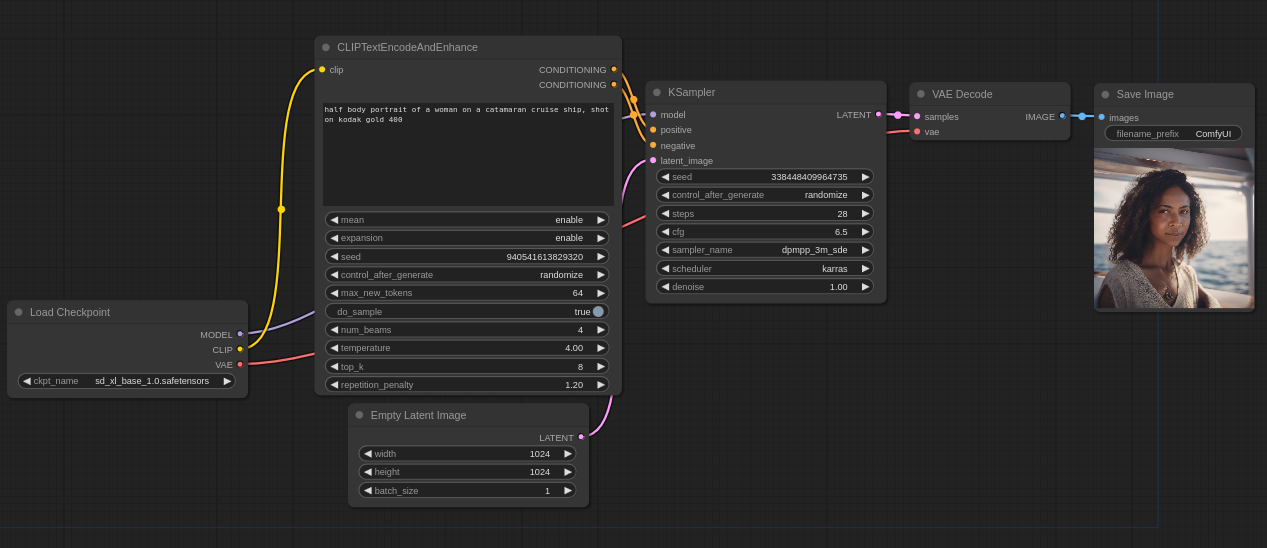
CLIP Text Encode And Enhance





詳細
ファイルをダウンロード (1)
モデル説明
Version 4 updates:
Small code optimizations. Removed angle calculation between prompt vector and contextual vector due to high computational load and low efficiency. Contextual vector can be disabled by setting "mean". Added a second output designed to connect to the "negative" input and containing a vector midway between the prompt vector and the contextual vector.
Version 3 updates:
Note: now, when connecting something via clip, the CFG must be reduced by a factor of 2-2.5 for the connected thing to work properly. Fixed a bug when there are no delimiters in the prompt. Three new settings affecting uniqueness and repeatability of individual words generated by GPT. GPT model replaced by distilgpt2-stable-diffusion-v2 by FredZhang7 (slightly less file weight, slightly more variety). In GPT prompt is passed without stop words (articles, conjunctions, pronouns). At the stage of tensor formation, the vector of the prompt itself and the centered vector multiplied by the cosine of the angle between them are concatenated. In this way, we take into account not only the prompt, but also its context and semantic proximity between them.
Version 2 updates:
Fixed a bug when converting text to input. Added option to disable GPT. Changed default settings. Simplified useless and repetitive string validity checks. GPT is instructed to "Please continue with the descriptive prompt: ". The continuation from GPT is truncated to the last comma to avoid line breaks at the half-word.
Version 1:
Text encoder with some changes to improve the experience of writing prompts.
Introduced new operator ">", similar in functionality to BREAK operator or Cutoff extension. It separates semantic parts of a prompt from each other. For example, "blue hair > green eyes" is more likely to generate blue hair rather than green or blue-green hair. Too many such operators in a prompt can lead to degraded generation quality. A prompt exceeding the limit of 75 tokens can be divided into smaller parts in the same way.
The built-in GPT-2 model helps to write the end of the prompt. For correct work the folder with the model must be in the folder with the node. The model used is gpt2-pt-2-stable-diffusion-prompt-generator from Ar4ikov, but you can change the model to any other or even train it yourself. There are four settings: seed — can be fixed; num_beams — if more than one, the answer is chosen from several generations, it affects the speed a lot; max_new_tokens — maximum number of tokens; do_sample — if True, each next token is chosen on the basis of the previous one.
The size of the text input window is changed by dragging down the lower right corner of the node.
版本 4 更新:
进行了小规模的代码优化。由于计算负载高、效率低,删除了提示向量和上下文向量之间的角度计算。可以通过设置 “mean” 来禁用上下文向量。添加了第二个输出,旨在连接到 “negative” 输入,并包含一个介于提示向量和上下文向量之间的向量。
版本 3 更新:
注意:现在,通过 clip 连接任何东西时,CFG 必须缩小 2-2.5 倍才能正常工作。修正了提示符中没有分隔符时的一个错误。新增了三个影响 GPT 生成的单词的唯一性和可重复性的设置。用来自 FredZhang7 的 distilgpt2-stable-diffusion-v2 替换了 GPT 模型(权重略低,种类略多)。在 GPT 中,提示语是不带停顿词(冠词、连词、代词)的。在张量形成阶段,提示本身的矢量和中心矢量乘以它们之间夹角的余弦值被连接起来。这样,我们不仅考虑了提示语,还考虑了其上下文以及它们之间的语义接近性。
版本 2 更新:
修正了将文本转换为输入法时的一个错误。添加了禁用 GPT 的选项。更改了默认设置。简化了无用和重复的字符串有效性检查。指示 GPT "Please continue with the descriptive prompt: "。来自 GPT 的续行符会被截断到最后一个逗号,以避免在半字处换行。
版本 1:
对文本编码器进行了一些修改,以改善编写提示符的体验。
引入新的运算符">",其功能类似于 BREAK 运算符或截止扩展。它将提示语的语义部分相互分离。例如,"蓝色头发 > 绿色眼睛 "更有可能生成蓝色头发,而不是绿色或蓝绿色头发。提示语中此类运算符过多会导致生成质量下降。超过 75 个提示符限制的提示符也可以用同样的方法分割成更小的部分。
内置的 GPT-2 模型可帮助编写提示符的结尾。为确保正确工作,包含模型的文件夹必须位于节点文件夹中。所使用的模型是来自 Ar4ikov 的 gpt2-pt-2-stable-diffusion-prompt-generator 模型,但你也可以将模型更改为其他任何模型,甚至自行训练。有四种设置:seed — 可以是固定的;num_beams — 如果多于一个,答案将从多代中选择,这对速度影响很大;max_new_tokens — 最大标记数;do_sample — 如果为 True,下一个标记将在前一个标记的基础上选择。
文本输入窗口的大小可以通过向下拖动节点的右下角来改变。
Обновления версии 4:
Небольшие оптимизиации кода. Убрано вычисление угла между вектором промпта и контекстуальным вектором из-за высокой вычислительной нагрузки и низкой эффективности. Контекстуальный вектор можно отключить настройкой "mean". Добавлен второй выход, предназначенный для соединения со входом "negative" и содержащий вектор, находящийся посередине между вектором промпта и контекстуальным вектором.
Обновления версии 3:
Внимание: теперь, при подключении чего-либо через clip, CFG должен быть уменьшен в 2-2,5 раза для нормальной работы подключенного. Исправлен баг при отсутствии разделителей в промпте. Три новых настройки, влияющих на уникальность и повторяемость отдельных слов, генерируемых GPT. GPT модель заменена на distilgpt2-stable-diffusion-v2 от FredZhang7 (чуть меньше весит файл, чуть разнообразней). В GPT передаётся промпт без стоп-слов (артиклей, союзов, местоимений). На этапе формирования тензора происходит конкатенация вектора самого промпта и центрированного вектора, умноженного на косинус угла между ними. Так мы учитываем не только промпт, но и его контекст, а также семантическую близость между ними.
Обновления версии 2:
Исправлен баг при преобразовании текста в инпут. Добавлена возможность отключения GPT. Изменены настройки по умолчанию. Упрощены бесполезные и повторяющиеся проверки валидности строки. GPT получает инструкцию "Please continue with the descriptive prompt: ". Продолжение от GPT обрезается до последней запятой, чтобы избежать обрыва строки на полуслове.
Версия 1:
Текстовый кодировщик с некоторыми изменениями, улучшающими опыт написания промптов.
Введён новый оператор ">", по функционалу похожий на оператор BREAK или расширение Cutoff. Разделяет между собой смысловые части промпта. Например, "синие волосы > зелёные глаза" с большей степенью вероятности приведёт к генерации синих волос, а не зелёных или сине-зелёных. Слишком большое количество таких операторов в промпте может привести к ухудшению качества генераций. Таким же образом можно разделить на более мелкие части промпт, превышающий лимит в 75 токенов.
Встроенная GPT-2 модель помогает дописывать конец промпта. Для корректной работы папка с моделью должна лежать в папке с нодой. Использована модель gpt2-pt-2-stable-diffusion-prompt-generator от Ar4ikov, но вы можете менять модель на любую другую или даже обучить сами. Настройки четыре: seed — можно зафиксировать; num_beams — если больше одного, то ответ выбирается из нескольких генераций, сильно влияет на скорость; max_new_tokens — максимальное количество токенов; do_sample — если True, то каждый следующий токен выбирается на основе предыдущего.
Размер окна ввода текста изменяется путём перетаскивания вниз нижнего правого угла ноды.