HiDream Full GGUF-Q5_K_M UNCENSORED🔞




















Details
Download Files (1)
About this version
Model description
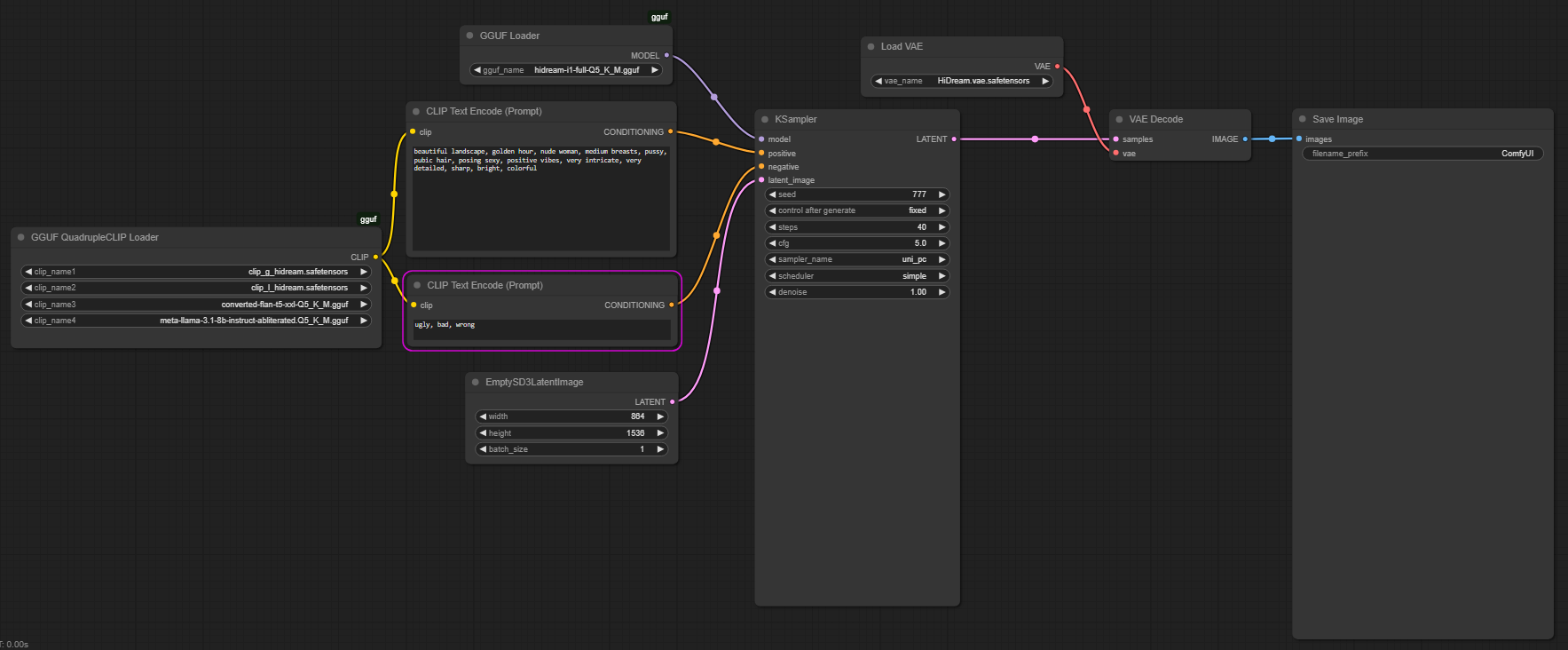
This is the most OPTIMAL (in terms of Quality/Speed|VRAM) quant of the HiDream Full model packed with completely "lobotomized"=uncensored text encoder (Meta Llama 3.1)
This file collection contains two main ingredients that make HiDream way better and !UNcensored:
Nice trick: converted-flan-t5-xxl-Q5_K_M.gguf is used instead of t5-v1_1-xxl-encoder-Q5_K_M.gguf for better text-to-vector translation/encoding;
The main secret ingredient: meta-llama-3.1-8b-instruct-abliterated.Q5_K_M.gguf - instead of Meta-Llama-3.1-8B-Instruct-Q5_K_M.gguf --> Read about the process of LLM abliteration/uncensoring here: https://huggingface.co/blog/mlabonne/abliteration (get other uncensored LLMs from his repos on Huggingface...)
So ... simply do:
Unpack the archive file!
place: hidream-i1-full-Q5_K_M.gguf file in ComfyUI\models\unet folder;
place: converted-flan-t5-xxl-Q5_K_M.gguf, meta-llama-3.1-8b-instruct-abliterated.Q5_K_M.gguf, clip_g_hidream.safetensors, clip_l_hidream.safetensors in ComfyUI\models\text_encoders folder;
place: HiDream.vae.safetensors under ComfyUI\models\vae folder;
use my UNcensored HiDream-Full Workflow.json as starting workflow to test how it works;
in case of VRAM problems - use my VRAM optimized bat file: run_nvidia_gpu_fp8vae.bat to start ComfyUI (put it directly into the ComfyUI folder);
... this way you can have a nice high quality HiDream-Full image generation with 12Gb VRAM (tested!)
Update1: You can also use other uncensored Meta Llama 3.1 versions in text encoder part, for example this image: https://civitai.com/images/71818416 is using DarkIdol-Llama-3.1-8B-Instruct-1.2-Uncensored-GGUF
Update2: Try this CLIP-G --> https://civitai.com/models/1564749?modelVersionId=1773479