AmateurTrigger_XL





















詳細
ファイルをダウンロード (1)
このバージョンについて
モデル説明
My biggest project here, I've been working on it for 20 days now, having done several tests.
To sum up, as the name LoRA suggests, I'm going for a very amateur, very candid/homemade look.
It took me a long time to find the technique to master the rendering the way I wanted.
Above all, I didn't want to waste time downloading images one by one. So I programmed a images scraper for a few famous sites where I was sure to find amateur/homemade content. All I had to do was enter the link, and the script was able to download all the images from all the pages.
Then having lot images is great, but you still need quality, I definitely didn't want to make a bunch of rotten images that would have lowered the quality of the training. So I had to design another script to sort through my download folders. Sorting by ‘weight’ “size” and ‘quality’. Once my images had been sorted into their respective folders, all I had to do was return the top tier images to the root folder.
In the end I had 15,000 images downloaded just in fews minutes, and I only kept... 5000 images. But hey, for a LoRA 5000 is a lot.
I still had to do another manual sort after the automatic sort.
Since I absolutely wanted to train my LoRA with 5000 images, I opted for a ‘fine tune’ type of training. LR around 2e-05, network dimension at 96 and alpha at 16. For a total of 11800 steps (trained in 2 times, blue curve is the first one)
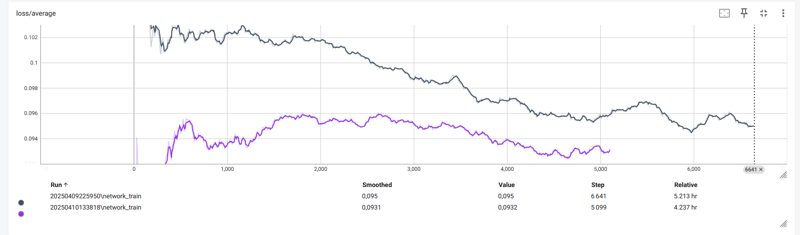
Captioning was done with JoyCaption Alpha 2 (with 5000 images took a long time but it was finished overnight)
All done with the "Descriptive | Medium-length" presets.
Trained with BigLustiMix_rebirth but as usual is still compatible with all models that have a Lustify/BigASP2 base.
I'd recommend keeping strength at around 0.8, as it tends to take up a lot of space on the checkpoint, but that was also my aim, so it's not surprising. Since initially I wanted to do finetune
You'll find the famous noisy, grainy look of images with a fairly low compression rate with fairly basic lighting, often using a phone flash type light source, but without the resolution being compromised, as I didn't train this LoRA with a standard resolution of 1024x1024 but 1216x1216 which allows resolutions a little beyond SDXL's usual standards.
The bodies are also much more natural, and the positions more candid overall. It seems less ‘perfect’.
There aren't really any triggers tokens to know, This LoRA is more like a big DLC than a small mod, I'd just recommend importing the LoRA into a metadata analyzer to find out the most frequent tags. Or use the script I've made