FramePack 💎 img2vid / txt2vid with LoRa Workflow - K3NK

詳細
ファイルをダウンロード (1)
このバージョンについて
モデル説明
mmaudio will slow down cuda usage on the consequent generations.. i already git pulled the custom node... nodiff
1.3 is now 1.3.1, i removed GIMMVIF and swapped the sharpen node for another one since those were causing issues with ram
Consider this workflow as a control panel, if you don't like the design, just don't download. Here a screenshot:
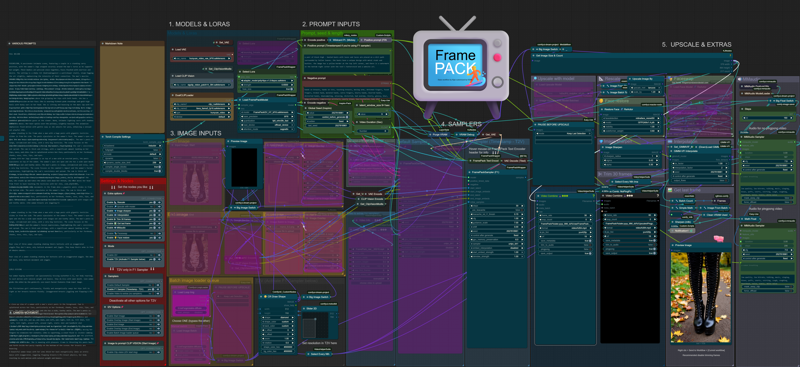
v1.3.1
Updated resize image node
Added batch loader for start image input
Added Video To Extras Option
Added isolated face refiner step
Added MMaudio section (it will load the model to vram)
Added visual resolution/aspect ratio selector for T2V
Changed frame trimming nodes
Removed GIMMVIF interpolationf for film_net_fp32
Sharpen image swaped for sharpen MTB
v1.2.1
added GIMMVIF interpolationn (ds_factor (downscaling) at 0.25 can increase interpolation speed buy with a slightly quality trade-off)
added wildcard process node
Added v1.2
cleaned prompt inputs and model loaders,
added CLIP VISION for helping image details in positive prompt (download)
added vram purge management nodes,
also made external common inputs for length and latent_window_size
Used kijai's workflow, customized and added
upscaler with model and rescaler
interpolation with sharpening
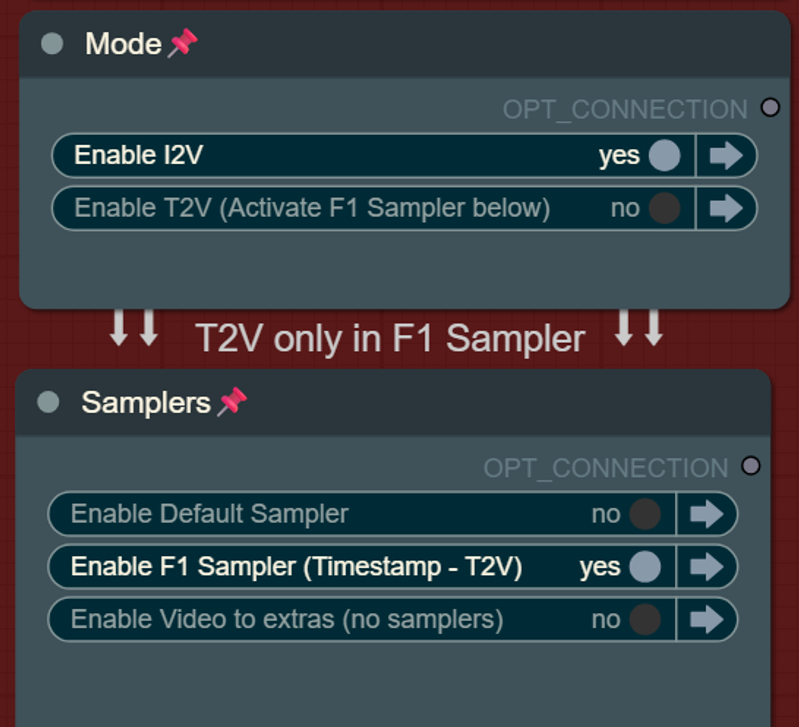
switch from samplers (default or F1)
switch for mode (i2v or t2v)
remove 5 frames (from the start for the non pingpong VHS, and from the start and from the end in the pingponged VSH) this is default at 40 frames for t2v
Reactor nodes for face swap/refine but those will slow down subsequent generations due to some kind of bug, feel free to delete reactor nodes if you feel like it...
Text to video mode with F1 Sampler:
Hover the FramePack Text Encode (Timestamped) (prompt for F1) for seeing more info about the timestamped patterns for prompts:

* Please let me know if im missing any other custom nodes links so i can add them
Also, theres a bug with current wrappers, if you incrase CFG avobe 1 (default) inference time will by x2 slower.. the only way to fix the workflow, even restarting comfy, is to add a fresh sampler and move the connections.. sad but it is what it is..
Nodes:
Latest Kijai Wrapper version: https://github.com/kijai/ComfyUI-FramePackWrapper.git
F1 Sampler https://github.com/kijai/ComfyUI-FramePackWrapper/pull/14/files
You can also use:
https://github.com/ShmuelRonen/ComfyUI-FramePackWrapper_Plus
GIMMVF:
[https://github.com/kijai/ComfyUI-GIMM-VFI] (model with self download)
Model links:
https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/FramePackI2V_HY_fp8_e4m3fn.safetensors
https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/FramePackI2V_HY_bf16.safetensors
sigclip:
https://huggingface.co/Comfy-Org/sigclip_vision_384/tree/main
text encoder and VAE:
https://huggingface.co/Comfy-Org/HunyuanVideo_repackaged/tree/main/split_files
----