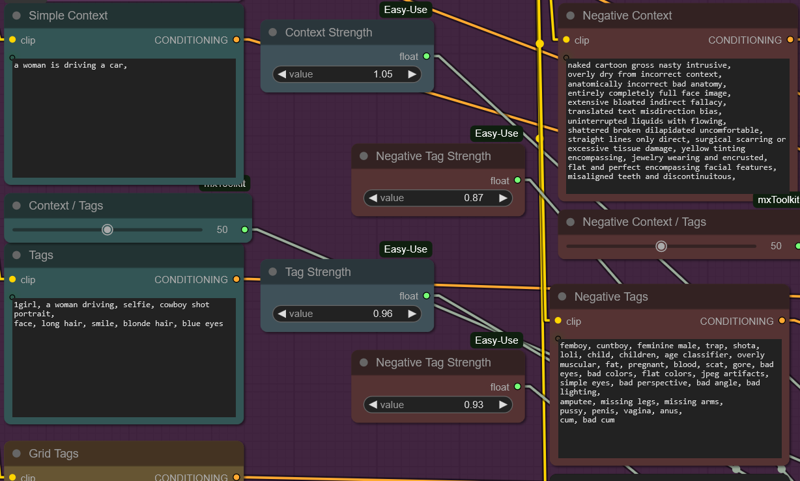 Highly potent for the utilization of multi-prompt positive and negatives. They help eliminate large amounts of unwanted information, while introducing nearly Flux-grade positive context in BeatriXLO-Real's new finetune object orientation finetune.
Highly potent for the utilization of multi-prompt positive and negatives. They help eliminate large amounts of unwanted information, while introducing nearly Flux-grade positive context in BeatriXLO-Real's new finetune object orientation finetune.
Update 11; loras, loras, loras.
Apparently... Like everything I tried works. So it clearly did it's job.
Have fun everyone. If it's SDXL, this thing can probably use it's lora or merge with it.
Update 10; BeatriXL doesn't work well with forge
It's much more effective to set up a simple ComfyUI system with res4lyf.
I'll prepare a simple workflow and a complex workflow to enable this model's full behavioral array.
Update 9 ; BeatriXL release
BeatriXL is a V-PRED (velocity prediction) based SDXL distillation. This model was distilled using feature interpolation using it's parent model; Beatrix.
Being V-PRED, you must generate using V-PRED, otherwise it will not generate images correctly. It may generate something on epsilon, but I doubt you'll see much.
UNLIKE OMEGA V0001;
This generates better with KARRAS noise.
I recommend starting around;
[ EULER_A, RES_2S ] << txt2img [ EULER_A, RES_2S, RES MULTISTEP ] < img2img [ LCM, DEIS ] < hit or miss both[ SGM UNIFORM ] << anime [ NORMAL / SIMPLE ] << good [ KARRAS, EXPONENTIAL ] << best [ DDIM_UNIFORM ] << img2img
8 to 50 steps 1024x1024 / 1216x1216
The majority of the showcase images were generated using 8 steps 5 cfg 1216x1216 with simple prompts.
You won’t get very good results with DPP_2M_SDE with this one. However, using DPP_2S and RES_2S_SDE give fairly good results in comparison.
Positive Prompt; masterpiece, most aesthetic, very aesethetic, <art_type> <number>people/no people,# swap <number>girls/<number>boys, # swap <caption where people are doing things> <caption where architecture exists in a way around them>
highres, absurdres, <year of artstyle>
Negative prompt;
lowres, low quality, nsfw,
blurry,
displeasing, very displeasing, disgusting,
<describe things you don’t want to see in plain english>
<additional tags here>
Grid tags can be added as plain words in both positive or negative prompt. They are quite powerful at both adding or removing details.
grid_a1 person with red hair and blue shoes, grid_c4 hand grabbing a bagel, etc.
Assign the people traits, and control them through captions. BeatriXL does okay with it, but it’s not going to be perfect. There’s only so many captions that can be learned with my data.
I’ve sourced an additional 250,000 safe real images from all walks of life such as; architecture to augment the 3d environments, plant life to augment the plants, animal life to restore broken animal life, cinematic scenes of high fidelity, ruins for the traditional feeling, opulence for the opulent feel, fashion scenes for additional clothing traits, sexual positioning and poses to better conform the more depraved so it doesn’t accidently use it in other contexts, additional identified ONNX world objects to associate the grid with additional details and depictions, and many more.
These have been captioning carefully using GPT4o, LLAVA LLAMA, and using the T5 with BLIP and clip interrogator, and then passing through the visual identification suite. The process is slow, but it’s going to be worth it for version 3 when I introduce a huge amount of LAION back into the mix for reaffirmation training, using new captions.
On top of that, the clip-suite will assist with debugging and testing clips without needing quirky program mixes. It’ll let me just swap things around on the pod and throw them into my comfyui workflow for immediate testing and debugging, which will save a lot of time on model moving and a lot of headaches.
If you’re curious what it does, it does everything. If you can’t figure out how, then fiddle with the settings until it conforms. Eventually it’ll work. It knows far more than it should and has the details to support them.
BeatriXL is likely less reliable than the original Omega V0001 for immediate and personal images on the direct scale, and it likely will take longer to generate. However, the scene and environment flexibility is far more vast on many fronts; including liminal, architecture, objects, lighting, and many more details that Omega simply lacked. BeatriXL conforms far better to angles, offsets, depths, rotation, and many more camera angles, depths, and associations.
It lost much of the Omega model’s immediate fidelity control capability for high-fidelity images, which is one of the reasons why I have been putting off releasing it. I’ve been targeting ways to improve this process so the outcome isn’t so… unreliable.
There is no lora. The lora is 11x this model’s size. The true form of this model is… uhh… well, different. A larger version of FLUX and SD35-L, and it takes nearly 2 minutes to generate one image on 2 a100s.
I condensed it to something… manageable. It wasn’t easy though.
Suffice it to say, it’ll behave similarly to Omega; as it’s based on the same process, it just has many more features, and was based on 0001; so it should behave quite similarly to 0001, but it’s not the same model.
You’ll see almost immediately how unstable it can be, and how stable it can be. It requires… The math estimates nearly 140,000,000 samples to solidify into the full absolutely unchained and stable artistic-controlled grid-depiction master state, which it does not have the image training for.
However, SD3.5M is showing some of those same strengths with almost no training on the T5XXL UNCHAINED; which is going to be the next version of Omega’s distillation process. Training the T5XXL UNCHAINED to be… a linear interpolation machine, so the finetuning will take less time and the conformity will be more accurate.
Update 8
So, it looks like by training early steps with mannequin bodies, the experts all conformed exactly as expected.
Less steps for simplified complexity, and more steps for absolute complexity.
8 steps is all you need at cfg 5 in euler A with beta noise.
Beta noise being the type of noise intentionally kept CONSTANT through the entire training system.
Using Beta noise, is a way to access those early learnings in a careful way without destroying all of the expert information stacked on top.
So… you don’t need a big complex prompt to have yourself a complex image. You also don’t need a big complex set of numbers, just the standard 8-20 steps similar to SDXL lightning but not quite tuned in the same way.
This distillation does not conform to the SDXL Lightning dichotomy, so don’t expect to get the same sort of results merging those models with this one. This is an SDXL base 1.0 model offshoot, and does not conform to SDXL lightning nor it’s differences.
Update 7
It hit 12/15 canary prompts at full accuracy. We have a B student; 80% or higher capacity reached. This has the context potential of 80% of standard SDXL… and it’s distilled.
Wew… yeah I didn’t think, the distilled one would even work, let alone be this good looking with only a handful of finetune steps.
On top of that, it seems to work with all the loras I tried. I didn’t think it would work so well with standard samplers and noise.
Update 6
I’m going to do something I don’t usually do; which is show the true power of one of these models.
They are capable of everything. Literally everything. This one is going to slam shut a bunch of doors on a lot of opinions.
Heathen hours time.
Before you ask yourself; oh what can it do?
Well… this thing is… uhhh… too smart. Like I said.
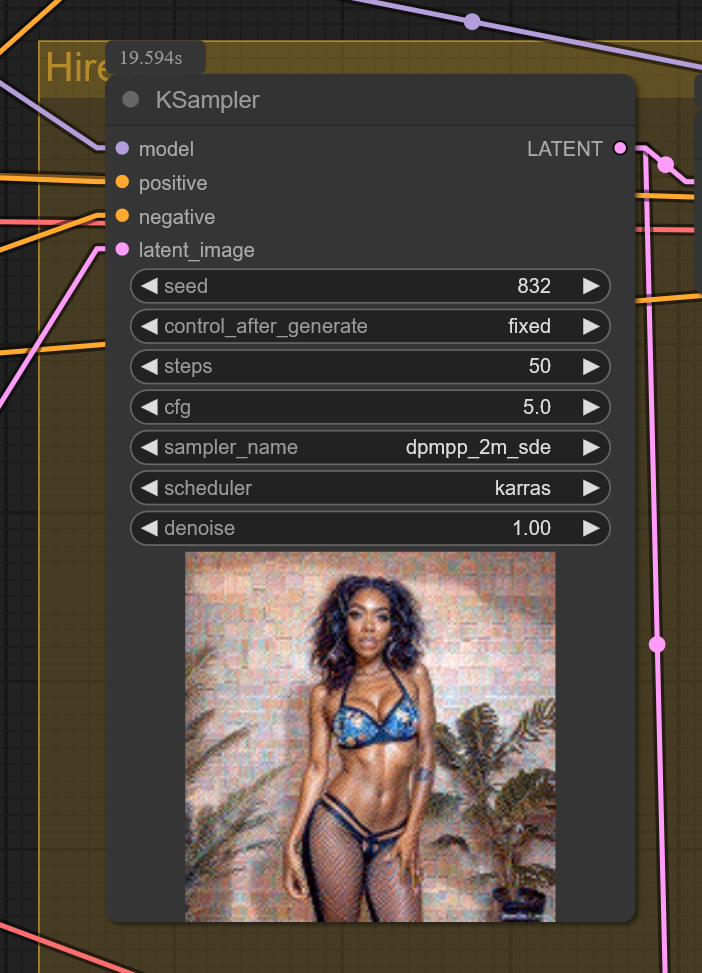
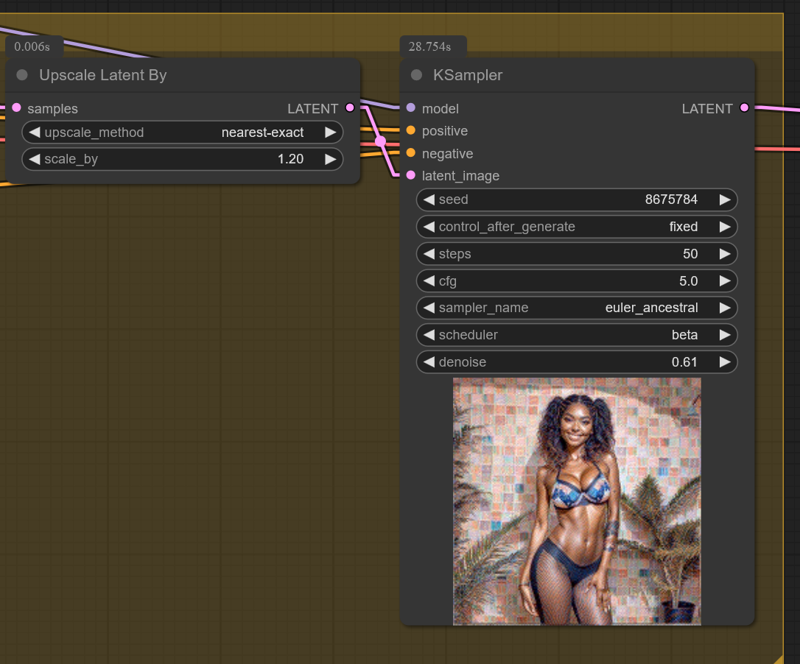
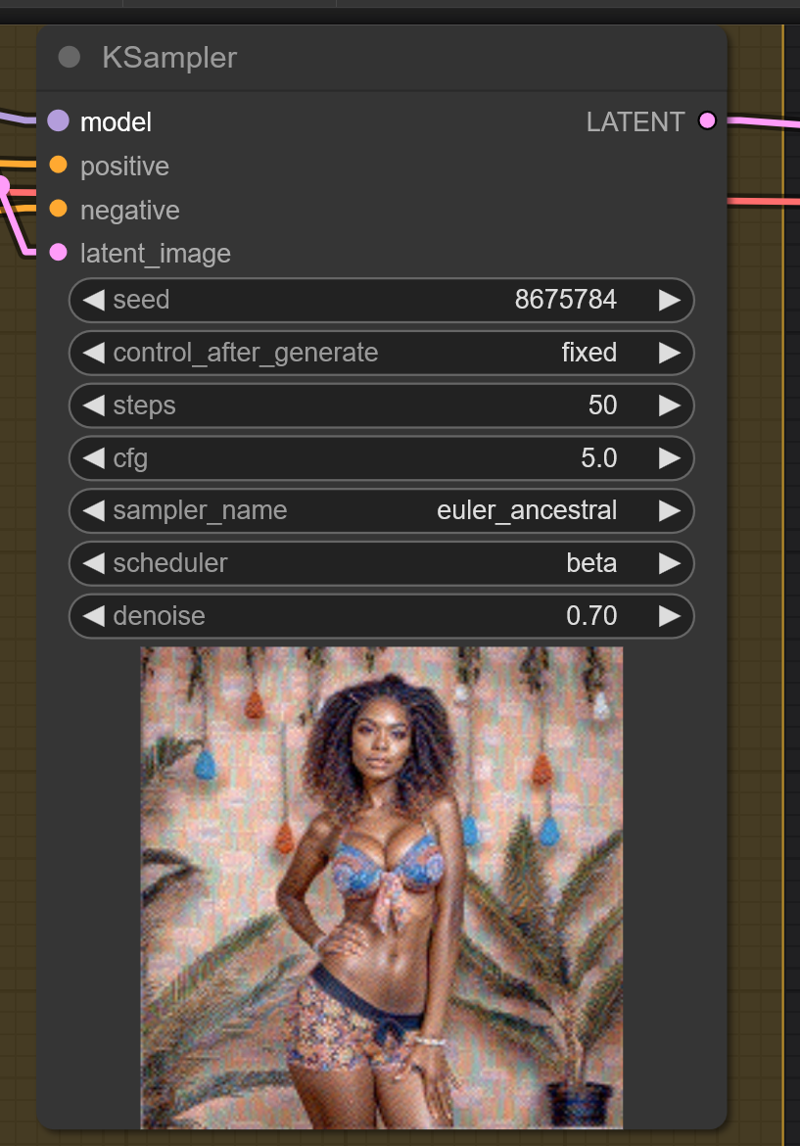
Update 4
Don’t train the clips. They are so powerful and this thing is so close to being something truly awe inspiring, that all it needs is the UNET for a while.
Negative Prompt:
disgusting, very displeasing, displeasing, bad anatomy,
score_1, score_2, score_3,
anthro, furry, semi-anthro, bad edit,
jpeg artifacts, ugly man, guro, mutation, tentacles,
monochrome, greyscale,
lowres, text
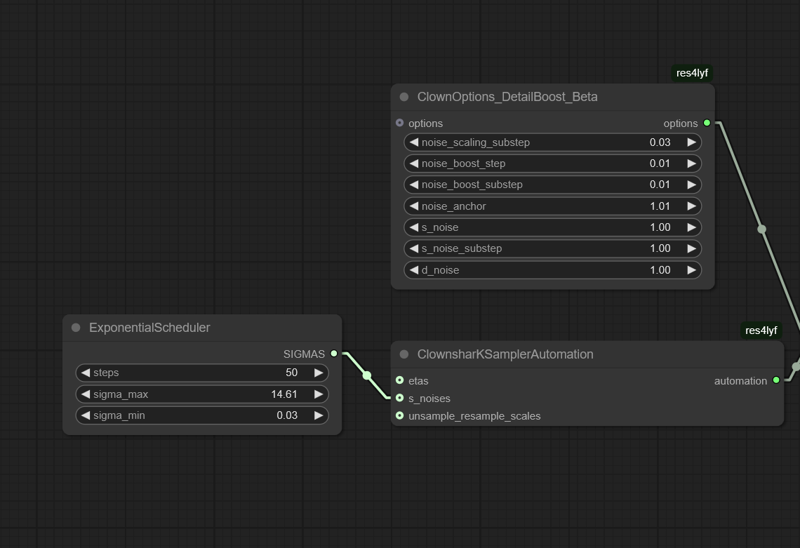 This is as close to the math as I can get currently without completely gutting it.
This is as close to the math as I can get currently without completely gutting it.
Update 3
Safe finetunes are failing. I’m going to give it a mil images and see if it becomes more compliant.
Update 2
More Realism
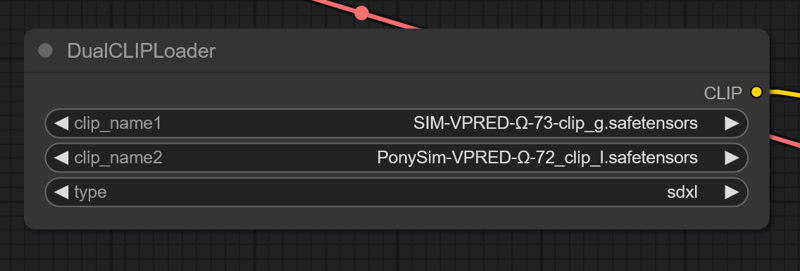 Due to the PonySim’s original having such good attunement to realism, you can use the original PonySim’s CLIP_L to really make this model’s realism cut through.
Due to the PonySim’s original having such good attunement to realism, you can use the original PonySim’s CLIP_L to really make this model’s realism cut through.
More Anime
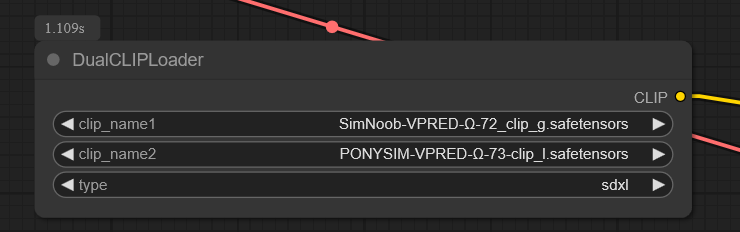
Update 1 LORA experiments
The model was trained with HIGH timesteps and LOW timesteps omitted from the trains; from all experts.
There is no exceptions to this rule. This enables loras to work.
MANY loras are trained with step 0 to 1000 in mind; completely disregarding the IMG2IMG traits of a model.
This model was trained between lowest 50 and 950 at most; mostly between 200 and 800.
The byproduct being MANY loras work from many models;
Illustrious, Pony, Noob, and SDXL loras.
You will NOT get the exact same results, so don’t expect them to be exact, but you can definitely prompt many elements that otherwise do not exist in this model.
“Whoever fights monsters should see to it that in the process he does not become a monster. And if you gaze long enough into an abyss, the abyss will gaze back into you.”
Friedrich Nietzsche
If the world cannot exist without both good and evil; then why does the AI the world creates exist without either?
The answer… Maybe someday.
The first of it’s kind; a cross-trained VPRED merge.
Recommended size:
>1216x1216
Handles images up to 1742x1742
Recommended sampler:
Upscale from 1216 or 1472 * 1.10 >
First Sampler; DPMPP SDE GPU
Handles both incredibly high and incredibly low cfg.
Handles LCM; which means interpolative video is possible.
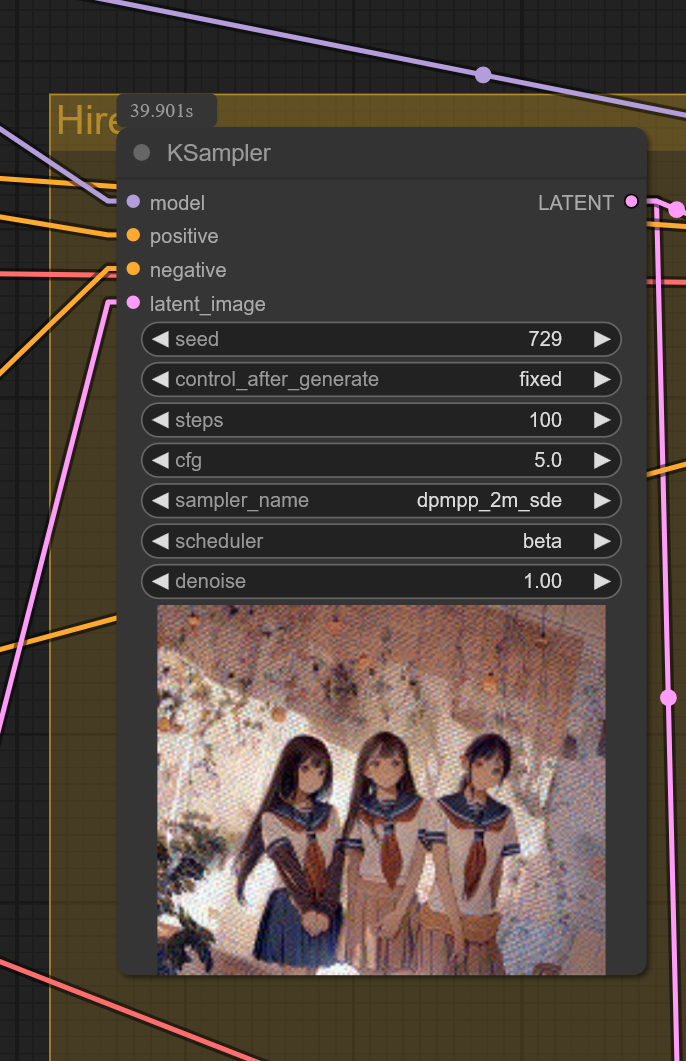
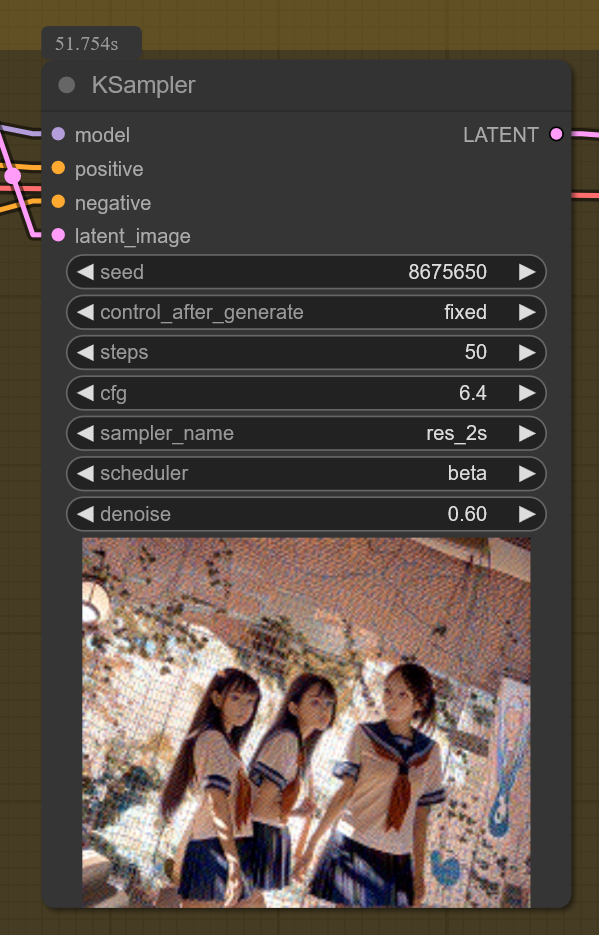
score_9, score_8, score_7, score_6, real, neutral lighting, 3girls, standing, side-by-side,
school uniform, trio,
masterpiece, best quality, newest, very awa,
It is essentially all four models in one.
This one’s foundation is PonySim -> VPRED, so if you go drag the differences out; you’ll find quite a bit of PonySim-VPRED.
However, no matter what with this interpolation distillation; it needs a base. This one is based on Pony. The others may or may not be based on pony. They may be based on a ZERO’d model, or something else, or maybe a full trained model from scratch; hard to say today.
HENCE why it’s labeled a merge; it IS a merge! Doesn’t matter how many finetunes I did, the final product is a MERGE! No matter the complexity.
You will MOST DEFINITELY see some growing pains.
However, this is the first of it’s kind.
Each from a finetune using very similar data, the most powerful of the UNETs feature distilled together with the most potent of the CLIPS merged using comfy.
The pack concatenated and packed using the ComfyUI VPRED checkpoint saving node using a modified ComfyUI unet merge and the standard simple clip merge tool.
Ingredients;
SimNoob V5 28% densest targeted features
Sim V5 12% densest targeted features
NoobSim 8% densest targeted features
PonySim 40% densest targeted features
Created through interpolation 12% features from the cosine differences;
Average loss per step 21.01~ (higher is better)
Interpolated using STAGE_1 T5 UNCHAINED for 12,000 steps using the features themselves; more than enough to inject the necessary features.
Update:
I later learned that the T5-UNCHAINED at the time wasn’t good, it was basically collapsing unto itself. I was essentially using the T5XXL with occasional bleeds due to the tokenizer.
VPRED capable to extremes.
This is just a peek into the power of this model in the future. The more training it gets, the more powerful it will become. There is seemingly no limit, as long as I stick within the guidelines of the features and the math of the dimensions.
I will be fully capable of distilling much smaller models soon; much quicker responses, and much much more potent power packed in the small space for very specific tasks.
For example;
pixel art
liminal
fashion
anatomy
and more
The concept of distillation is not new, and this is a beautiful outcome from a first experiment.