Touching Grass - IL/NAI







세부 정보
파일 다운로드 (1)
모델 설명
Project: Touching Grass
The best LoRA for grass details.
Sharing merges using this LoRA, re-printing it to other platforms, are prohibited. This model only published on Civitiai and TensorArt. If you see "me" and this sentence in other platforms, all those are fake and the platform you are using is a pirate platform.
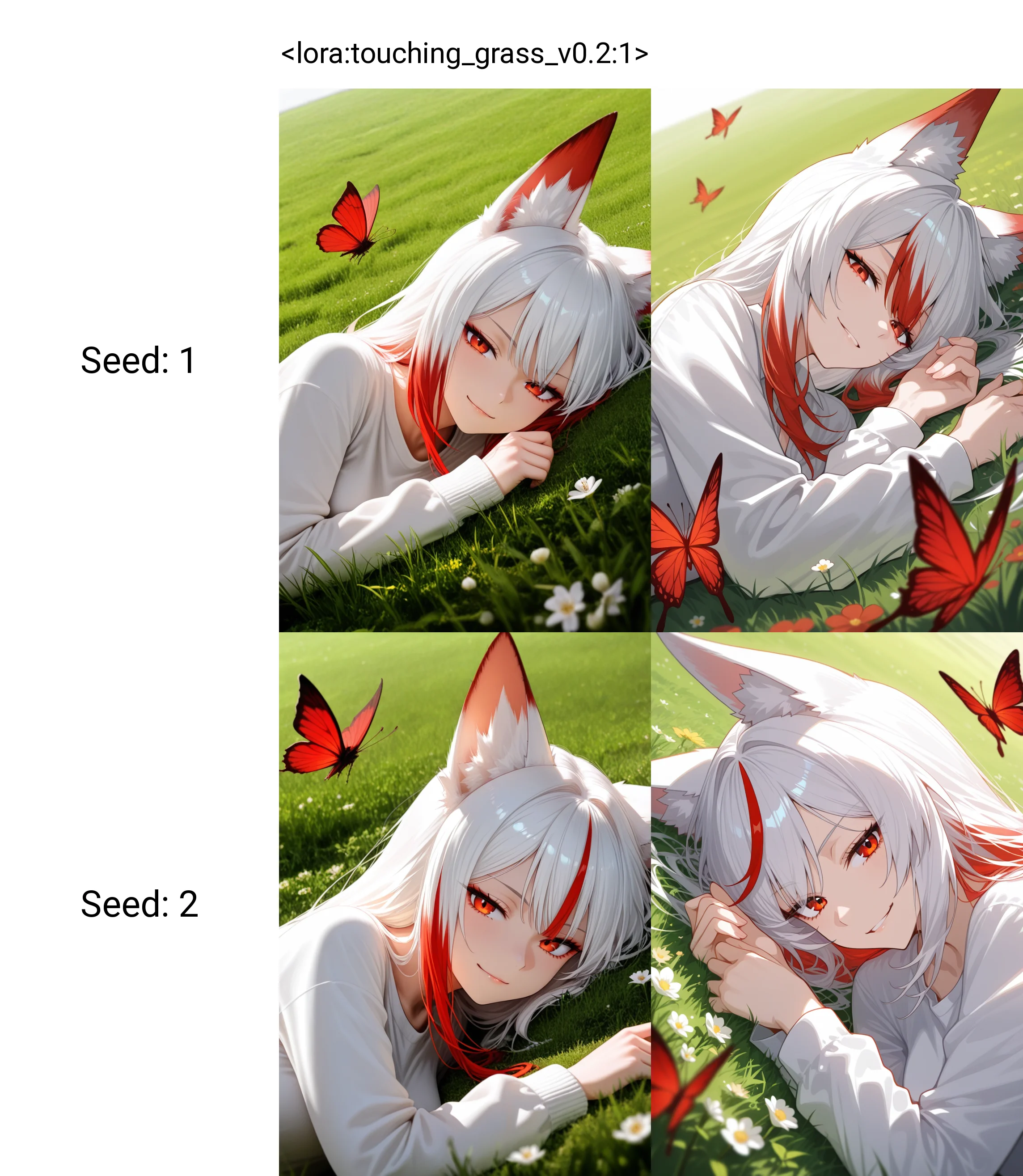
What's the effect?
It really depends on your base model. Here is a quick comparations on WAI v13. This model has very strong AI style (trained on AI images).
With/without.

How to use?
No trigger word needed.
You don't have to set the patch strength for text encoder. This LoRA does not patch it.
Lower your CFG scales (-30%) for better details.
I got realistic faces on my anime characters.
Don't blame this LoRA, it has zero knowledge of realistic faces. Most likely your base model was mixed with other realistic models, probably for better texture and lighting as well.
Share merges using this LoRA is prohibited. FYI, there are hidden trigger words to print invisible watermark. It works well even if the merge strength is 0.05. I coded the watermark and detector myself. I don't want to use it, but I can.
Update log
(4/15/2025) v0.2:
+30% images. Because there is a bug causing all avif files not being used in v0.1. Which is 30% of the dataset. lol.
Changed some parameters. Stronger, cleaner and more stable effect.
(4/02/2025) v0.1: init release.