XL realistic fursuit





















Details
Download Files (1)
About this version
Model description
这是一个泛化性很强的兽装lora,训练了三种常见的兽装风格(kemono fursuit,realistic fursuit,toony fursuit),可以绘制后视图或仅头部。为了泛化性和改善原始模型效果,同时也进行了许多其它方面的训练。下载时较小的文件是prompt示例。
lora基于Ratatoskr训练因为此模型支持多种风格,但自V8THL后此模型明显训练过度,颜色异常,难以令人接受。因此如果需要更好的色彩和背景结构表现,建议使用此版本。
为了改善原始模型效果,模型也训练了anime风格,厚涂风格,128px像素风格,简单绘画风格,虚拟与现实结合等等,以及尝试改善柴犬的显示效果。
但在具体概念上能分配到的图像并不多,因此有些概念只使用了几张图进行训练,可能需要多次尝试。多样性训练有助于改善过度训练现象,也可能使得在非训练目标上泛化表现更好。
顺带训练了一些角色"猫十三"(cat13),ori,三宝(sanbao),净饭(jingfan),但使用图像不多,这是为了尽量避免概念干扰意外影响模型泛化能力,所以用的不是角色的训练方法。因此这不是一个专门训练角色的模型,特征学习不足,效果不佳。
lora强度建议从0.6开始尝试,即使设置较低也能起效。有些概念可能需要设置的更高,如0.85,设置为1时图像质量会明显下降;有些概念特征明显可能需要设置的较低。
展开查看更多说明 (Machine translation ,Click "Show More" look more instructions)
This is a highly generalized animal suit lora that has trained three common animal suit styles (kemono fursuit,realistic fursuit,toony fursuit), and can be used to draw rear views or just the head. In order to generalize and improve the performance of the original model, many other aspects of training were also carried out. The smaller file when downloading is the prompt example.
lora is trained based on Ratatoskr because this model supports multiple styles. However, since V8THL, this model has been obviously overtrained, with abnormal colors, which is hard to accept. Therefore, if you need better color and background structure presentation, it is recommended to use this version.
To improve the effect of the original model, the model was also trained in anime style, thick coating style, 128px pixel style, simple painting style, virtual and reality combination, etc., and attempts were made to improve the display effect of the Shiba Inu.
However, there are not many images that can be allocated to specific concepts. Therefore, some concepts are only trained with a few images and may require multiple attempts. Diversity training helps improve the phenomenon of overtraining and may also lead to better generalization performance on non-training targets.
Incidentally, some characters such as "cat13", ori, sanbao and jingfan were trained, but not many images were used. This was to avoid conceptual interference from accidentally affecting the model's generalization ability, so the training method used was not that of the characters. Therefore, this is not a model specifically designed for training characters. It has insufficient feature learning and poor performance.
lora strength suggests starting from 0.6. Some concepts may need to be set higher, such as 0.85; When set to 1, the image quality will decline significantly. Some concept features are obvious and may need to be set lower.
展示图像:
 进行了多视图训练(Multi-view training was carried out)
进行了多视图训练(Multi-view training was carried out)
The rear view has few training images and is greatly affected by the base model
(But it won't be drawn if the rear view is not trained.)

进行了仅头部训练(fursuit head)
fursuit head training was carried out

其他概念训练 Other concept training


 角色"猫13"以及泛化能力测试
角色"猫13"以及泛化能力测试
基础提示(注意是yuguo) prompt :
yuguo,digital drawing,anthro cat,red and gold hat,blue eyes,brown fur,
wearing red and blue outfit,kemono furry,
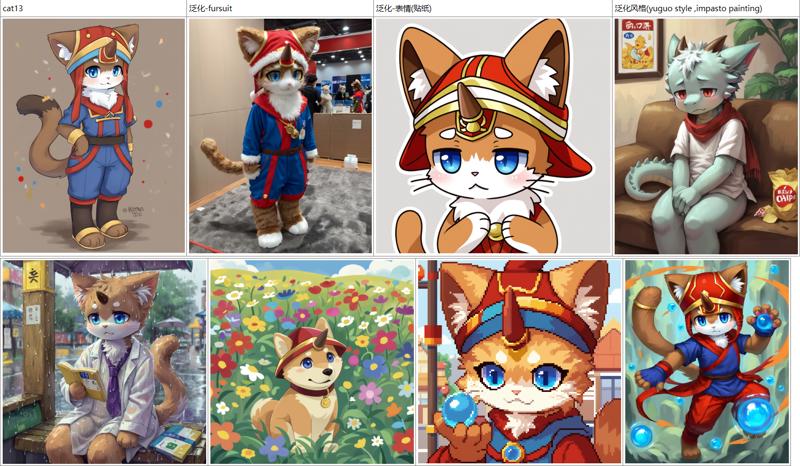
 泛化能力测试(lora可能会干扰原始模型的泛化能力,因此作此实验)
泛化能力测试(lora可能会干扰原始模型的泛化能力,因此作此实验)
Generalization ability test (lora may interfere with the generalization ability of the original model, so this experiment is conducted)

已知问题:
底模Ratatoskr训练存在问题,显示效果不够自然真实,lora虽然能改善一些过度平滑和过度光照的问题,但效果仍然不佳。
会存在不希望出现的光照,绘制不了很暗场景。高cfg可以绘制的更黑,但显示不自然,低cfg或cfg缩放来使画面更自然,但也会降低质量。
可以使用对纯黑图像重绘进行改善。
手部绘制效果不好,lora可能会降低手部绘制质量,这可能是因为fursuit有手有爪以及遮挡关系更加抽象。
数据集不够平衡,有些概念训练过度所以部分过亮是我lora引起的;一些结构质量下降,比如刀绘制有些困难。
有时可以通过降低CLIP强度改善,但是新概念依附于CLIP强度,随着降低会失效,强度太低同样会导致有些图像崩溃。
fursuit概念中蓝色偏多,有时不可控的出现蓝色
因为颜色花纹复杂,有时存在颜色污染,条纹可能难以控制,我不知道该怎么描述奇奇怪怪的毛色和纹理分布。
kemono风格经常对物种不敏感,因为我打标都难以分清物种,这导致龙有时需要自己写上horns。
全身照可能会有些模糊,需要较大尺寸才有足够的毛发细节
可能难以指定内侧毛颜色,如难以绘制白以外的肚皮颜色,因为数据太少以及底模自身也难以做到,此问题在0610之后有所改善。
我进行了一些专门标注尝试改善,但建议手动涂色,使用图生图解决
模型区别:
1006
尝试改善光照,强行降低了一些训练数据的饱和度和亮度,添加一批黑暗环境图像进行训练
添加更多与水互动图像;添加更多图像改善美学;添加更多图像改善半兽装;在一些测试中细节表现比上一版差
082x
V8THL 基于V8THL色彩表现比14.1更好,但也许不如pony。你可以得到更黑的背景,但前景仍然过亮。
Pony 基于Pony realisim作为尝试,多风格表现不佳。但夜晚和色彩表现比14.1更好,可能会更加自然。通过负面填写写实提示,可以引入一些非写实风格,如anime
14.1 基于最新的Ratatoskr14.1但请注意,底模存在色彩和夜晚表现不佳问题。lora似乎会导致此现象更加严重。但你可以发现lora也能用在V8THL上,观感比14.1更好。
添加更多图像训练,尝试一些更精确细致描述
尝试改善肚皮颜色,改善在水中效果
添加了一些doge图片
改善钥匙链,厚涂,简单绘画等一些风格的效果
引入更多分辨率和更高美学质量图像
添加ori,和三相奇谭角色,只是少量训练
但相比之前,现在训练从14轮降低至10轮,可能训练不足
0419
换了一批高质量像素图,有点训练不足;使用标准lora;色彩表现依旧不如0312,可能问题在于底模
0412x:厚涂之类的色彩表现不佳;使用lycoris的locon;使用的像素图质量不高,图像显得凌乱;有些概念过看起来拟合,而有些则欠拟合
0312:训练内容相对较少,但训练了三头六臂概念,这个概念效果不佳所以后续放弃。在厚涂等非写实方面色彩上表现较好;基于V8THLRatatoskr - V8 [THL]
Model difference:
1006
An attempt was made to improve the lighting. The saturation and brightness of some training data were forcibly reduced, and a batch of dark environment images were added for training
Add more interactive images with water; Add more images to improve aesthetics; Add more images to improve the half-beast costume; In some tests, the detail performance was worse than that of the previous version
082x
The V8THL has better color performance than the 14.1, but perhaps not as good as the pony. You can get a darker background, but the foreground is still too bright.
Pony, based on Pony realisim as an attempt, performed poorly in multiple styles. However, the night and color performance are better than 14.1 and might be more natural. By filling in realistic prompts in a negative way, some non-realistic styles can be introduced, such as anime
14.1 is based on the latest Ratatoskr14.1, but please note that the bottom mold has issues with poor color and night performance. lora seems likely to make this phenomenon even more severe. But you can find that lora can also be used on V8THL, and the visual experience is better than 14.1.
Add more image training and try some more precise and detailed descriptions
Try to improve the color of your belly and enhance the effect in water
Some doge pictures have been added
Improve the effects of some styles such as key chains, thick coating, and simple painting
Introduce images with more resolutions and higher aesthetic quality
Add ori and the threefoldrecital Tale character, with only a small amount of training
However, compared to before, the training has now been reduced from 14 rounds to 10 rounds, which might be insufficient
0419:
I replaced a batch of high-quality pixel images, but some of the training was insufficient ; Use standard lora; The color performance is still not as good as that of 0312. The problem might lie in the base mold
0412x:
The color representation is not good; Use lycoris' locon ;The quality of the pixel images used is not high, and the images appear messy ;Some concepts are overfitting, while others are underfitting
0312:
The training content was relatively limited, but the concept of three heads and six arms was trained. However, the effect of this concept was not good, so it was abandoned later. ; It performs well in terms of color in non-realistic aspects such as thick coating ; Based on Ratatoskr - V8 [THL]