Layer Diffuse with any model ComfyUI Workflow


详情
下载文件 (1)
关于此版本
模型描述
This workflow enables you to generate transparent images with ANY checkpoint architecture that doesn't currently have a trained Layer Diffusion model for it. It doesn't magically make the existing models work with other architectures, but uses some clever tricks to go around these limitations. Contrary to my other work, this workflow is as basic as it gets so that you may incorporate its ideas into your own . Please read about the specifics below.
Dependencies
https://github.com/huchenlei/ComfyUI-layerdiffuse
https://github.com/Fannovel16/comfyui_controlnet_aux
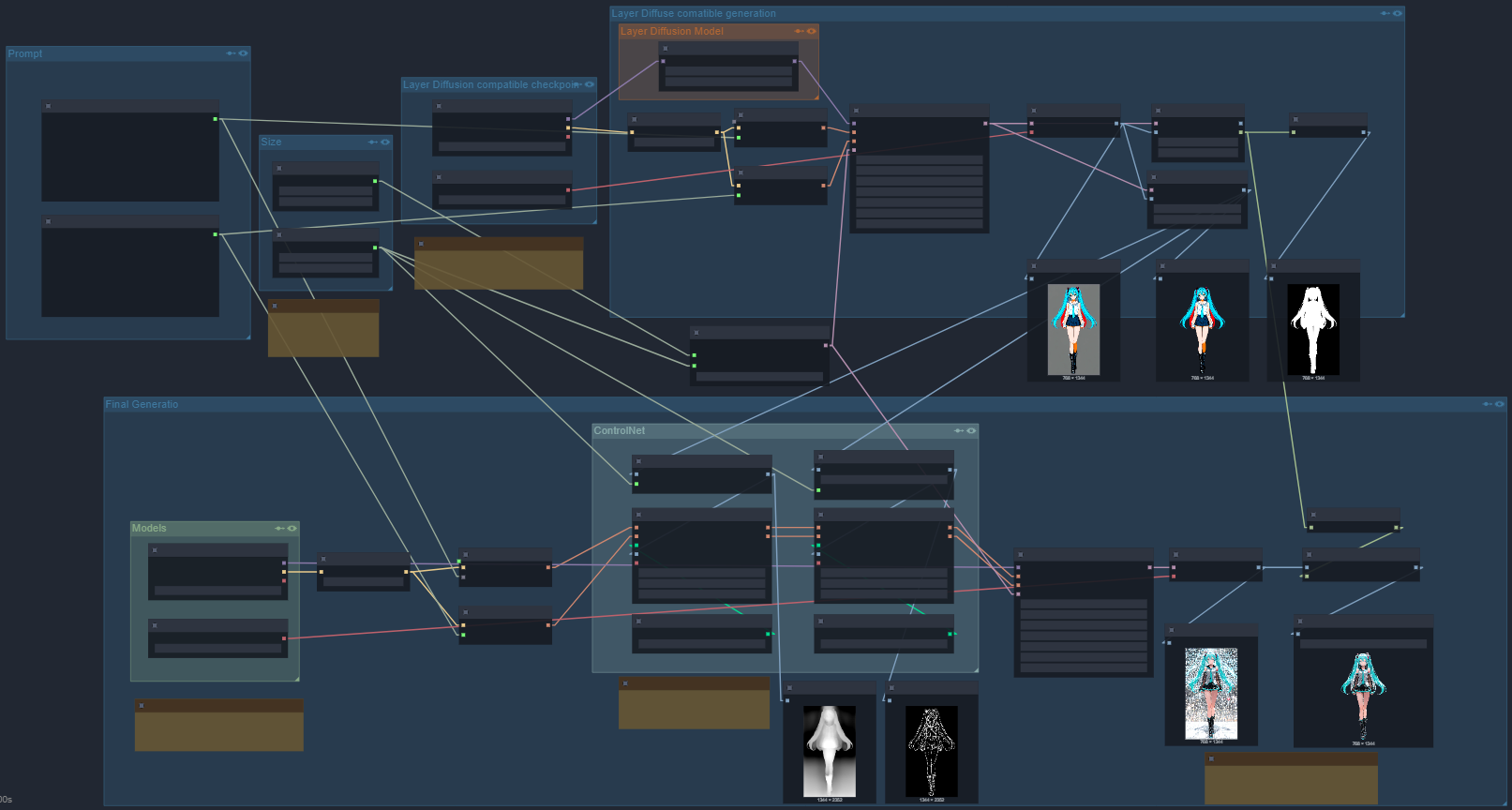
How it's done
First we generate an image with a supported model. At the time of this post those would be SD1.5 and SDXL. Pony works too, but Illustrious/NoobAI do not.
Here's an image generated with a Pony checkpoint and the SDXL Layer Diffusion model applied but before decoding Layer Diffusion (so no transparency yet): After we decode we get a transparent image. CivitAI doesn't really support that but the black here is actually the transparency.
After we decode we get a transparent image. CivitAI doesn't really support that but the black here is actually the transparency. This is still the Pony image, so something you can do without any fancy workflows. We want to generate on a checkpoint that doesn't have a trained Layer Diffusion model.
This is still the Pony image, so something you can do without any fancy workflows. We want to generate on a checkpoint that doesn't have a trained Layer Diffusion model.
So instead of saving this, we take the mask from the Layer Diffuse Decode node: Now we take the very first image we generated and use ControlNet preprocessors to create depth and HED (soft edge) images based on that Pony image before LD decoding (lineart can also be used instead of soft edge):
Now we take the very first image we generated and use ControlNet preprocessors to create depth and HED (soft edge) images based on that Pony image before LD decoding (lineart can also be used instead of soft edge):
 Applying both ControlNets we generate an image with the desired checkpoint that we don't have a Layer Diffusion model for, here an illustrious checkpoint:
Applying both ControlNets we generate an image with the desired checkpoint that we don't have a Layer Diffusion model for, here an illustrious checkpoint: We need to set the ControlNet strengths sufficiently high so that the character stays withing the bounds of the mask from earlier.
We need to set the ControlNet strengths sufficiently high so that the character stays withing the bounds of the mask from earlier.
Now the last step is to crop out the character using that mask: Viola! A transparent background image with Illustrious but without an Illustrious Layer Diffusion model.
Viola! A transparent background image with Illustrious but without an Illustrious Layer Diffusion model.
Checkpoints used:
T-Ponynai3
Aungir
LORA
If you want character loras with this, you might need to have one for both architectures. Same may be the case with pose models, but more se on the one that's earlier in the workflow.
Upscaling
To add upscaling, you'll want to do it before cropping the image. From my tests, you don't need to upscale the mask, it will get scaled automatically (in fact when I tried scaling it, the results were worse). I tested with tiled upscaling and it worked very well.