Lemon Cake - Artist Style (Illustrious)


















Details
Download Files (1)
About this version
Model description
Hi there !
Here is a LoRA attempting to replicate Lemon Cake style.
There is no need for trigger word, but you can add "LemonCake" if you feel like it.
The LoRA is trained to understand several opposing concepts. For your images, you may want to use one from each pair (rather at the start of your prompt).
"greyscale" / "fullcolor" (works well, although the "fullcolor" images may look less like the original style)
"singleframe" / "multiframes" (works sometimes, but very inconsistent)
You also can choose to add "speech bubble", "caption", both, or none. Like in the example images.
Also, you may want to add "censored" and/or "mosaic censorship" in negative tags.
Prompt examples (not in the example images) :
speech bubbles, fullcolor, singleframe, 1girl, mother, solo, transparent clothes, bra, jeans, looking at the camera, smile
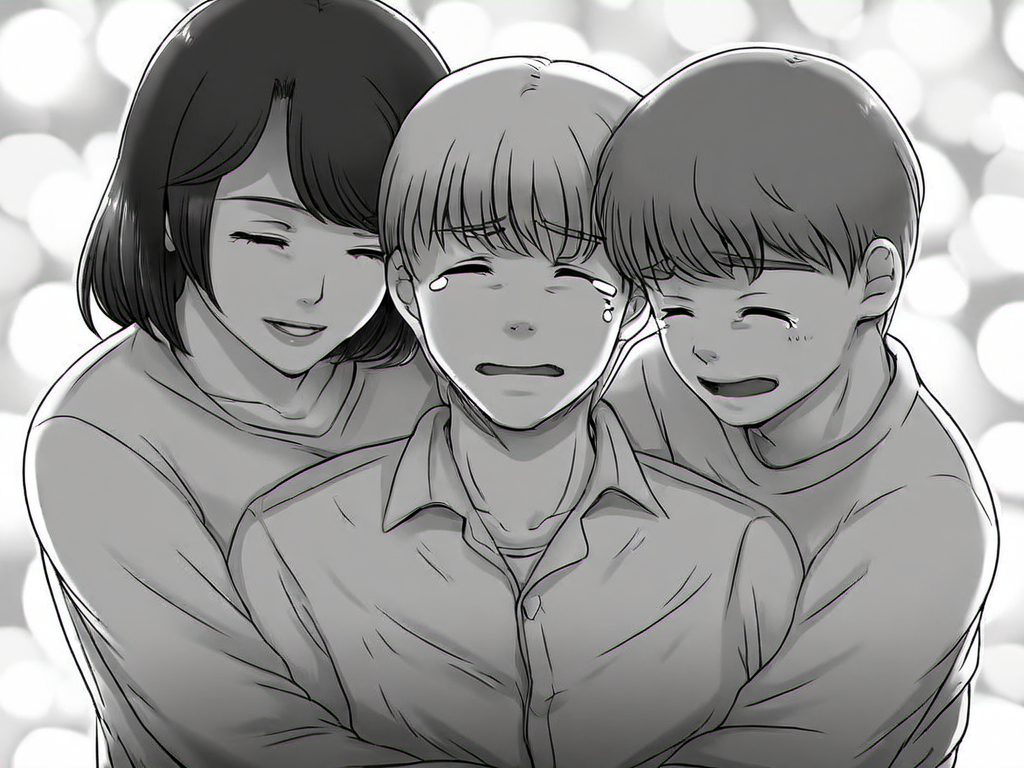
greyscale, singleframe, 1girl, smile, short hair, shirt, closed eyes, tears, 1boy, mole, hug, happy tears, good end, group hug, affectionate, white heart-shaped background
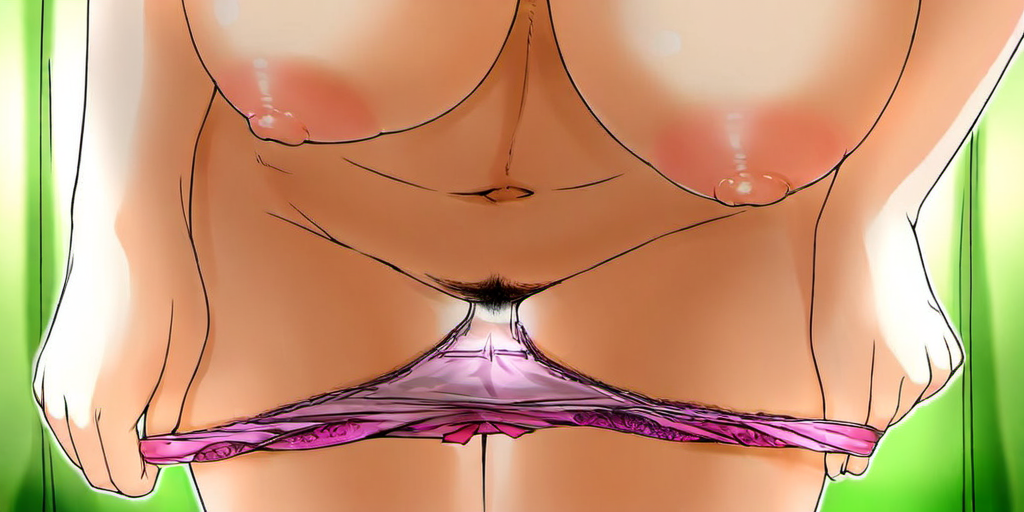
greyscale, multiframes, 1girl, bra, pussy, 1boy, hetero, penis, vaginal sex, bed, missionary, tongue, orgasm, tremble, sweat
All the images in the examples are cherry-picked, but they were generated directly, without ADetailer, impaiting nor anything else. You should get the same images if you use the same parameters.
I did not use regional prompt for the "multiframes" training, so the result will always be quite unpredictable.
The dataset is trained with images of various heights and widths, so feel free to experiment as well. In general, square-shaped images (similar height and width) tend to be more "singleframe" (even though you prompt for "multiframes"), and images with very different height and width tend to be more "multiframe". Sorry, that is not perfect ^^'
Anyway, have fun !