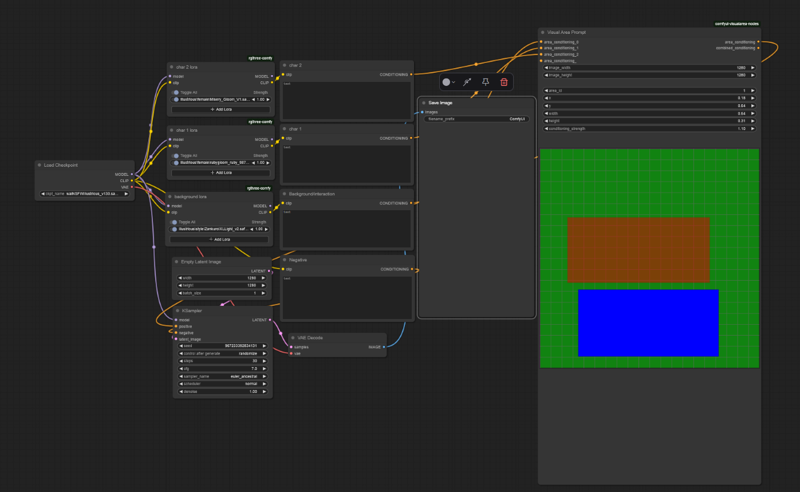
Simple labeled area composition with loras.


详情
下载文件 (1)
关于此版本
模型描述
simply input your desired character traits/loras and background/interactions into the labeled sections, and use visual area prompt to set the postions.
i find that keeping the 2 "character" areas seperate in visual area prompt reduces lora bleed, but you will still need to generate a few pics to get what you want (as is the case with all ai generation)
before you can use it, you will need to use "install missing custom nodes" to get rgthree (for power lora loader) and visual area nodes (for the visualizer.)